 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterleaved Gibbs Diffusion for Constrained Generation
Feb 19, 2025We introduce Interleaved Gibbs Diffusion (IGD), a novel generative modeling framework for mixed continuous-discrete data, focusing on constrained generation problems. Prior works on discrete and continuous-discrete diffusion models assume factorized denoising distribution for fast generation, which can hinder the modeling of strong dependencies between random variables encountered in constrained generation. IGD moves beyond this by interleaving continuous and discrete denoising algorithms via a discrete time Gibbs sampling type Markov chain. IGD provides flexibility in the choice of denoisers, allows conditional generation via state-space doubling and inference time scaling via the ReDeNoise method. Empirical evaluations on three challenging tasks-solving 3-SAT, generating molecule structures, and generating layouts-demonstrate state-of-the-art performance. Notably, IGD achieves a 7% improvement on 3-SAT out of the box and achieves state-of-the-art results in molecule generation without relying on equivariant diffusion or domain-specific architectures. We explore a wide range of modeling, and interleaving strategies along with hyperparameters in each of these problems.
Semantic Retrieval at Walmart
Dec 05, 2024



In product search, the retrieval of candidate products before re-ranking is more critical and challenging than other search like web search, especially for tail queries, which have a complex and specific search intent. In this paper, we present a hybrid system for e-commerce search deployed at Walmart that combines traditional inverted index and embedding-based neural retrieval to better answer user tail queries. Our system significantly improved the relevance of the search engine, measured by both offline and online evaluations. The improvements were achieved through a combination of different approaches. We present a new technique to train the neural model at scale. and describe how the system was deployed in production with little impact on response time. We highlight multiple learnings and practical tricks that were used in the deployment of this system.
On the Necessity of World Knowledge for Mitigating Missing Labels in Extreme Classification
Aug 18, 2024Extreme Classification (XC) aims to map a query to the most relevant documents from a very large document set. XC algorithms used in real-world applications learn this mapping from datasets curated from implicit feedback, such as user clicks. However, these datasets inevitably suffer from missing labels. In this work, we observe that systematic missing labels lead to missing knowledge, which is critical for accurately modelling relevance between queries and documents. We formally show that this absence of knowledge cannot be recovered using existing methods such as propensity weighting and data imputation strategies that solely rely on the training dataset. While LLMs provide an attractive solution to augment the missing knowledge, leveraging them in applications with low latency requirements and large document sets is challenging. To incorporate missing knowledge at scale, we propose SKIM (Scalable Knowledge Infusion for Missing Labels), an algorithm that leverages a combination of small LM and abundant unstructured meta-data to effectively mitigate the missing label problem. We show the efficacy of our method on large-scale public datasets through exhaustive unbiased evaluation ranging from human annotations to simulations inspired from industrial settings. SKIM outperforms existing methods on Recall@100 by more than 10 absolute points. Additionally, SKIM scales to proprietary query-ad retrieval datasets containing 10 million documents, outperforming contemporary methods by 12% in offline evaluation and increased ad click-yield by 1.23% in an online A/B test conducted on a popular search engine. We release our code, prompts, trained XC models and finetuned SLMs at: https://github.com/bicycleman15/skim
Enhancing Relevance of Embedding-based Retrieval at Walmart
Aug 09, 2024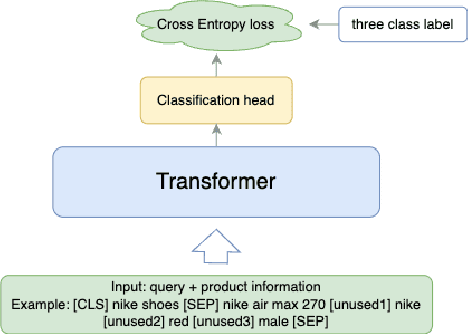

