 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Decoding with Speculative Lookaheads
Dec 09, 2024Constrained decoding with lookahead heuristics (CDLH) is a highly effective method for aligning LLM generations to human preferences. However, the extensive lookahead roll-out operations for each generated token makes CDLH prohibitively expensive, resulting in low adoption in practice. In contrast, common decoding strategies such as greedy decoding are extremely efficient, but achieve very low constraint satisfaction. We propose constrained decoding with speculative lookaheads (CDSL), a technique that significantly improves upon the inference efficiency of CDLH without experiencing the drastic performance reduction seen with greedy decoding. CDSL is motivated by the recently proposed idea of speculative decoding that uses a much smaller draft LLM for generation and a larger target LLM for verification. In CDSL, the draft model is used to generate lookaheads which is verified by a combination of target LLM and task-specific reward functions. This process accelerates decoding by reducing the computational burden while maintaining strong performance. We evaluate CDSL in two constraint decoding tasks with three LLM families and achieve 2.2x to 12.15x speedup over CDLH without significant performance reduction.
Semantic Retrieval at Walmart
Dec 05, 2024



In product search, the retrieval of candidate products before re-ranking is more critical and challenging than other search like web search, especially for tail queries, which have a complex and specific search intent. In this paper, we present a hybrid system for e-commerce search deployed at Walmart that combines traditional inverted index and embedding-based neural retrieval to better answer user tail queries. Our system significantly improved the relevance of the search engine, measured by both offline and online evaluations. The improvements were achieved through a combination of different approaches. We present a new technique to train the neural model at scale. and describe how the system was deployed in production with little impact on response time. We highlight multiple learnings and practical tricks that were used in the deployment of this system.
A Multi-task Learning Framework for Product Ranking with BERT
Feb 10, 2022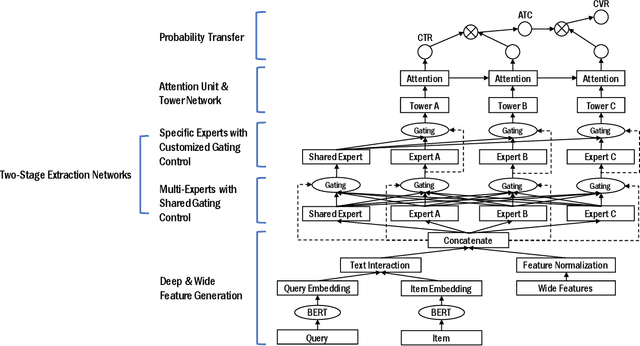



Product ranking is a crucial component for many e-commerce services. One of the major challenges in product search is the vocabulary mismatch between query and products, which may be a larger vocabulary gap problem compared to other information retrieval domains. While there is a growing collection of neural learning to match methods aimed specifically at overcoming this issue, they do not leverage the recent advances of large language models for product search. On the other hand, product ranking often deals with multiple types of engagement signals such as clicks, add-to-cart, and purchases, while most of the existing works are focused on optimizing one single metric such as click-through rate, which may suffer from data sparsity. In this work, we propose a novel end-to-end multi-task learning framework for product ranking with BERT to address the above challenges. The proposed model utilizes domain-specific BERT with fine-tuning to bridge the vocabulary gap and employs multi-task learning to optimize multiple objectives simultaneously, which yields a general end-to-end learning framework for product search. We conduct a set of comprehensive experiments on a real-world e-commerce dataset and demonstrate significant improvement of the proposed approach over the state-of-the-art baseline methods.
Variational Deep Semantic Hashing for Text Documents
Aug 11, 2017

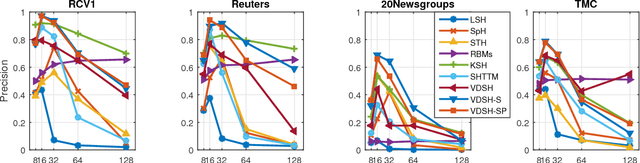

As the amount of textual data has been rapidly increasing over the past decade, efficient similarity search methods have become a crucial component of large-scale information retrieval systems. A popular strategy is to represent original data samples by compact binary codes through hashing. A spectrum of machine learning methods have been utilized, but they often lack expressiveness and flexibility in modeling to learn effective representations. The recent advances of deep learning in a wide range of applications has demonstrated its capability to learn robust and powerful feature representations for complex data. Especially, deep generative models naturally combine the expressiveness of probabilistic generative models with the high capacity of deep neural networks, which is very suitable for text modeling. However, little work has leveraged the recent progress in deep learning for text hashing. In this paper, we propose a series of novel deep document generative models for text hashing. The first proposed model is unsupervised while the second one is supervised by utilizing document labels/tags for hashing. The third model further considers document-specific factors that affect the generation of words. The probabilistic generative formulation of the proposed models provides a principled framework for model extension, uncertainty estimation, simulation, and interpretability. Based on variational inference and reparameterization, the proposed models can be interpreted as encoder-decoder deep neural networks and thus they are capable of learning complex nonlinear distributed representations of the original documents. We conduct a comprehensive set of experiments on four public testbeds. The experimental results have demonstrated the effectiveness of the proposed supervised learning models for text hashing.