 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Domain Adaptation from Foundation Models
Paper and Code
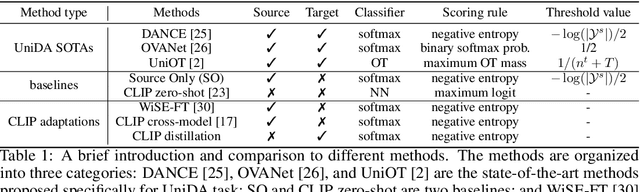
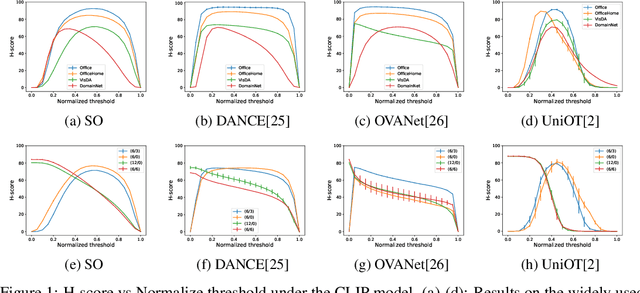
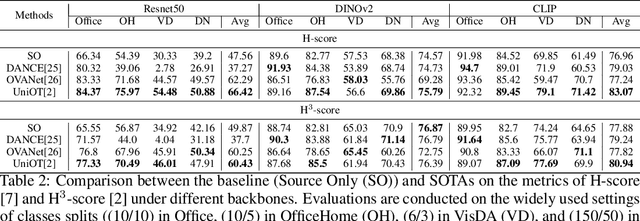
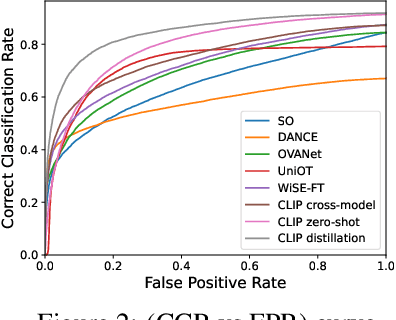
Foundation models (e.g., CLIP or DINOv2) have shown their impressive learning and transferring capabilities on a wide range of visual tasks, by training on a large corpus of data and adapting to specific downstream tasks. It is, however, interesting that foundation models have not been fully explored for universal domain adaptation (UniDA), which is to learn models using labeled data in a source domain and unlabeled data in a target one, such that the learned models can successfully adapt to the target data. In this paper, we make comprehensive empirical studies of state-of-the-art UniDA methods using foundation models. We first demonstrate that, while foundation models greatly improve the performance of the baseline methods that train the models on the source data alone, existing UniDA methods generally fail to improve over the baseline. This suggests that new research efforts are very necessary for UniDA using foundation models. To this end, we propose a very simple method of target data distillation on the CLIP model, and achieves consistent improvement over the baseline across all the UniDA benchmarks. Our studies are under a newly proposed evaluation metric of universal classification rate (UCR), which is threshold- and ratio-free and addresses the threshold-sensitive issue encountered when using the existing H-score metric.