 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Learning of Quantum State Tomography Robust to Readout Errors
Apr 15, 2026Scalable estimation of quantum states with readout errors is a central challenge in large multiqubit systems. Existing overlapping-tomography methods improve scalability by working with local subsystems, but they usually assume known or separately calibrated measurements. At the same time, readout-estimation methods model measurement errors without enforcing consistency among overlapping regional states. In this context, the present paper introduces a unified framework for joint regional quantum state tomography with readout errors. A multiqubit system is partitioned in overlapping regions, each region is assigned to a local density operator and a local confusion matrix, and neighboring regions are coupled through reduced-state consistency on shared subsystems. This leads to a structured bilinear optimization problem. To solve it, a distributed alternating method is developed in which the state-update step is handled by the alternating direction method of multipliers (ADMM), while the confusion-matrix updates are carried out locally in parallel. Analytical guarantees are also established, including a sufficient condition for local identifiability, local quadratic growth of the population misfit, and convergence of the inner state-update procedure. Simulations on Ring, Ladder, Torus, and Hub graph geometries show that joint estimation improves state recovery over fixed-readout reconstruction, recovers a substantial portion of oracle performance, and reveals a clear tradeoff between state estimation performance, communication, and computation.
Causal Representation Learning on High-Dimensional Data: Benchmarks, Reproducibility, and Evaluation Metrics
Mar 18, 2026Causal representation learning (CRL) models aim to transform high-dimensional data into a latent space, enabling interventions to generate counterfactual samples or modify existing data based on the causal relationships among latent variables. To facilitate the development and evaluation of these models, a variety of synthetic and real-world datasets have been proposed, each with distinct advantages and limitations. For practical applications, CRL models must perform robustly across multiple evaluation directions, including reconstruction, disentanglement, causal discovery, and counterfactual reasoning, using appropriate metrics for each direction. However, this multi-directional evaluation can complicate model comparison, as a model may excel in some direction while under-performing in others. Another significant challenge in this field is reproducibility: the source code corresponding to published results must be publicly available, and repeated runs should yield performance consistent with the original reports. In this study, we critically analyzed the synthetic and real-world datasets currently employed in the literature, highlighting their limitations and proposing a set of essential characteristics for suitable datasets in CRL model development. We also introduce a single aggregate metric that consolidates performance across all evaluation directions, providing a comprehensive score for each model. Finally, we reviewed existing implementations from the literature and assessed them in terms of reproducibility, identifying gaps and best practices in the field.
Interpretable graph-based models on multimodal biomedical data integration: A technical review and benchmarking
May 03, 2025



Integrating heterogeneous biomedical data including imaging, omics, and clinical records supports accurate diagnosis and personalised care. Graph-based models fuse such non-Euclidean data by capturing spatial and relational structure, yet clinical uptake requires regulator-ready interpretability. We present the first technical survey of interpretable graph based models for multimodal biomedical data, covering 26 studies published between Jan 2019 and Sep 2024. Most target disease classification, notably cancer and rely on static graphs from simple similarity measures, while graph-native explainers are rare; post-hoc methods adapted from non-graph domains such as gradient saliency, and SHAP predominate. We group existing approaches into four interpretability families, outline trends such as graph-in-graph hierarchies, knowledge-graph edges, and dynamic topology learning, and perform a practical benchmark. Using an Alzheimer disease cohort, we compare Sensitivity Analysis, Gradient Saliency, SHAP and Graph Masking. SHAP and Sensitivity Analysis recover the broadest set of known AD pathways and Gene-Ontology terms, whereas Gradient Saliency and Graph Masking surface complementary metabolic and transport signatures. Permutation tests show all four beat random gene sets, but with distinct trade-offs: SHAP and Graph Masking offer deeper biology at higher compute cost, while Gradient Saliency and Sensitivity Analysis are quicker though coarser. We also provide a step-by-step flowchart covering graph construction, explainer choice and resource budgeting to help researchers balance transparency and performance. This review synthesises the state of interpretable graph learning for multimodal medicine, benchmarks leading techniques, and charts future directions, from advanced XAI tools to under-studied diseases, serving as a concise reference for method developers and translational scientists.
