 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Motif-aware Graph Learning for Phrase Grounding
Paper and Code
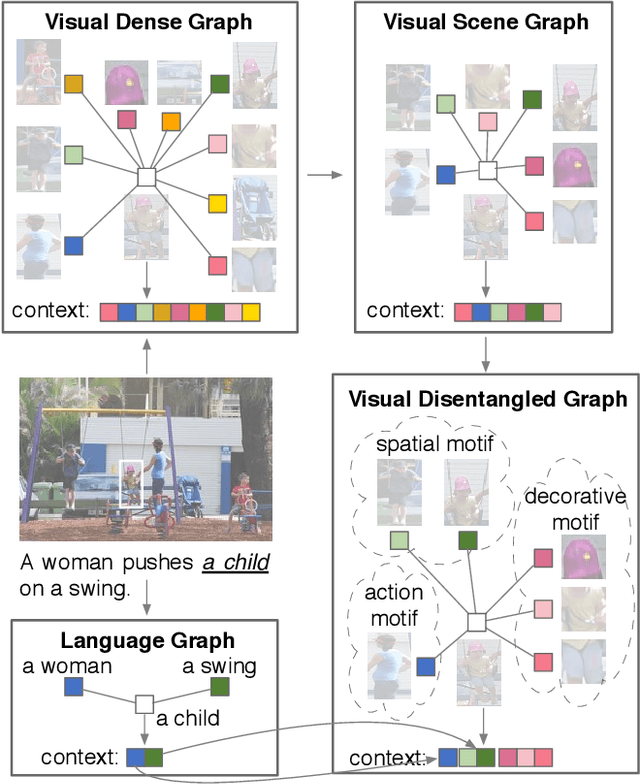
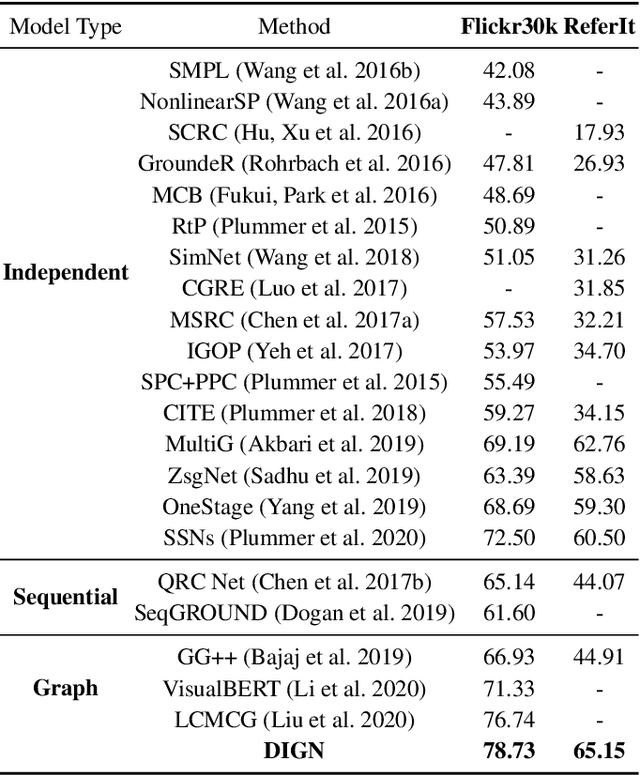
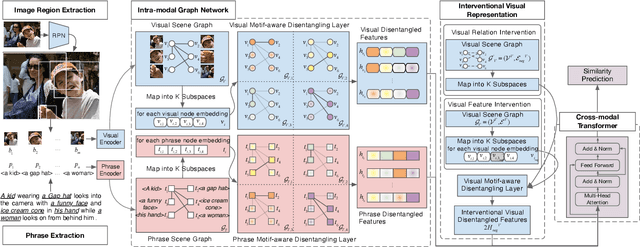

In this paper, we propose a novel graph learning framework for phrase grounding in the image. Developing from the sequential to the dense graph model, existing works capture coarse-grained context but fail to distinguish the diversity of context among phrases and image regions. In contrast, we pay special attention to different motifs implied in the context of the scene graph and devise the disentangled graph network to integrate the motif-aware contextual information into representations. Besides, we adopt interventional strategies at the feature and the structure levels to consolidate and generalize representations. Finally, the cross-modal attention network is utilized to fuse intra-modal features, where each phrase can be computed similarity with regions to select the best-grounded one. We validate the efficiency of disentangled and interventional graph network (DIGN) through a series of ablation studies, and our model achieves state-of-the-art performance on Flickr30K Entities and ReferIt Game benchmarks.