 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShoeRinsics: Shoeprint Prediction for Forensics with Intrinsic Decomposition
May 04, 2022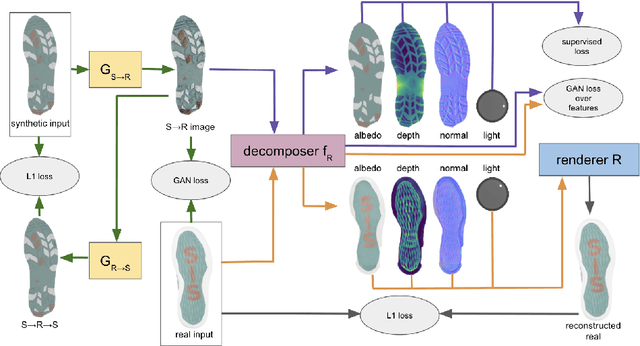


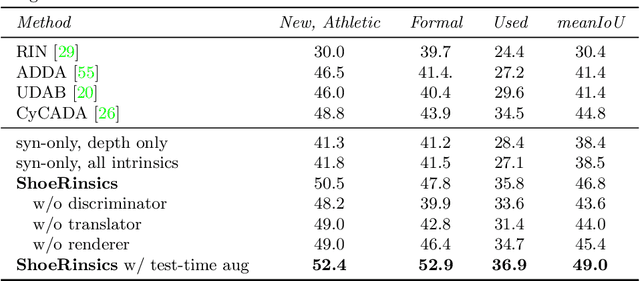
Shoe tread impressions are one of the most common types of evidence left at crime scenes. However, the utility of such evidence is limited by the lack of databases of footwear impression patterns that cover the huge and growing number of distinct shoe models. We propose to address this gap by leveraging shoe tread photographs collected by online retailers. The core challenge is to predict the impression pattern from the shoe photograph since ground-truth impressions or 3D shapes of tread patterns are not available. We develop a model that performs intrinsic image decomposition (predicting depth, normal, albedo, and lighting) from a single tread photo. Our approach, which we term ShoeRinsics, combines domain adaptation and re-rendering losses in order to leverage a mix of fully supervised synthetic data and unsupervised retail image data. To validate model performance, we also collected a set of paired shoe-sole images and corresponding prints, and define a benchmarking protocol to quantify the accuracy of predicted impressions. On this benchmark, ShoeRinsics outperforms existing methods for depth prediction and synthetic-to-real domain adaptation.
Cross-Domain Image Matching with Deep Feature Maps
Oct 01, 2018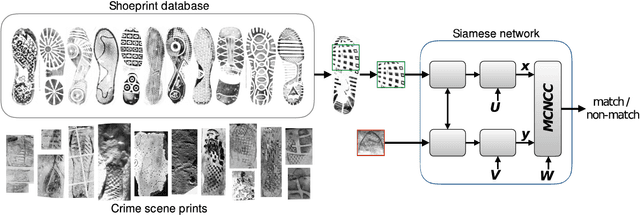
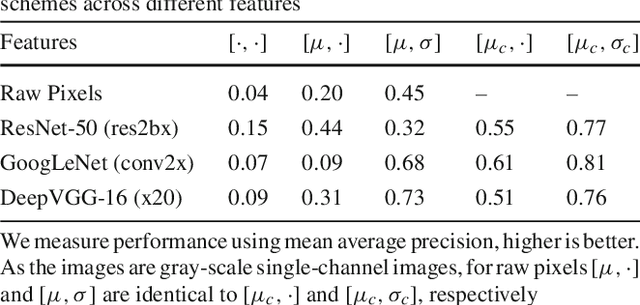
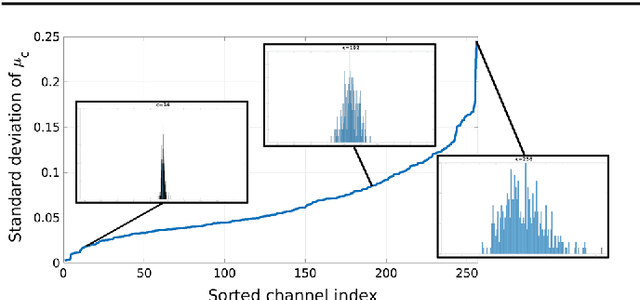
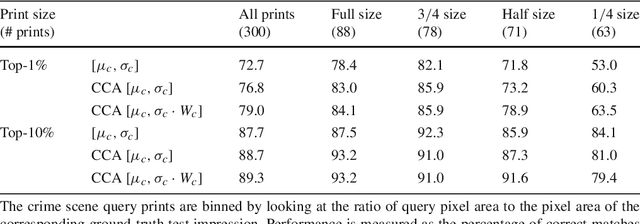