Deep conv-attention model for diagnosing left bundle branch block from 12-lead electrocardiograms
Dec 07, 2022Cardiac resynchronization therapy (CRT) is a treatment that is used to compensate for irregularities in the heartbeat. Studies have shown that this treatment is more effective in heart patients with left bundle branch block (LBBB) arrhythmia. Therefore, identifying this arrhythmia is an important initial step in determining whether or not to use CRT. On the other hand, traditional methods for detecting LBBB on electrocardiograms (ECG) are often associated with errors. Thus, there is a need for an accurate method to diagnose this arrhythmia from ECG data. Machine learning, as a new field of study, has helped to increase human systems' performance. Deep learning, as a newer subfield of machine learning, has more power to analyze data and increase systems accuracy. This study presents a deep learning model for the detection of LBBB arrhythmia from 12-lead ECG data. This model consists of 1D dilated convolutional layers. Attention mechanism has also been used to identify important input data features and classify inputs more accurately. The proposed model is trained and validated on a database containing 10344 12-lead ECG samples using the 10-fold cross-validation method. The final results obtained by the model on the 12-lead ECG data are as follows. Accuracy: 98.80+-0.08%, specificity: 99.33+-0.11 %, F1 score: 73.97+-1.8%, and area under the receiver operating characteristics curve (AUC): 0.875+-0.0192. These results indicate that the proposed model in this study can effectively diagnose LBBB with good efficiency and, if used in medical centers, will greatly help diagnose this arrhythmia and early treatment.
Robust, Deep, and Reinforcement Learning for Management of Communication and Power Networks
Feb 08, 2022


This thesis develops data-driven machine learning algorithms to managing and optimizing the next-generation highly complex cyberphysical systems, which desperately need ground-breaking control, monitoring, and decision making schemes that can guarantee robustness, scalability, and situational awareness. The present thesis first develops principled methods to make generic machine learning models robust against distributional uncertainties and adversarial data. Particular focus will be on parametric models where some training data are being used to learn a parametric model. The developed framework is of high interest especially when training and testing data are drawn from "slightly" different distribution. We then introduce distributionally robust learning frameworks to minimize the worst-case expected loss over a prescribed ambiguity set of training distributions quantified via Wasserstein distance. Later, we build on this robust framework to design robust semi-supervised learning over graph methods. The second part of this thesis aspires to fully unleash the potential of next-generation wired and wireless networks, where we design "smart" network entities using (deep) reinforcement learning approaches. Finally, this thesis enhances the power system operation and control. Our contribution is on sustainable distribution grids with high penetration of renewable sources and demand response programs. To account for unanticipated and rapidly changing renewable generation and load consumption scenarios, we specifically delegate reactive power compensation to both utility-owned control devices (e.g., capacitor banks), as well as smart inverters of distributed generation units with cyber-capabilities.
Distributionally Robust Semi-Supervised Learning Over Graphs
Oct 20, 2021
Semi-supervised learning (SSL) over graph-structured data emerges in many network science applications. To efficiently manage learning over graphs, variants of graph neural networks (GNNs) have been developed recently. By succinctly encoding local graph structures and features of nodes, state-of-the-art GNNs can scale linearly with the size of graph. Despite their success in practice, most of existing methods are unable to handle graphs with uncertain nodal attributes. Specifically whenever mismatches between training and testing data distribution exists, these models fail in practice. Challenges also arise due to distributional uncertainties associated with data acquired by noisy measurements. In this context, a distributionally robust learning framework is developed, where the objective is to train models that exhibit quantifiable robustness against perturbations. The data distribution is considered unknown, but lies within a Wasserstein ball centered around empirical data distribution. A robust model is obtained by minimizing the worst expected loss over this ball. However, solving the emerging functional optimization problem is challenging, if not impossible. Advocating a strong duality condition, we develop a principled method that renders the problem tractable and efficiently solvable. Experiments assess the performance of the proposed method.
