 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian temporal biclustering with applications to multi-subject neuroscience studies
Jun 24, 2024



We consider the problem of analyzing multivariate time series collected on multiple subjects, with the goal of identifying groups of subjects exhibiting similar trends in their recorded measurements over time as well as time-varying groups of associated measurements. To this end, we propose a Bayesian model for temporal biclustering featuring nested partitions, where a time-invariant partition of subjects induces a time-varying partition of measurements. Our approach allows for data-driven determination of the number of subject and measurement clusters as well as estimation of the number and location of changepoints in measurement partitions. To efficiently perform model fitting and posterior estimation with Markov Chain Monte Carlo, we derive a blocked update of measurements' cluster-assignment sequences. We illustrate the performance of our model in two applications to functional magnetic resonance imaging data and to an electroencephalogram dataset. The results indicate that the proposed model can combine information from potentially many subjects to discover a set of interpretable, dynamic patterns. Experiments on simulated data compare the estimation performance of the proposed model against ground-truth values and other statistical methods, showing that it performs well at identifying ground-truth subject and measurement clusters even when no subject or time dependence is present.
Latent Network Estimation and Variable Selection for Compositional Data via Variational EM
Oct 25, 2020
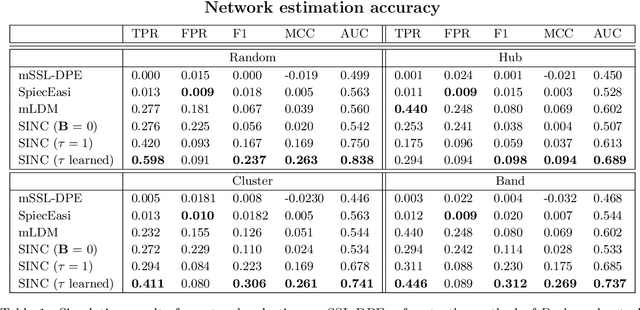

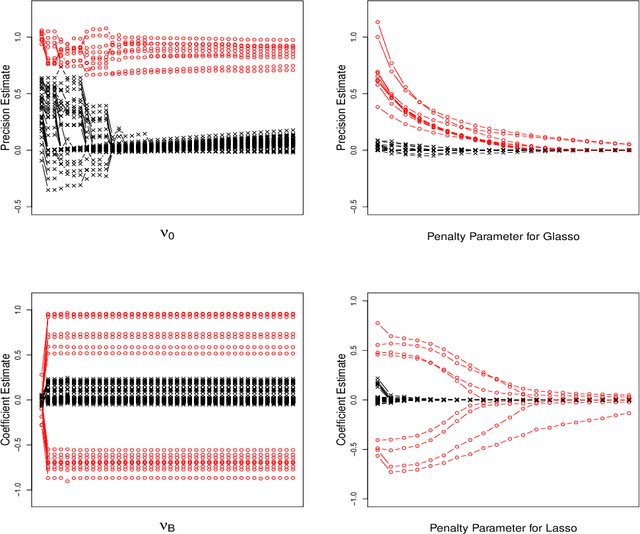
Network estimation and variable selection have been extensively studied in the statistical literature, but only recently have those two challenges been addressed simultaneously. In this paper, we seek to develop a novel method to simultaneously estimate network interactions and associations to relevant covariates for count data, and specifically for compositional data, which have a fixed sum constraint. We use a hierarchical Bayesian model with latent layers and employ spike-and-slab priors for both edge and covariate selection. For posterior inference, we develop a variational inference scheme with an expectation maximization step, to enable efficient estimation. Through simulation studies, we demonstrate that the proposed model outperforms existing methods in its accuracy of network recovery. We show the practical utility of our model via an application to microbiome data. The human microbiome has been shown to contribute to many of the functions of the human body, and also to be linked with a number of diseases. In our application, we seek to better understand the interaction between microbes and relevant covariates, as well as the interaction of microbes with each other. We provide a Python implementation of our algorithm, called SINC (Simultaneous Inference for Networks and Covariates), available online.
