 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIL: Self-Improving Efficient Online Alignment of Large Language Models
Jun 21, 2024Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and SLiC rely heavily on fixed preference datasets, which can lead to sub-optimal performance. On the other hand, recent literature has focused on designing online RLHF methods but still lacks a unified conceptual formulation and suffers from distribution shift issues. To address this, we establish that online LLM alignment is underpinned by bilevel optimization. By reducing this formulation to an efficient single-level first-order method (using the reward-policy equivalence), our approach generates new samples and iteratively refines model alignment by exploring responses and regulating preference labels. In doing so, we permit alignment methods to operate in an online and self-improving manner, as well as generalize prior online RLHF methods as special cases. Compared to state-of-the-art iterative RLHF methods, our approach significantly improves alignment performance on open-sourced datasets with minimal computational overhead.
HLDC: Hindi Legal Documents Corpus
Apr 02, 2022

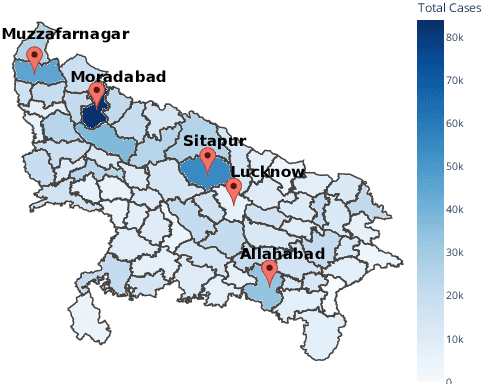
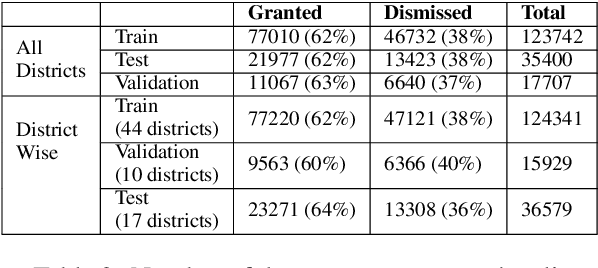
Many populous countries including India are burdened with a considerable backlog of legal cases. Development of automated systems that could process legal documents and augment legal practitioners can mitigate this. However, there is a dearth of high-quality corpora that is needed to develop such data-driven systems. The problem gets even more pronounced in the case of low resource languages such as Hindi. In this resource paper, we introduce the Hindi Legal Documents Corpus (HLDC), a corpus of more than 900K legal documents in Hindi. Documents are cleaned and structured to enable the development of downstream applications. Further, as a use-case for the corpus, we introduce the task of bail prediction. We experiment with a battery of models and propose a Multi-Task Learning (MTL) based model for the same. MTL models use summarization as an auxiliary task along with bail prediction as the main task. Experiments with different models are indicative of the need for further research in this area. We release the corpus and model implementation code with this paper: https://github.com/Exploration-Lab/HLDC