 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised Action Localization with Background Modeling
Aug 19, 2019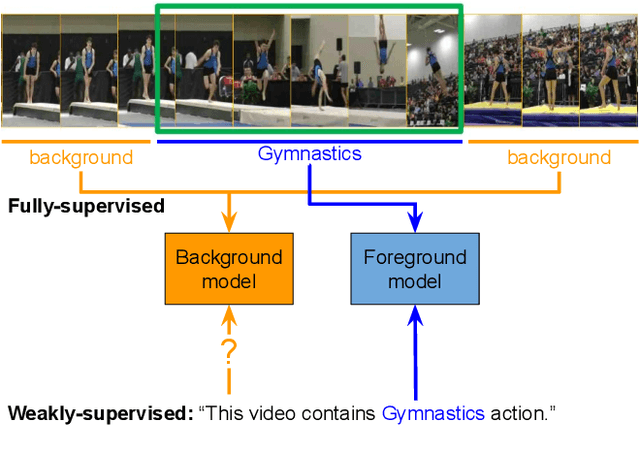
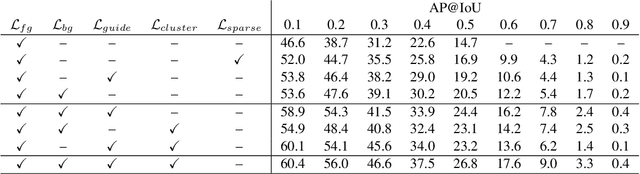
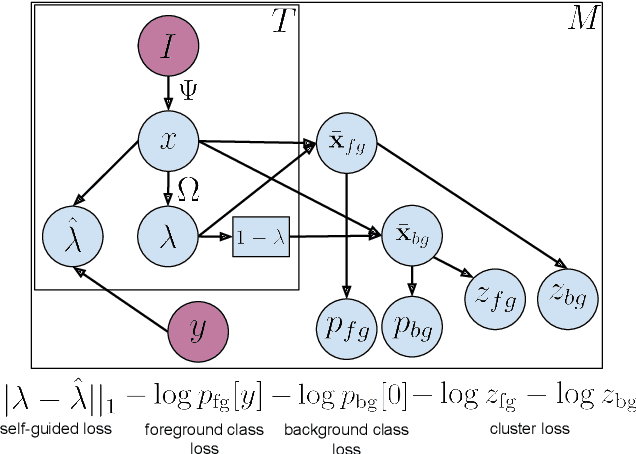
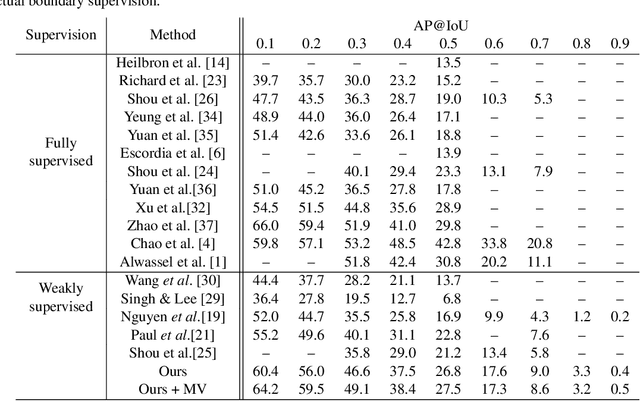
We describe a latent approach that learns to detect actions in long sequences given training videos with only whole-video class labels. Our approach makes use of two innovations to attention-modeling in weakly-supervised learning. First, and most notably, our framework uses an attention model to extract both foreground and background frames whose appearance is explicitly modeled. Most prior works ignore the background, but we show that modeling it allows our system to learn a richer notion of actions and their temporal extents. Second, we combine bottom-up, class-agnostic attention modules with top-down, class-specific activation maps, using the latter as form of self-supervision for the former. Doing so allows our model to learn a more accurate model of attention without explicit temporal supervision. These modifications lead to 10% AP@IoU=0.5 improvement over existing systems on THUMOS14. Our proposed weaklysupervised system outperforms recent state-of-the-arts by at least 4.3% AP@IoU=0.5. Finally, we demonstrate that weakly-supervised learning can be used to aggressively scale-up learning to in-the-wild, uncurated Instagram videos. The addition of these videos significantly improves localization performance of our weakly-supervised model
The Open World of Micro-Videos
Apr 01, 2016
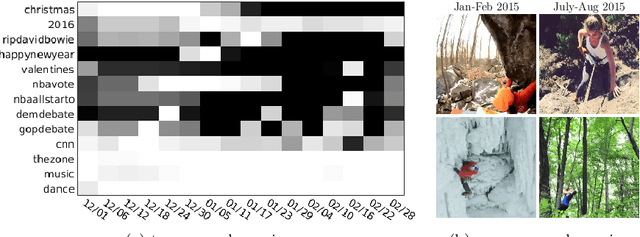
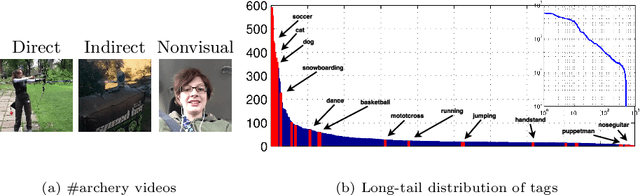
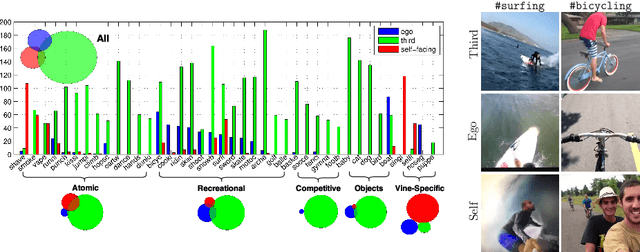
Micro-videos are six-second videos popular on social media networks with several unique properties. Firstly, because of the authoring process, they contain significantly more diversity and narrative structure than existing collections of video "snippets". Secondly, because they are often captured by hand-held mobile cameras, they contain specialized viewpoints including third-person, egocentric, and self-facing views seldom seen in traditional produced video. Thirdly, due to to their continuous production and publication on social networks, aggregate micro-video content contains interesting open-world dynamics that reflects the temporal evolution of tag topics. These aspects make micro-videos an appealing well of visual data for developing large-scale models for video understanding. We analyze a novel dataset of micro-videos labeled with 58 thousand tags. To analyze this data, we introduce viewpoint-specific and temporally-evolving models for video understanding, defined over state-of-the-art motion and deep visual features. We conclude that our dataset opens up new research opportunities for large-scale video analysis, novel viewpoints, and open-world dynamics.