We investigate the problem of automatically determining what type of shoe left an impression found at a crime scene. This recognition problem is made difficult by the variability in types of crime scene evidence (ranging from traces of dust or oil on hard surfaces to impressions made in soil) and the lack of comprehensive databases of shoe outsole tread patterns. We find that mid-level features extracted by pre-trained convolutional neural nets are surprisingly effective descriptors for this specialized domains. However, the choice of similarity measure for matching exemplars to a query image is essential to good performance. For matching multi-channel deep features, we propose the use of multi-channel normalized cross-correlation and analyze its effectiveness. Our proposed metric significantly improves performance in matching crime scene shoeprints to laboratory test impressions. We also show its effectiveness in other cross-domain image retrieval problems: matching facade images to segmentation labels and aerial photos to map images. Finally, we introduce a discriminatively trained variant and fine-tune our system through our proposed metric, obtaining state-of-the-art performance.
Energy-Based Spherical Sparse Coding
Oct 04, 2017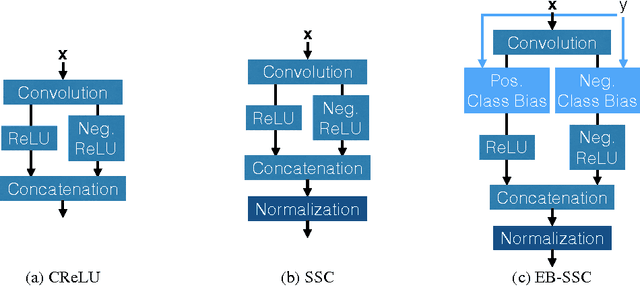
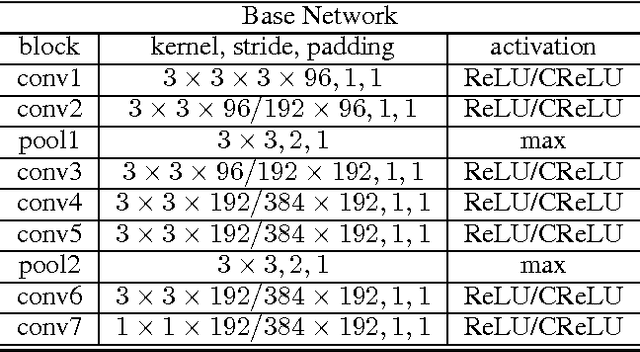
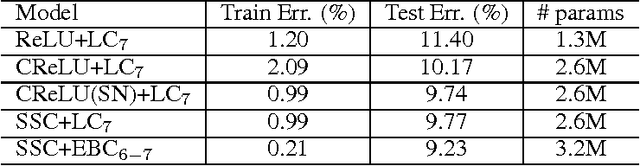
In this paper, we explore an efficient variant of convolutional sparse coding with unit norm code vectors where reconstruction quality is evaluated using an inner product (cosine distance). To use these codes for discriminative classification, we describe a model we term Energy-Based Spherical Sparse Coding (EB-SSC) in which the hypothesized class label introduces a learned linear bias into the coding step. We evaluate and visualize performance of stacking this encoder to make a deep layered model for image classification.