Regularized Partial Least Squares with an Application to NMR Spectroscopy
Apr 17, 2012
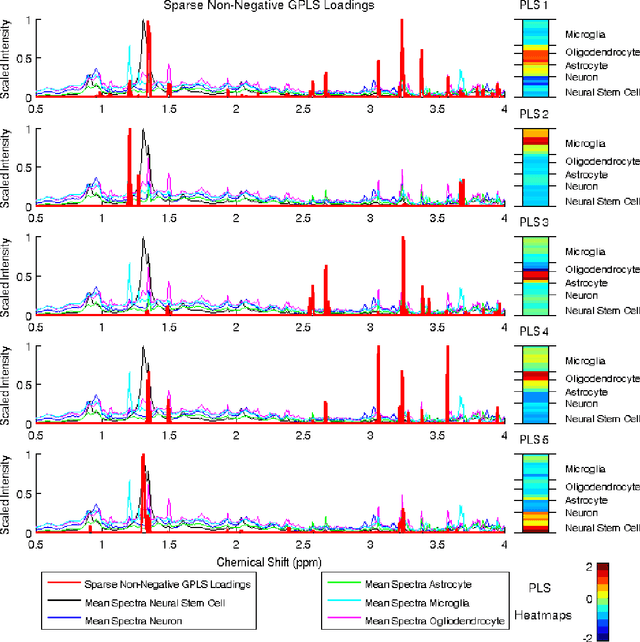
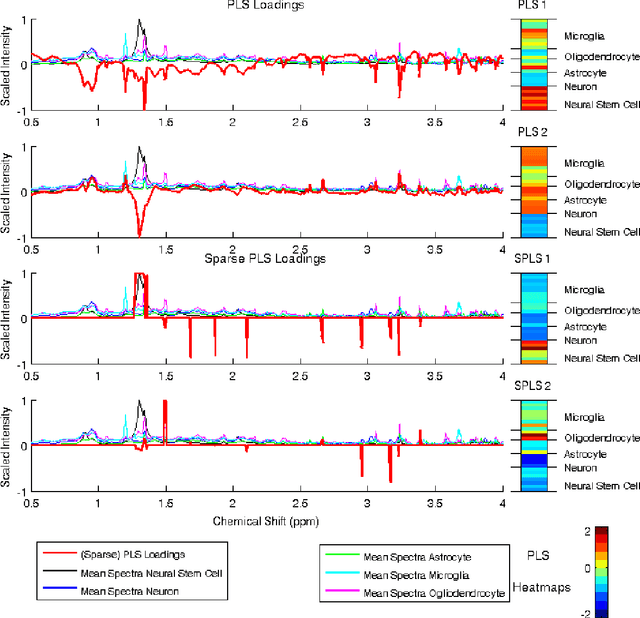
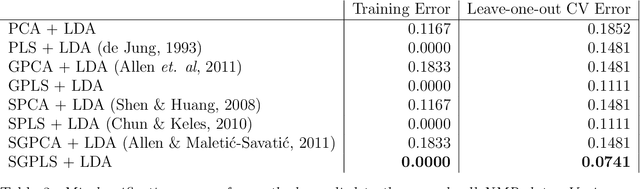
High-dimensional data common in genomics, proteomics, and chemometrics often contains complicated correlation structures. Recently, partial least squares (PLS) and Sparse PLS methods have gained attention in these areas as dimension reduction techniques in the context of supervised data analysis. We introduce a framework for Regularized PLS by solving a relaxation of the SIMPLS optimization problem with penalties on the PLS loadings vectors. Our approach enjoys many advantages including flexibility, general penalties, easy interpretation of results, and fast computation in high-dimensional settings. We also outline extensions of our methods leading to novel methods for Non-negative PLS and Generalized PLS, an adaption of PLS for structured data. We demonstrate the utility of our methods through simulations and a case study on proton Nuclear Magnetic Resonance (NMR) spectroscopy data.