Heavy Ball Momentum for Conditional Gradient
Oct 08, 2021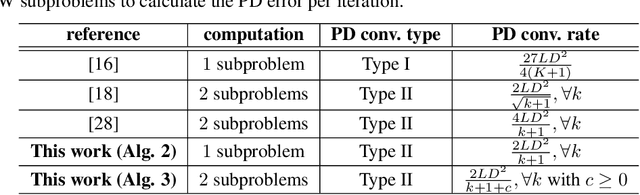
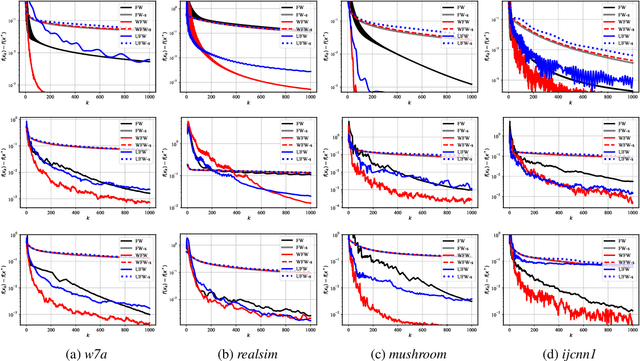
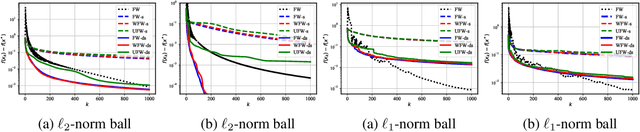
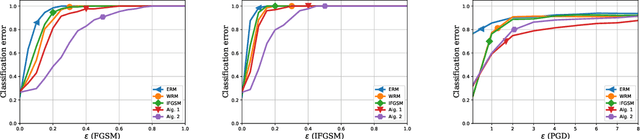
Conditional gradient, aka Frank Wolfe (FW) algorithms, have well-documented merits in machine learning and signal processing applications. Unlike projection-based methods, momentum cannot improve the convergence rate of FW, in general. This limitation motivates the present work, which deals with heavy ball momentum, and its impact to FW. Specifically, it is established that heavy ball offers a unifying perspective on the primal-dual (PD) convergence, and enjoys a tighter per iteration PD error rate, for multiple choices of step sizes, where PD error can serve as the stopping criterion in practice. In addition, it is asserted that restart, a scheme typically employed jointly with Nesterov's momentum, can further tighten this PD error bound. Numerical results demonstrate the usefulness of heavy ball momentum in FW iterations.
Learning while Respecting Privacy and Robustness to Distributional Uncertainties and Adversarial Data
Jul 07, 2020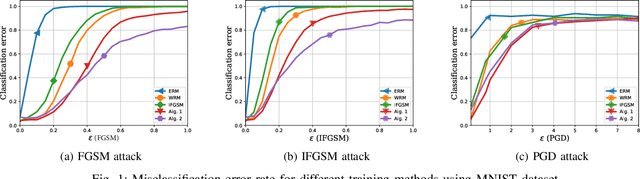

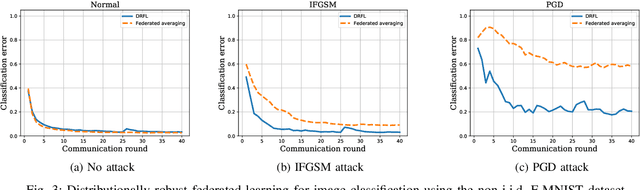
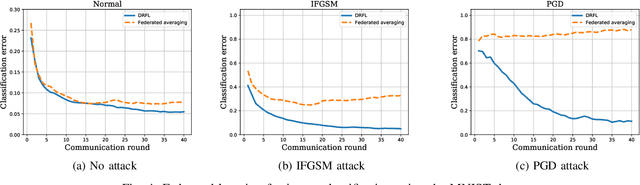
Data used to train machine learning models can be adversarial--maliciously constructed by adversaries to fool the model. Challenge also arises by privacy, confidentiality, or due to legal constraints when data are geographically gathered and stored across multiple learners, some of which may hold even an "anonymized" or unreliable dataset. In this context, the distributionally robust optimization framework is considered for training a parametric model, both in centralized and federated learning settings. The objective is to endow the trained model with robustness against adversarially manipulated input data, or, distributional uncertainties, such as mismatches between training and testing data distributions, or among datasets stored at different workers. To this aim, the data distribution is assumed unknown, and lies within a Wasserstein ball centered around the empirical data distribution. This robust learning task entails an infinite-dimensional optimization problem, which is challenging. Leveraging a strong duality result, a surrogate is obtained, for which three stochastic primal-dual algorithms are developed: i) stochastic proximal gradient descent with an $\epsilon$-accurate oracle, which invokes an oracle to solve the convex sub-problems; ii) stochastic proximal gradient descent-ascent, which approximates the solution of the convex sub-problems via a single gradient ascent step; and, iii) a distributionally robust federated learning algorithm, which solves the sub-problems locally at different workers where data are stored. Compared to the empirical risk minimization and federated learning methods, the proposed algorithms offer robustness with little computation overhead. Numerical tests using image datasets showcase the merits of the proposed algorithms under several existing adversarial attacks and distributional uncertainties.
