 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Classic and Neural Lexical Translation Models for Information Retrieval: Interpretability, Effectiveness, and Efficiency Benefits
Paper and Code
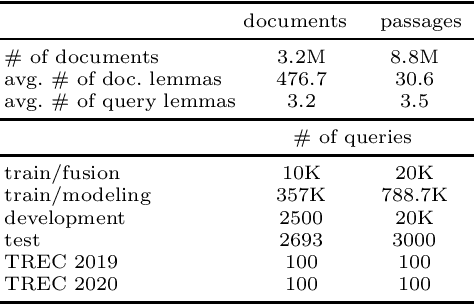
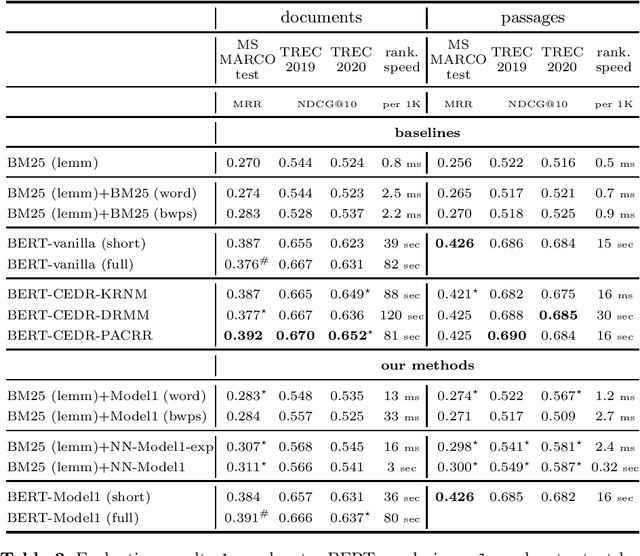
We study the utility of the lexical translation model (IBM Model 1) for English text retrieval, in particular, its neural variants that are trained end-to-end. We use the neural Model1 as an aggregator layer applied to context-free or contextualized query/document embeddings. This new approach to design a neural ranking system has benefits for effectiveness, efficiency, and interpretability. Specifically, we show that adding an interpretable neural Model 1 layer on top of BERT-based contextualized embeddings (1) does not decrease accuracy and/or efficiency; and (2) may overcome the limitation on the maximum sequence length of existing BERT models. The context-free neural Model 1 is less effective than a BERT-based ranking model, but it can run efficiently on a CPU (without expensive index-time precomputation or query-time operations on large tensors). Using Model 1 we produced best neural and non-neural runs on the MS MARCO document ranking leaderboard in late 2020.