 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Universal Black-Box Domain Adaptation
Paper and Code
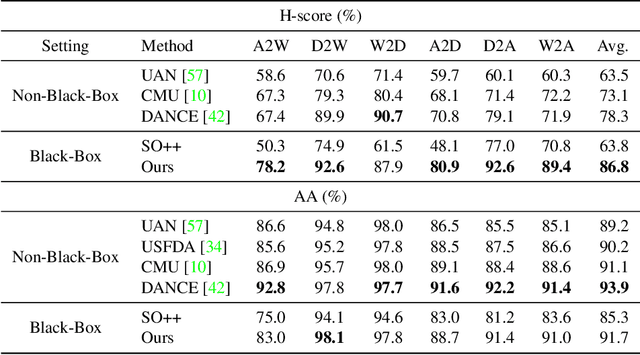



In this paper, we study an arguably least restrictive setting of domain adaptation in a sense of practical deployment, where only the interface of source model is available to the target domain, and where the label-space relations between the two domains are allowed to be different and unknown. We term such a setting as Universal Black-Box Domain Adaptation (UB$^2$DA). The great promise that UB$^2$DA makes, however, brings significant learning challenges, since domain adaptation can only rely on the predictions of unlabeled target data in a partially overlapped label space, by accessing the interface of source model. To tackle the challenges, we first note that the learning task can be converted as two subtasks of in-class\footnote{In this paper we use in-class (out-class) to describe the classes observed (not observed) in the source black-box model.} discrimination and out-class detection, which can be respectively learned by model distillation and entropy separation. We propose to unify them into a self-training framework, regularized by consistency of predictions in local neighborhoods of target samples. Our framework is simple, robust, and easy to be optimized. Experiments on domain adaptation benchmarks show its efficacy. Notably, by accessing the interface of source model only, our framework outperforms existing methods of universal domain adaptation that make use of source data and/or source models, with a newly proposed (and arguably more reasonable) metric of H-score, and performs on par with them with the metric of averaged class accuracy.