Reinforcement Learning for Caching with Space-Time Popularity Dynamics
May 19, 2020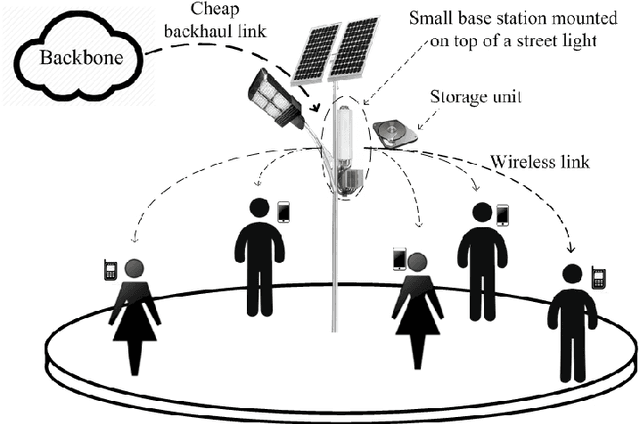
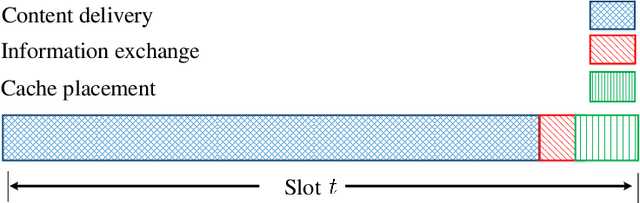
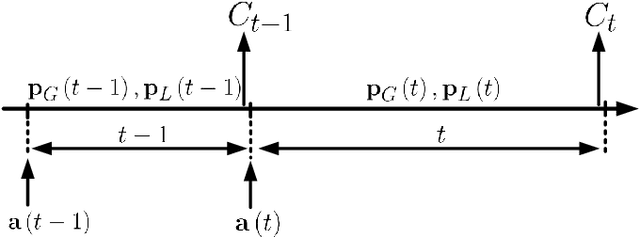
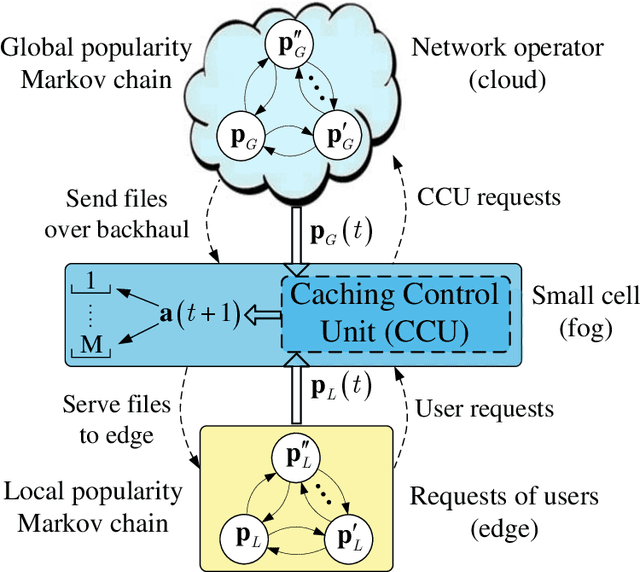
With the tremendous growth of data traffic over wired and wireless networks along with the increasing number of rich-media applications, caching is envisioned to play a critical role in next-generation networks. To intelligently prefetch and store contents, a cache node should be able to learn what and when to cache. Considering the geographical and temporal content popularity dynamics, the limited available storage at cache nodes, as well as the interactive in uence of caching decisions in networked caching settings, developing effective caching policies is practically challenging. In response to these challenges, this chapter presents a versatile reinforcement learning based approach for near-optimal caching policy design, in both single-node and network caching settings under dynamic space-time popularities. The herein presented policies are complemented using a set of numerical tests, which showcase the merits of the presented approach relative to several standard caching policies.
