 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevance Filtering for Embedding-based Retrieval
Aug 09, 2024



In embedding-based retrieval, Approximate Nearest Neighbor (ANN) search enables efficient retrieval of similar items from large-scale datasets. While maximizing recall of relevant items is usually the goal of retrieval systems, a low precision may lead to a poor search experience. Unlike lexical retrieval, which inherently limits the size of the retrieved set through keyword matching, dense retrieval via ANN search has no natural cutoff. Moreover, the cosine similarity scores of embedding vectors are often optimized via contrastive or ranking losses, which make them difficult to interpret. Consequently, relying on top-K or cosine-similarity cutoff is often insufficient to filter out irrelevant results effectively. This issue is prominent in product search, where the number of relevant products is often small. This paper introduces a novel relevance filtering component (called "Cosine Adapter") for embedding-based retrieval to address this challenge. Our approach maps raw cosine similarity scores to interpretable scores using a query-dependent mapping function. We then apply a global threshold on the mapped scores to filter out irrelevant results. We are able to significantly increase the precision of the retrieved set, at the expense of a small loss of recall. The effectiveness of our approach is demonstrated through experiments on both public MS MARCO dataset and internal Walmart product search data. Furthermore, online A/B testing on the Walmart site validates the practical value of our approach in real-world e-commerce settings.
Enhancing Relevance of Embedding-based Retrieval at Walmart
Aug 09, 2024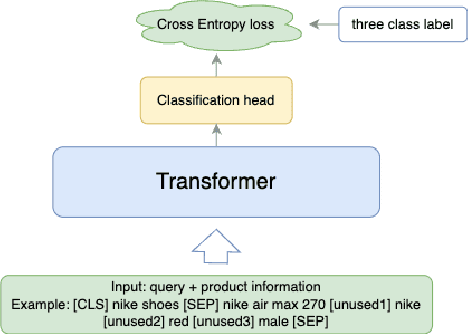

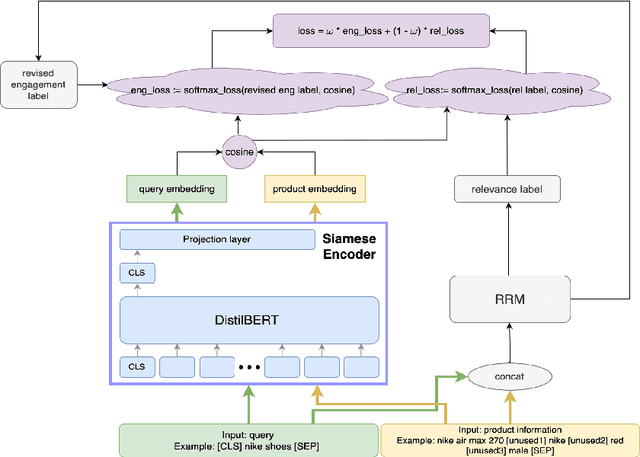
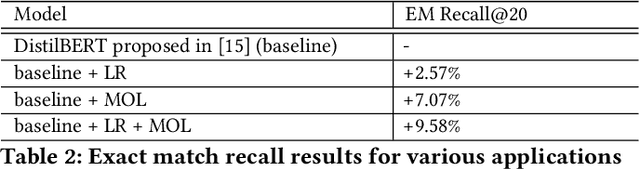
Embedding-based neural retrieval (EBR) is an effective search retrieval method in product search for tackling the vocabulary gap between customer search queries and products. The initial launch of our EBR system at Walmart yielded significant gains in relevance and add-to-cart rates [1]. However, despite EBR generally retrieving more relevant products for reranking, we have observed numerous instances of relevance degradation. Enhancing retrieval performance is crucial, as it directly influences product reranking and affects the customer shopping experience. Factors contributing to these degradations include false positives/negatives in the training data and the inability to handle query misspellings. To address these issues, we present several approaches to further strengthen the capabilities of our EBR model in terms of retrieval relevance. We introduce a Relevance Reward Model (RRM) based on human relevance feedback. We utilize RRM to remove noise from the training data and distill it into our EBR model through a multi-objective loss. In addition, we present the techniques to increase the performance of our EBR model, such as typo-aware training, and semi-positive generation. The effectiveness of our EBR is demonstrated through offline relevance evaluation, online AB tests, and successful deployments to live production. [1] Alessandro Magnani, Feng Liu, Suthee Chaidaroon, Sachin Yadav, Praveen Reddy Suram, Ajit Puthenputhussery, Sijie Chen, Min Xie, Anirudh Kashi, Tony Lee, et al. 2022. Semantic retrieval at walmart. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3495-3503.