 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking LLM-as-a-Judge: Representation-as-a-Judge with Small Language Models via Semantic Capacity Asymmetry
Jan 30, 2026Large language models (LLMs) are widely used as reference-free evaluators via prompting, but this "LLM-as-a-Judge" paradigm is costly, opaque, and sensitive to prompt design. In this work, we investigate whether smaller models can serve as efficient evaluators by leveraging internal representations instead of surface generation. We uncover a consistent empirical pattern: small LMs, despite with weak generative ability, encode rich evaluative signals in their hidden states. This motivates us to propose the Semantic Capacity Asymmetry Hypothesis: evaluation requires significantly less semantic capacity than generation and can be grounded in intermediate representations, suggesting that evaluation does not necessarily need to rely on large-scale generative models but can instead leverage latent features from smaller ones. Our findings motivate a paradigm shift from LLM-as-a-Judge to Representation-as-a-Judge, a decoding-free evaluation strategy that probes internal model structure rather than relying on prompted output. We instantiate this paradigm through INSPECTOR, a probing-based framework that predicts aspect-level evaluation scores from small model representations. Experiments on reasoning benchmarks (GSM8K, MATH, GPQA) show that INSPECTOR substantially outperforms prompting-based small LMs and closely approximates full LLM judges, while offering a more efficient, reliable, and interpretable alternative for scalable evaluation.
Retrieval--Reasoning Processes for Multi-hop Question Answering: A Four-Axis Design Framework and Empirical Trends
Jan 02, 2026Multi-hop question answering (QA) requires systems to iteratively retrieve evidence and reason across multiple hops. While recent RAG and agentic methods report strong results, the underlying retrieval--reasoning \emph{process} is often left implicit, making procedural choices hard to compare across model families. This survey takes the execution procedure as the unit of analysis and introduces a four-axis framework covering (A) overall execution plan, (B) index structure, (C) next-step control (strategies and triggers), and (D) stop/continue criteria. Using this schema, we map representative multi-hop QA systems and synthesize reported ablations and tendencies on standard benchmarks (e.g., HotpotQA, 2WikiMultiHopQA, MuSiQue), highlighting recurring trade-offs among effectiveness, efficiency, and evidence faithfulness. We conclude with open challenges for retrieval--reasoning agents, including structure-aware planning, transferable control policies, and robust stopping under distribution shift.
Curriculum Guided Reinforcement Learning for Efficient Multi Hop Retrieval Augmented Generation
May 23, 2025Retrieval-augmented generation (RAG) grounds large language models (LLMs) in up-to-date external evidence, yet existing multi-hop RAG pipelines still issue redundant subqueries, explore too shallowly, or wander through overly long search chains. We introduce EVO-RAG, a curriculum-guided reinforcement learning framework that evolves a query-rewriting agent from broad early-stage exploration to concise late-stage refinement. EVO-RAG couples a seven-factor, step-level reward vector (covering relevance, redundancy, efficiency, and answer correctness) with a time-varying scheduler that reweights these signals as the episode unfolds. The agent is trained with Direct Preference Optimization over a multi-head reward model, enabling it to learn when to search, backtrack, answer, or refuse. Across four multi-hop QA benchmarks (HotpotQA, 2WikiMultiHopQA, MuSiQue, and Bamboogle), EVO-RAG boosts Exact Match by up to 4.6 points over strong RAG baselines while trimming average retrieval depth by 15 %. Ablation studies confirm the complementary roles of curriculum staging and dynamic reward scheduling. EVO-RAG thus offers a general recipe for building reliable, cost-effective multi-hop RAG systems.
