 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Tuning with Soft Context Sharing for Vision-Language Models
Paper and Code
Aug 29, 2022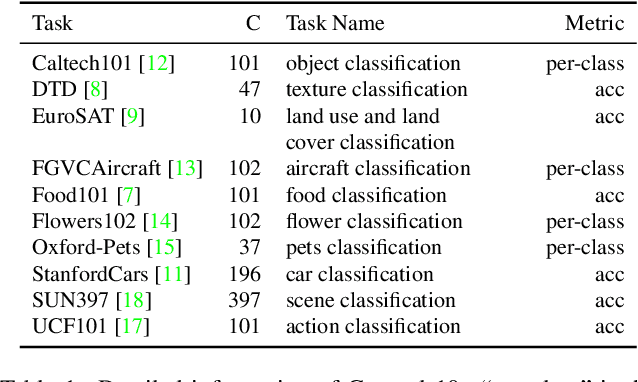
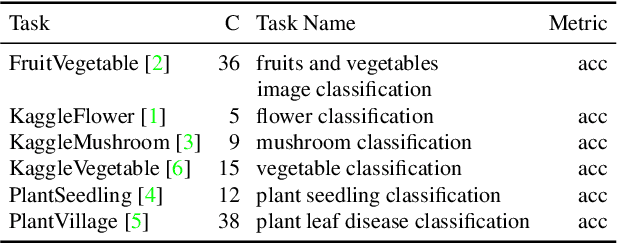

Vision-language models have recently shown great potential on many computer vision tasks. Meanwhile, prior work demonstrates prompt tuning designed for vision-language models could acquire superior performance on few-shot image recognition compared to linear probe, a strong baseline. In real-world applications, many few-shot tasks are correlated, particularly in a specialized area. However, such information is ignored by previous work. Inspired by the fact that modeling task relationships by multi-task learning can usually boost performance, we propose a novel method SoftCPT (Soft Context Sharing for Prompt Tuning) to fine-tune pre-trained vision-language models on multiple target few-shot tasks, simultaneously. Specifically, we design a task-shared meta network to generate prompt vector for each task using pre-defined task name together with a learnable meta prompt as input. As such, the prompt vectors of all tasks will be shared in a soft manner. The parameters of this shared meta network as well as the meta prompt vector are tuned on the joint training set of all target tasks. Extensive experiments on three multi-task few-shot datasets show that SoftCPT outperforms the representative single-task prompt tuning method CoOp [78] by a large margin, implying the effectiveness of multi-task learning in vision-language prompt tuning. The source code and data will be made publicly available.