 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Sum-of-Trees Model for Clustered Data
Feb 03, 2026Clustered data, which arise when observations are nested within groups, are incredibly common in clinical, education, and social science research. Traditionally, a linear mixed model, which includes random effects to account for within-group correlation, would be used to model the observed data and make new predictions on unseen data. Some work has been done to extend the mixed model approach beyond linear regression into more complex and non-parametric models, such as decision trees and random forests. However, existing methods are limited to using the global fixed effects for prediction on data from out-of-sample groups, effectively assuming that all clusters share a common outcome model. We propose a lightweight sum-of-trees model in which we learn a decision tree for each sample group. We combine the predictions from these trees using weights so that out-of-sample group predictions are more closely aligned with the most similar groups in the training data. This strategy also allows for inference on the similarity across groups in the outcome prediction model, as the unique tree structures and variable importances for each group can be directly compared. We show our model outperforms traditional decision trees and random forests in a variety of simulation settings. Finally, we showcase our method on real-world data from the sarcoma cohort of The Cancer Genome Atlas, where patient samples are grouped by sarcoma subtype.
pared: Model selection using multi-objective optimization
May 27, 2025Motivation: Model selection is a ubiquitous challenge in statistics. For penalized models, model selection typically entails tuning hyperparameters to maximize a measure of fit or minimize out-of-sample prediction error. However, these criteria fail to reflect other desirable characteristics, such as model sparsity, interpretability, or smoothness. Results: We present the R package pared to enable the use of multi-objective optimization for model selection. Our approach entails the use of Gaussian process-based optimization to efficiently identify solutions that represent desirable trade-offs. Our implementation includes popular models with multiple objectives including the elastic net, fused lasso, fused graphical lasso, and group graphical lasso. Our R package generates interactive graphics that allow the user to identify hyperparameter values that result in fitted models which lie on the Pareto frontier. Availability: We provide the R package pared and vignettes illustrating its application to both simulated and real data at https://github.com/priyamdas2/pared.
Latent Network Estimation and Variable Selection for Compositional Data via Variational EM
Oct 25, 2020
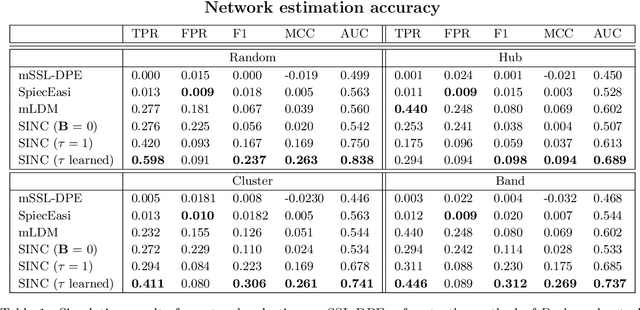

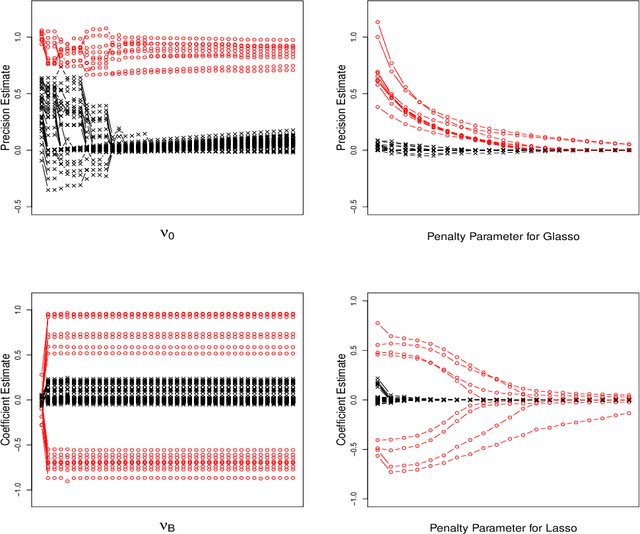
Network estimation and variable selection have been extensively studied in the statistical literature, but only recently have those two challenges been addressed simultaneously. In this paper, we seek to develop a novel method to simultaneously estimate network interactions and associations to relevant covariates for count data, and specifically for compositional data, which have a fixed sum constraint. We use a hierarchical Bayesian model with latent layers and employ spike-and-slab priors for both edge and covariate selection. For posterior inference, we develop a variational inference scheme with an expectation maximization step, to enable efficient estimation. Through simulation studies, we demonstrate that the proposed model outperforms existing methods in its accuracy of network recovery. We show the practical utility of our model via an application to microbiome data. The human microbiome has been shown to contribute to many of the functions of the human body, and also to be linked with a number of diseases. In our application, we seek to better understand the interaction between microbes and relevant covariates, as well as the interaction of microbes with each other. We provide a Python implementation of our algorithm, called SINC (Simultaneous Inference for Networks and Covariates), available online.