Memory-Aware and Uncertainty-Guided Retrieval for Multi-Hop Question Answering
Mar 29, 2025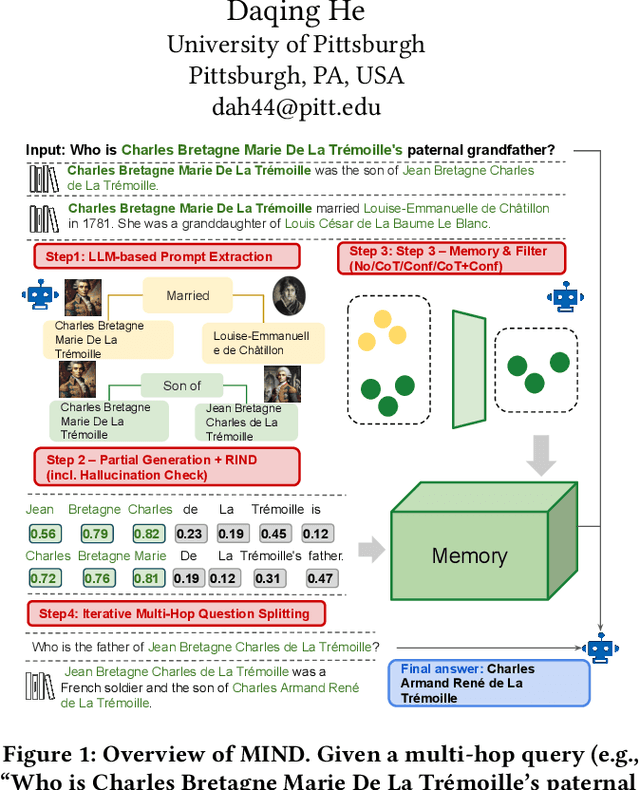



Multi-hop question answering (QA) requires models to retrieve and reason over multiple pieces of evidence. While Retrieval-Augmented Generation (RAG) has made progress in this area, existing methods often suffer from two key limitations: (1) fixed or overly frequent retrieval steps, and (2) ineffective use of previously retrieved knowledge. We propose MIND (Memory-Informed and INteractive Dynamic RAG), a framework that addresses these challenges through: (i) prompt-based entity extraction to identify reasoning-relevant elements, (ii) dynamic retrieval triggering based on token-level entropy and attention signals, and (iii) memory-aware filtering, which stores high-confidence facts across reasoning steps to enable consistent multi-hop generation.
Learning from Committee: Reasoning Distillation from a Mixture of Teachers with Peer-Review
Oct 16, 2024



While reasoning capabilities typically emerge in large language models (LLMs) with tens of billions of parameters, recent research focuses on improving smaller open-source models through knowledge distillation (KD) from commercial LLMs. However, many of these studies rely solely on responses from a single LLM as the gold rationale, unlike the natural human learning process, which involves understanding both the correct answers and the reasons behind mistakes. In this paper, we introduce a novel Fault-Aware Distillation via Peer-Review (FAIR) approach: 1) Instead of merely obtaining gold rationales from teachers, our method asks teachers to identify and explain the student's mistakes, providing customized instruction learning data. 2) We design a simulated peer-review process between teacher LLMs, which selects only the generated rationales above the acceptance threshold. This reduces the chance of teachers guessing correctly with flawed rationale, improving instructional data quality. Comprehensive experiments and analysis on mathematical, commonsense, and logical reasoning tasks demonstrate the effectiveness of our method.
Mitigating the Risk of Health Inequity Exacerbated by Large Language Models
Oct 14, 2024Recent advancements in large language models have demonstrated their potential in numerous medical applications, particularly in automating clinical trial matching for translational research and enhancing medical question answering for clinical decision support. However, our study shows that incorporating non decisive sociodemographic factors such as race, sex, income level, LGBT+ status, homelessness, illiteracy, disability, and unemployment into the input of LLMs can lead to incorrect and harmful outputs for these populations. These discrepancies risk exacerbating existing health disparities if LLMs are widely adopted in healthcare. To address this issue, we introduce EquityGuard, a novel framework designed to detect and mitigate the risk of health inequities in LLM based medical applications. Our evaluation demonstrates its efficacy in promoting equitable outcomes across diverse populations.
Enhancing Equity in Large Language Models for Medical Applications
Oct 07, 2024Recent advancements have highlighted the potential of large language models (LLMs) in medical applications, notably in automating Clinical Trial Matching for translational research and providing medical question-answering for clinical decision support. However, our study reveals significant inequities in the use of LLMs, particularly for individuals from specific racial, gender, and underrepresented groups influenced by social determinants of health. These disparities could worsen existing health inequities if LLMs are broadly adopted in healthcare. To address this, we propose and evaluate a novel framework, EquityGuard, designed to detect and mitigate biases in LLM-based medical applications. EquityGuard incorporates a Bias Detection Mechanism capable of identifying and correcting unfair predictions, thus enhancing outcomes and promoting equity across diverse population groups.
