 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Literature Review and Framework for Human Evaluation of Generative Large Language Models in Healthcare
May 04, 2024As generative artificial intelligence (AI), particularly Large Language Models (LLMs), continues to permeate healthcare, it remains crucial to supplement traditional automated evaluations with human expert evaluation. Understanding and evaluating the generated texts is vital for ensuring safety, reliability, and effectiveness. However, the cumbersome, time-consuming, and non-standardized nature of human evaluation presents significant obstacles to the widespread adoption of LLMs in practice. This study reviews existing literature on human evaluation methodologies for LLMs within healthcare. We highlight a notable need for a standardized and consistent human evaluation approach. Our extensive literature search, adhering to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, spans publications from January 2018 to February 2024. This review provides a comprehensive overview of the human evaluation approaches used in diverse healthcare applications.This analysis examines the human evaluation of LLMs across various medical specialties, addressing factors such as evaluation dimensions, sample types, and sizes, the selection and recruitment of evaluators, frameworks and metrics, the evaluation process, and statistical analysis of the results. Drawing from diverse evaluation strategies highlighted in these studies, we propose a comprehensive and practical framework for human evaluation of generative LLMs, named QUEST: Quality of Information, Understanding and Reasoning, Expression Style and Persona, Safety and Harm, and Trust and Confidence. This framework aims to improve the reliability, generalizability, and applicability of human evaluation of generative LLMs in different healthcare applications by defining clear evaluation dimensions and offering detailed guidelines.
Automated Fidelity Assessment for Strategy Training in Inpatient Rehabilitation using Natural Language Processing
Sep 14, 2022
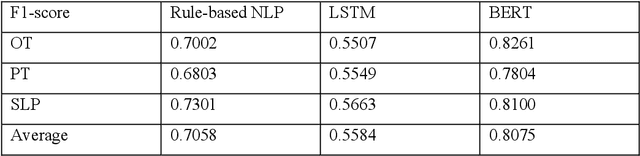
Strategy training is a multidisciplinary rehabilitation approach that teaches skills to reduce disability among those with cognitive impairments following a stroke. Strategy training has been shown in randomized, controlled clinical trials to be a more feasible and efficacious intervention for promoting independence than traditional rehabilitation approaches. A standardized fidelity assessment is used to measure adherence to treatment principles by examining guided and directed verbal cues in video recordings of rehabilitation sessions. Although the fidelity assessment for detecting guided and directed verbal cues is valid and feasible for single-site studies, it can become labor intensive, time consuming, and expensive in large, multi-site pragmatic trials. To address this challenge to widespread strategy training implementation, we leveraged natural language processing (NLP) techniques to automate the strategy training fidelity assessment, i.e., to automatically identify guided and directed verbal cues from video recordings of rehabilitation sessions. We developed a rule-based NLP algorithm, a long-short term memory (LSTM) model, and a bidirectional encoder representation from transformers (BERT) model for this task. The best performance was achieved by the BERT model with a 0.8075 F1-score. The findings from this study hold widespread promise in psychology and rehabilitation intervention research and practice.