A Statistical Learning Approach to Reactive Power Control in Distribution Systems
Oct 25, 2019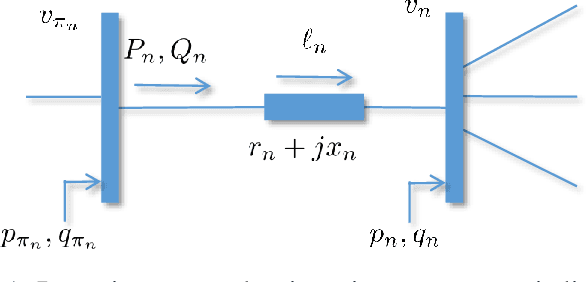
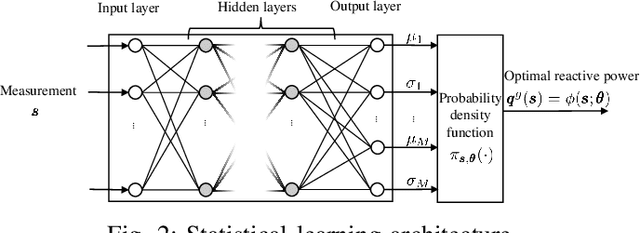
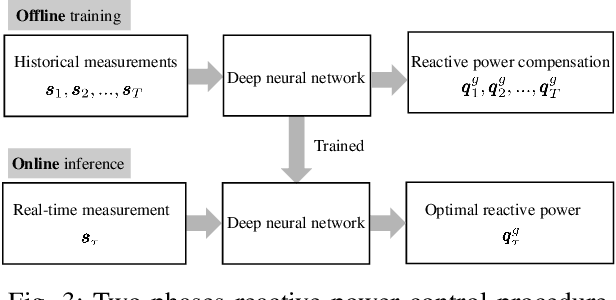
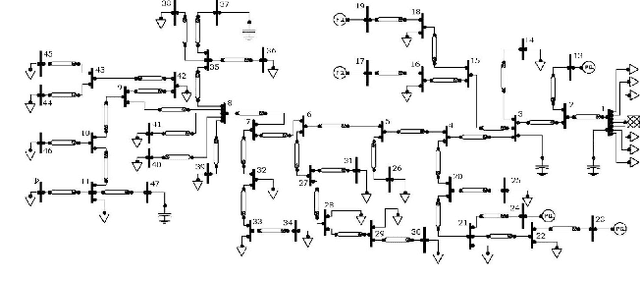
Pronounced variability due to the growth of renewable energy sources, flexible loads, and distributed generation is challenging residential distribution systems. This context, motivates well fast, efficient, and robust reactive power control. Real-time optimal reactive power control is possible in theory by solving a non-convex optimization problem based on the exact model of distribution flow. However, lack of high-precision instrumentation and reliable communications, as well as the heavy computational burden of non-convex optimization solvers render computing and implementing the optimal control challenging in practice. Taking a statistical learning viewpoint, the input-output relationship between each grid state and the corresponding optimal reactive power control is parameterized in the present work by a deep neural network, whose unknown weights are learned offline by minimizing the power loss over a number of historical and simulated training pairs. In the inference phase, one just feeds the real-time state vector into the learned neural network to obtain the `optimal' reactive power control with only several matrix-vector multiplications. The merits of this novel statistical learning approach are computational efficiency as well as robustness to random input perturbations. Numerical tests on a 47-bus distribution network using real data corroborate these practical merits.