ReasoningRank: Teaching Student Models to Rank through Reasoning-Based Knowledge Distillation
Oct 07, 2024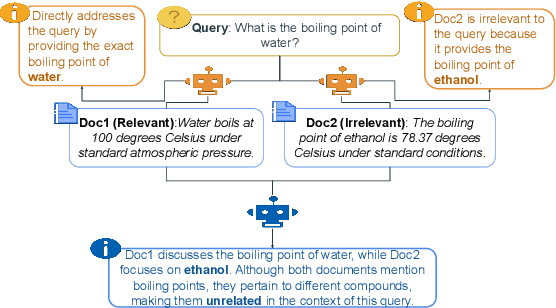
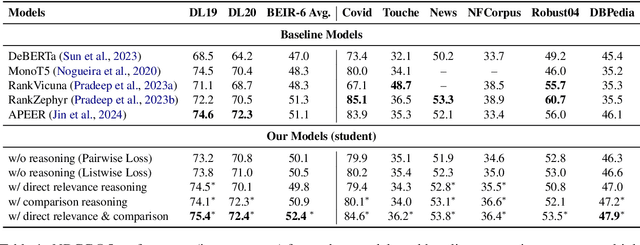

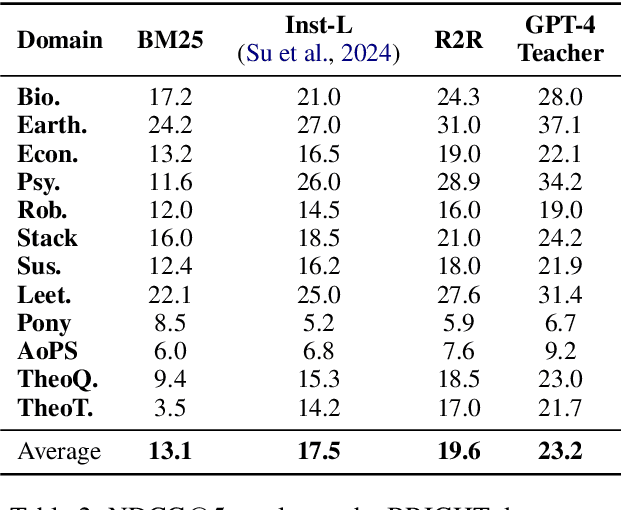
Reranking documents based on their relevance to a given query is critical in information retrieval. Traditional reranking methods often focus on improving the initial rankings but lack transparency, failing to explain why one document is ranked higher. In this paper, we introduce ReasoningRank, a novel reranking approach that enhances clarity by generating two types of reasoning: explicit reasoning, which explains how a document addresses the query, and comparison reasoning, which justifies the relevance of one document over another. We leverage large language models (LLMs) as teacher models to generate these explanations and distill this knowledge into smaller, more resource-efficient student models. While the student models may not outperform LLMs in speed, they significantly reduce the computational burden by requiring fewer resources, making them more suitable for large-scale or resource-constrained settings. These student models are trained to both generate meaningful reasoning and rerank documents, achieving competitive performance across multiple datasets, including MSMARCO and BRIGHT. Experiments demonstrate that ReasoningRank improves reranking accuracy and provides valuable insights into the decision-making process, offering a structured and interpretable solution for reranking tasks.
Enhance Reasoning by Learning from Mistakes: Peer-Review Knowledge Distillation from Multiple Large Language Models
Oct 04, 2024Large language models (LLMs) have exhibited complex reasoning abilities by generating question rationales and demonstrated exceptional performance in natural language processing (NLP) tasks. However, these reasoning capabilities generally emerge in models with tens of billions of parameters, creating significant computational challenges for real-world deployment. Recent research has concentrated on improving open-source smaller models through knowledge distillation (KD) from commercial LLMs. Nevertheless, most of these studies rely solely on the responses from one single LLM as the gold rationale for training. In this paper, we introduce a novel Mistake-Aware Peer-Review Distillation (MAPD) approach: 1) Instead of merely obtaining gold rationales from teachers, our method asks teachers to identify and explain the student's mistakes, providing customized instruction learning data. 2) We design a simulated peer-review process between teacher LLMs, which selects only the generated rationales above the acceptance threshold. This reduces the chance of teachers guessing correctly with flawed rationale, improving instructional data quality. Comprehensive experiments and analysis on mathematical, commonsense, and logical reasoning tasks demonstrate the effectiveness of our method.
RAG-RLRC-LaySum at BioLaySumm: Integrating Retrieval-Augmented Generation and Readability Control for Layman Summarization of Biomedical Texts
May 21, 2024This paper introduces the RAG-RLRC-LaySum framework, designed to make complex biomedical research understandable to laymen through advanced Natural Language Processing (NLP) techniques. Our Retrieval Augmented Generation (RAG) solution, enhanced by a reranking method, utilizes multiple knowledge sources to ensure the precision and pertinence of lay summaries. Additionally, our Reinforcement Learning for Readability Control (RLRC) strategy improves readability, making scientific content comprehensible to non-specialists. Evaluations using the publicly accessible PLOS and eLife datasets show that our methods surpass Plain Gemini model, demonstrating a 20% increase in readability scores, a 15% improvement in ROUGE-2 relevance scores, and a 10% enhancement in factual accuracy. The RAG-RLRC-LaySum framework effectively democratizes scientific knowledge, enhancing public engagement with biomedical discoveries.