 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Aggregated Attention and Transformer Architecture for Accurate and Efficient Performance of Spiking Neural Networks
Dec 18, 2024Spiking Neural Networks have attracted significant attention in recent years due to their distinctive low-power characteristics. Meanwhile, Transformer models, known for their powerful self-attention mechanisms and parallel processing capabilities, have demonstrated exceptional performance across various domains, including natural language processing and computer vision. Despite the significant advantages of both SNNs and Transformers, directly combining the low-power benefits of SNNs with the high performance of Transformers remains challenging. Specifically, while the sparse computing mode of SNNs contributes to reduced energy consumption, traditional attention mechanisms depend on dense matrix computations and complex softmax operations. This reliance poses significant challenges for effective execution in low-power scenarios. Given the tremendous success of Transformers in deep learning, it is a necessary step to explore the integration of SNNs and Transformers to harness the strengths of both. In this paper, we propose a novel model architecture, Spike Aggregation Transformer (SAFormer), that integrates the low-power characteristics of SNNs with the high-performance advantages of Transformer models. The core contribution of SAFormer lies in the design of the Spike Aggregated Self-Attention (SASA) mechanism, which significantly simplifies the computation process by calculating attention weights using only the spike matrices query and key, thereby effectively reducing energy consumption. Additionally, we introduce a Depthwise Convolution Module (DWC) to enhance the feature extraction capabilities, further improving overall accuracy. We evaluated and demonstrated that SAFormer outperforms state-of-the-art SNNs in both accuracy and energy consumption, highlighting its significant advantages in low-power and high-performance computing.
An analysis of full-size Russian complexly NER labelled corpus of Internet user reviews on the drugs based on deep learning and language neural nets
Apr 30, 2021
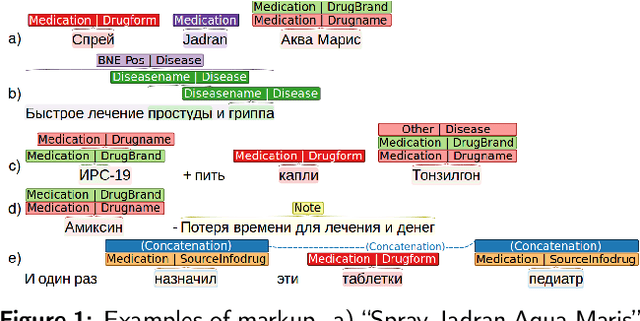
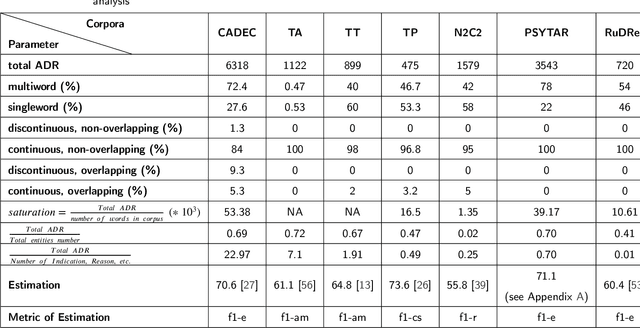
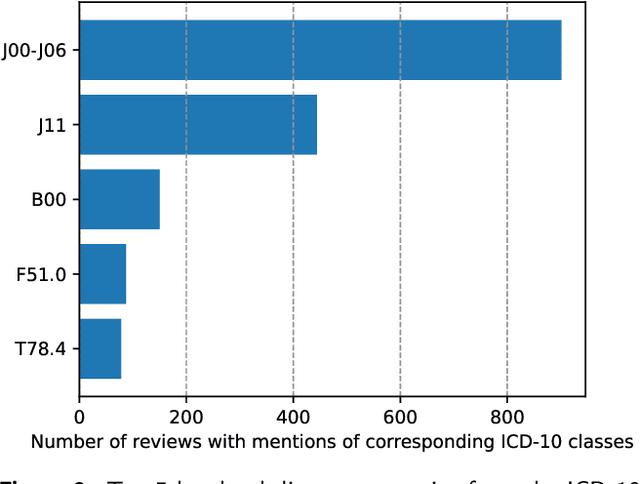
We present the full-size Russian complexly NER-labeled corpus of Internet user reviews, along with an evaluation of accuracy levels reached on this corpus by a set of advanced deep learning neural networks to extract the pharmacologically meaningful entities from Russian texts. The corpus annotation includes mentions of the following entities: Medication (33005 mentions), Adverse Drug Reaction (1778), Disease (17403), and Note (4490). Two of them - Medication and Disease - comprise a set of attributes. A part of the corpus has the coreference annotation with 1560 coreference chains in 300 documents. Special multi-label model based on a language model and the set of features is developed, appropriate for presented corpus labeling. The influence of the choice of different modifications of the models: word vector representations, types of language models pre-trained for Russian, text normalization styles, and other preliminary processing are analyzed. The sufficient size of our corpus allows to study the effects of particularities of corpus labeling and balancing entities in the corpus. As a result, the state of the art for the pharmacological entity extraction problem for Russian is established on a full-size labeled corpus. In case of the adverse drug reaction (ADR) recognition, it is 61.1 by the F1-exact metric that, as our analysis shows, is on par with the accuracy level for other language corpora with similar characteristics and the ADR representativnes. The evaluated baseline precision of coreference relation extraction on the corpus is 71, that is higher the results reached on other Russian corpora.