 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Cache Model for Few-Shot Vision-Language Model Adaptation
Paper and Code
Oct 11, 2024
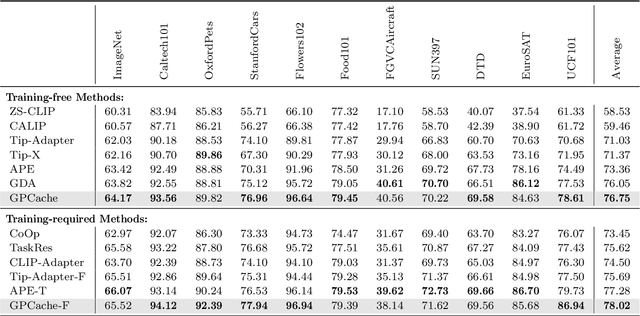
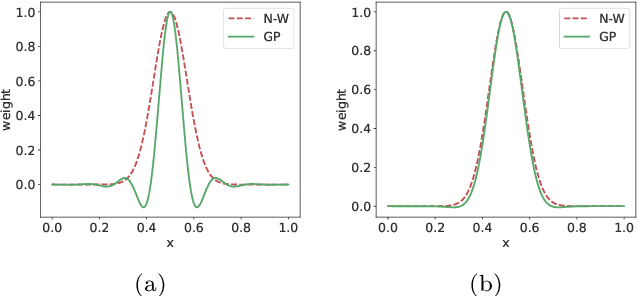
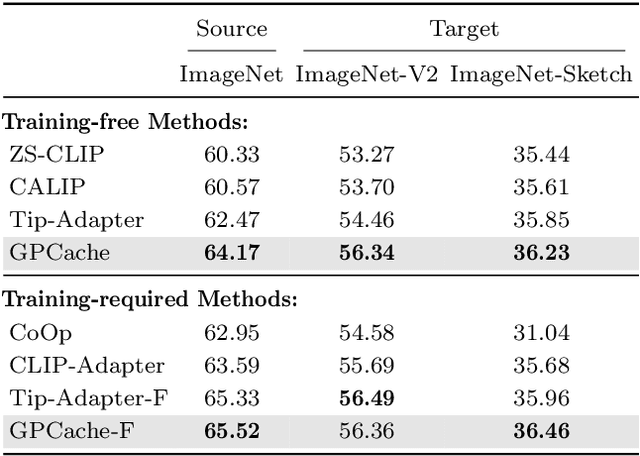
Cache-based approaches stand out as both effective and efficient for adapting vision-language models (VLMs). Nonetheless, the existing cache model overlooks three crucial aspects. 1) Pre-trained VLMs are mainly optimized for image-text similarity, neglecting the importance of image-image similarity, leading to a gap between pre-training and adaptation. 2) The current cache model is based on the Nadaraya-Watson (N-W) estimator, which disregards the intricate relationships among training samples while constructing weight function. 3) Under the condition of limited samples, the logits generated by cache model are of high uncertainty, directly using these logits without accounting for the confidence could be problematic. This work presents three calibration modules aimed at addressing the above challenges. Similarity Calibration refines the image-image similarity by using unlabeled images. We add a learnable projection layer with residual connection on top of the pre-trained image encoder of CLIP and optimize the parameters by minimizing self-supervised contrastive loss. Weight Calibration introduces a precision matrix into the weight function to adequately model the relation between training samples, transforming the existing cache model to a Gaussian Process (GP) regressor, which could be more accurate than N-W estimator. Confidence Calibration leverages the predictive variances computed by GP Regression to dynamically re-scale the logits of cache model, ensuring that the cache model's outputs are appropriately adjusted based on their confidence levels. Besides, to reduce the high complexity of GPs, we further propose a group-based learning strategy. Integrating the above designs, we propose both training-free and training-required variants. Extensive experiments on 11 few-shot classification datasets validate that the proposed methods can achieve state-of-the-art performance.