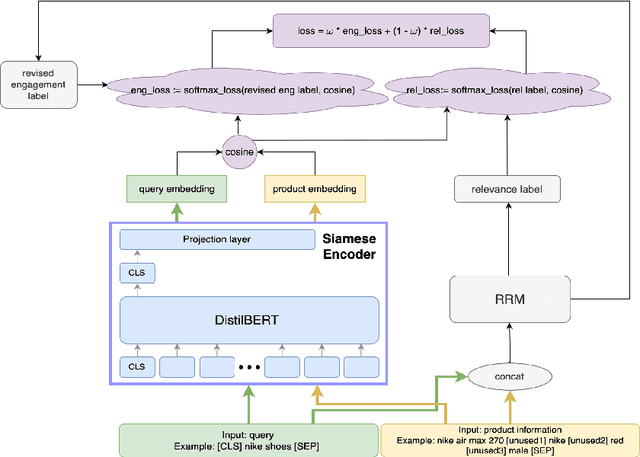
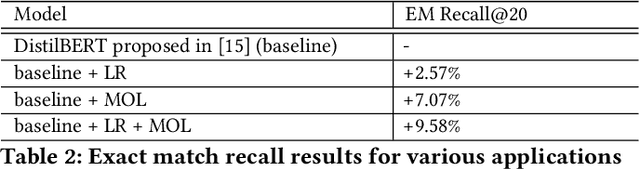
Embedding-based neural retrieval (EBR) is an effective search retrieval method in product search for tackling the vocabulary gap between customer search queries and products. The initial launch of our EBR system at Walmart yielded significant gains in relevance and add-to-cart rates [1]. However, despite EBR generally retrieving more relevant products for reranking, we have observed numerous instances of relevance degradation. Enhancing retrieval performance is crucial, as it directly influences product reranking and affects the customer shopping experience. Factors contributing to these degradations include false positives/negatives in the training data and the inability to handle query misspellings. To address these issues, we present several approaches to further strengthen the capabilities of our EBR model in terms of retrieval relevance. We introduce a Relevance Reward Model (RRM) based on human relevance feedback. We utilize RRM to remove noise from the training data and distill it into our EBR model through a multi-objective loss. In addition, we present the techniques to increase the performance of our EBR model, such as typo-aware training, and semi-positive generation. The effectiveness of our EBR is demonstrated through offline relevance evaluation, online AB tests, and successful deployments to live production. [1] Alessandro Magnani, Feng Liu, Suthee Chaidaroon, Sachin Yadav, Praveen Reddy Suram, Ajit Puthenputhussery, Sijie Chen, Min Xie, Anirudh Kashi, Tony Lee, et al. 2022. Semantic retrieval at walmart. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3495-3503.
Towards Automating Text Annotation: A Case Study on Semantic Proximity Annotation using GPT-4
Jul 04, 2024



This paper explores using GPT-3.5 and GPT-4 to automate the data annotation process with automatic prompting techniques. The main aim of this paper is to reuse human annotation guidelines along with some annotated data to design automatic prompts for LLMs, focusing on the semantic proximity annotation task. Automatic prompts are compared to customized prompts. We further implement the prompting strategies into an open-source text annotation tool, enabling easy online use via the OpenAI API. Our study reveals the crucial role of accurate prompt design and suggests that prompting GPT-4 with human-like instructions is not straightforwardly possible for the semantic proximity task. We show that small modifications to the human guidelines already improve the performance, suggesting possible ways for future research.
Large Language Models for Relevance Judgment in Product Search
Jun 01, 2024High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
Deep Gaussian Processes for Air Quality Inference
Nov 18, 2022
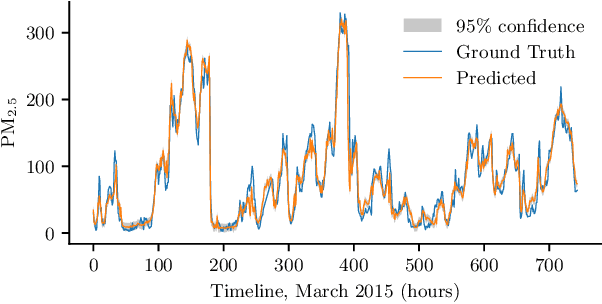
Air pollution kills around 7 million people annually, and approximately 2.4 billion people are exposed to hazardous air pollution. Accurate, fine-grained air quality (AQ) monitoring is essential to control and reduce pollution. However, AQ station deployment is sparse, and thus air quality inference for unmonitored locations is crucial. Conventional interpolation methods fail to learn the complex AQ phenomena. This work demonstrates that Deep Gaussian Process models (DGPs) are a promising model for the task of AQ inference. We implement Doubly Stochastic Variational Inference, a DGP algorithm, and show that it performs comparably to the state-of-the-art models.