 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeakingFaces: A Large-Scale Multimodal Dataset of Voice Commands with Visual and Thermal Video Streams
Dec 18, 2020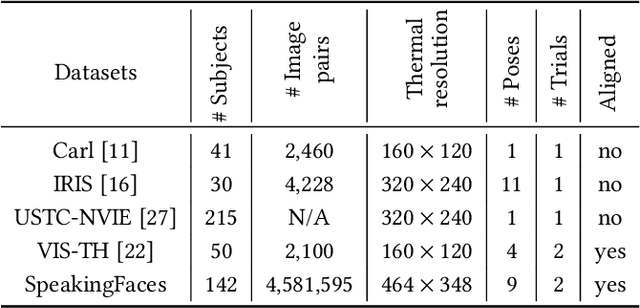


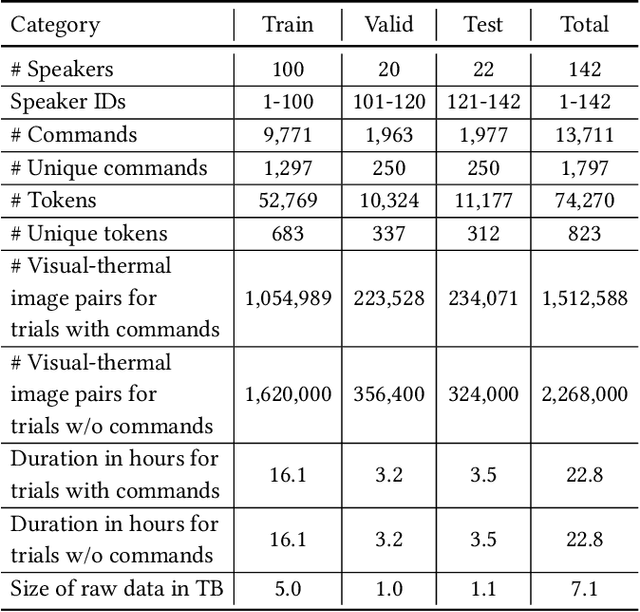
We present SpeakingFaces as a publicly-available large-scale dataset developed to support multimodal machine learning research in contexts that utilize a combination of thermal, visual, and audio data streams; examples include human-computer interaction (HCI), biometric authentication, recognition systems, domain transfer, and speech recognition. SpeakingFaces is comprised of well-aligned high-resolution thermal and visual spectra image streams of fully-framed faces synchronized with audio recordings of each subject speaking approximately 100 imperative phrases. Data were collected from 142 subjects, yielding over 13,000 instances of synchronized data (~3.8 TB). For technical validation, we demonstrate two baseline examples. The first baseline shows classification by gender, utilizing different combinations of the three data streams in both clean and noisy environments. The second example consists of thermal-to-visual facial image translation, as an instance of domain transfer.