 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-Wise Ratio Tests for Fast Camera Localization
May 20, 2017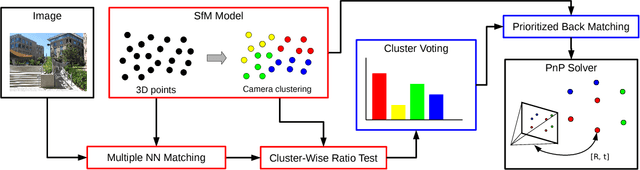
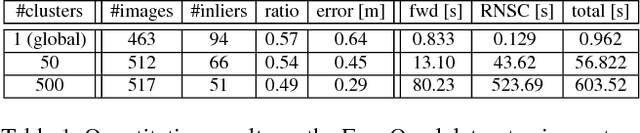
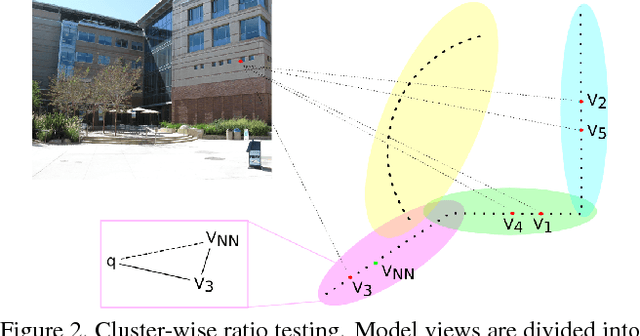
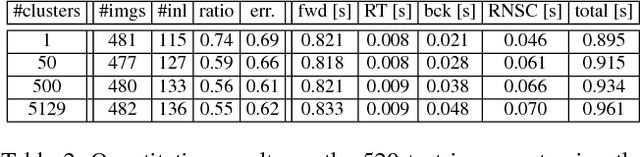
Feature point matching for camera localization suffers from scalability problems. Even when feature descriptors associated with 3D scene points are locally unique, as coverage grows, similar or repeated features become increasingly common. As a result, the standard distance ratio-test used to identify reliable image feature points is overly restrictive and rejects many good candidate matches. We propose a simple coarse-to-fine strategy that uses conservative approximations to robust local ratio-tests that can be computed efficiently using global approximate k-nearest neighbor search. We treat these forward matches as votes in camera pose space and use them to prioritize back-matching within candidate camera pose clusters, exploiting feature co-visibility captured by clustering the 3D model camera pose graph. This approach achieves state-of-the-art camera localization results on a variety of popular benchmarks, outperforming several methods that use more complicated data structures and that make more restrictive assumptions on camera pose. We also carry out diagnostic analyses on a difficult test dataset containing globally repetitive structure that suggest our approach successfully adapts to the challenges of large-scale image localization.
Lifting GIS Maps into Strong Geometric Context for Scene Understanding
Jan 08, 2016



Contextual information can have a substantial impact on the performance of visual tasks such as semantic segmentation, object detection, and geometric estimation. Data stored in Geographic Information Systems (GIS) offers a rich source of contextual information that has been largely untapped by computer vision. We propose to leverage such information for scene understanding by combining GIS resources with large sets of unorganized photographs using Structure from Motion (SfM) techniques. We present a pipeline to quickly generate strong 3D geometric priors from 2D GIS data using SfM models aligned with minimal user input. Given an image resectioned against this model, we generate robust predictions of depth, surface normals, and semantic labels. We show that the precision of the predicted geometry is substantially more accurate other single-image depth estimation methods. We then demonstrate the utility of these contextual constraints for re-scoring pedestrian detections, and use these GIS contextual features alongside object detection score maps to improve a CRF-based semantic segmentation framework, boosting accuracy over baseline models.