 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCROSS-JEM: Accurate and Efficient Cross-encoders for Short-text Ranking Tasks
Sep 15, 2024Ranking a set of items based on their relevance to a given query is a core problem in search and recommendation. Transformer-based ranking models are the state-of-the-art approaches for such tasks, but they score each query-item independently, ignoring the joint context of other relevant items. This leads to sub-optimal ranking accuracy and high computational costs. In response, we propose Cross-encoders with Joint Efficient Modeling (CROSS-JEM), a novel ranking approach that enables transformer-based models to jointly score multiple items for a query, maximizing parameter utilization. CROSS-JEM leverages (a) redundancies and token overlaps to jointly score multiple items, that are typically short-text phrases arising in search and recommendations, and (b) a novel training objective that models ranking probabilities. CROSS-JEM achieves state-of-the-art accuracy and over 4x lower ranking latency over standard cross-encoders. Our contributions are threefold: (i) we highlight the gap between the ranking application's need for scoring thousands of items per query and the limited capabilities of current cross-encoders; (ii) we introduce CROSS-JEM for joint efficient scoring of multiple items per query; and (iii) we demonstrate state-of-the-art accuracy on standard public datasets and a proprietary dataset. CROSS-JEM opens up new directions for designing tailored early-attention-based ranking models that incorporate strict production constraints such as item multiplicity and latency.
HLDC: Hindi Legal Documents Corpus
Apr 02, 2022

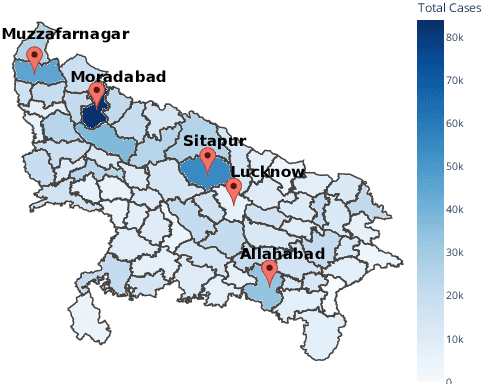
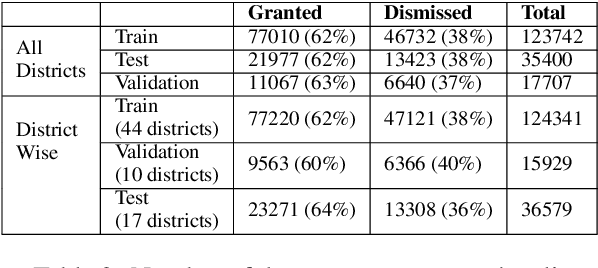
Many populous countries including India are burdened with a considerable backlog of legal cases. Development of automated systems that could process legal documents and augment legal practitioners can mitigate this. However, there is a dearth of high-quality corpora that is needed to develop such data-driven systems. The problem gets even more pronounced in the case of low resource languages such as Hindi. In this resource paper, we introduce the Hindi Legal Documents Corpus (HLDC), a corpus of more than 900K legal documents in Hindi. Documents are cleaned and structured to enable the development of downstream applications. Further, as a use-case for the corpus, we introduce the task of bail prediction. We experiment with a battery of models and propose a Multi-Task Learning (MTL) based model for the same. MTL models use summarization as an auxiliary task along with bail prediction as the main task. Experiments with different models are indicative of the need for further research in this area. We release the corpus and model implementation code with this paper: https://github.com/Exploration-Lab/HLDC
GAME-ON: Graph Attention Network based Multimodal Fusion for Fake News Detection
Mar 01, 2022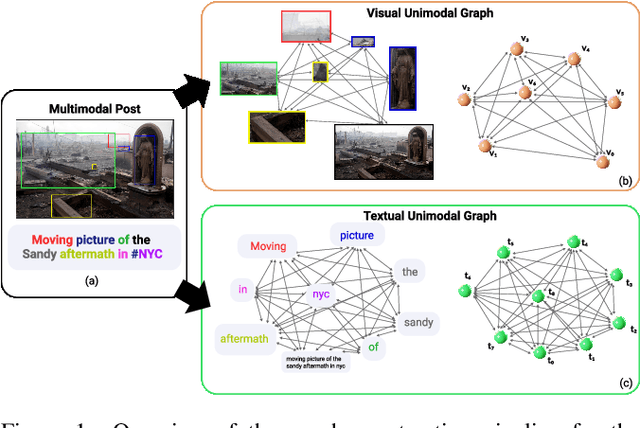
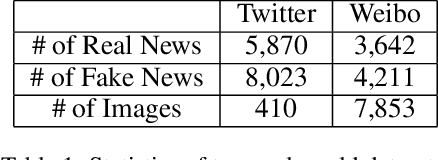

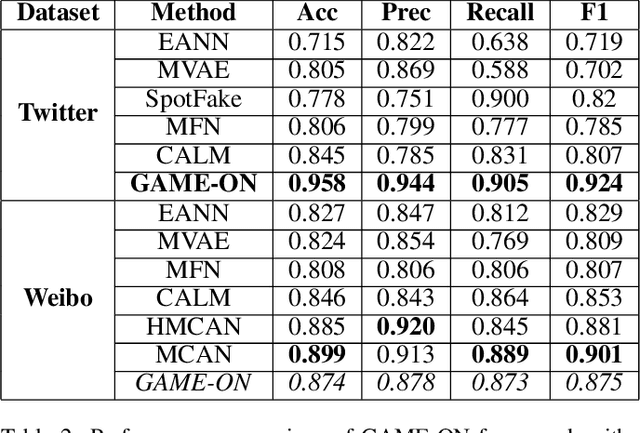
Social media in present times has a significant and growing influence. Fake news being spread on these platforms have a disruptive and damaging impact on our lives. Furthermore, as multimedia content improves the visibility of posts more than text data, it has been observed that often multimedia is being used for creating fake content. A plethora of previous multimodal-based work has tried to address the problem of modeling heterogeneous modalities in identifying fake content. However, these works have the following limitations: (1) inefficient encoding of inter-modal relations by utilizing a simple concatenation operator on the modalities at a later stage in a model, which might result in information loss; (2) training very deep neural networks with a disproportionate number of parameters on small but complex real-life multimodal datasets result in higher chances of overfitting. To address these limitations, we propose GAME-ON, a Graph Neural Network based end-to-end trainable framework that allows granular interactions within and across different modalities to learn more robust data representations for multimodal fake news detection. We use two publicly available fake news datasets, Twitter and Weibo, for evaluations. Our model outperforms on Twitter by an average of 11% and keeps competitive performance on Weibo, within a 2.6% margin, while using 65% fewer parameters than the best comparable state-of-the-art baseline.