 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMIR: Automated MisInformation Rebuttal -- A COVID-19 Vaccination Datasets based Recommendation System
Oct 29, 2023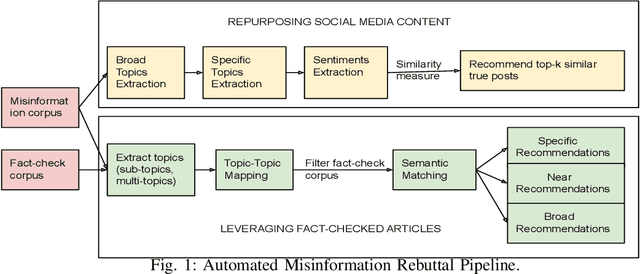
Misinformation has emerged as a major societal threat in recent years in general; specifically in the context of the COVID-19 pandemic, it has wrecked havoc, for instance, by fuelling vaccine hesitancy. Cost-effective, scalable solutions for combating misinformation are the need of the hour. This work explored how existing information obtained from social media and augmented with more curated fact checked data repositories can be harnessed to facilitate automated rebuttal of misinformation at scale. While the ideas herein can be generalized and reapplied in the broader context of misinformation mitigation using a multitude of information sources and catering to the spectrum of social media platforms, this work serves as a proof of concept, and as such, it is confined in its scope to only rebuttal of tweets, and in the specific context of misinformation regarding COVID-19. It leverages two publicly available datasets, viz. FaCov (fact-checked articles) and misleading (social media Twitter) data on COVID-19 Vaccination.
Misinformation Concierge: A Proof-of-Concept with Curated Twitter Dataset on COVID-19 Vaccination
Aug 25, 2023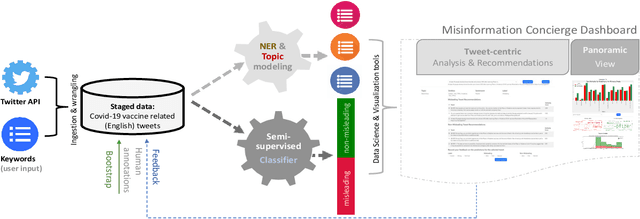
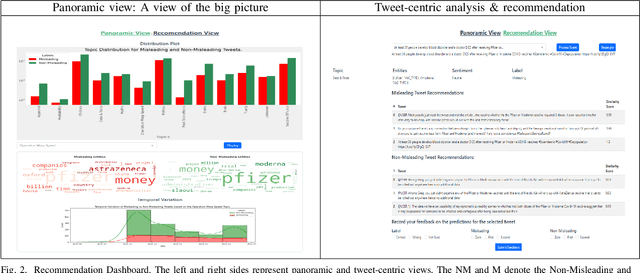
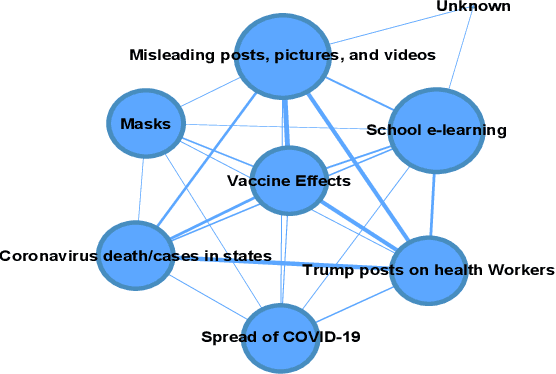
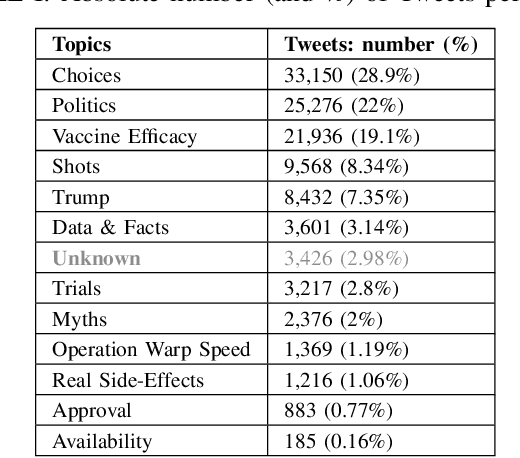
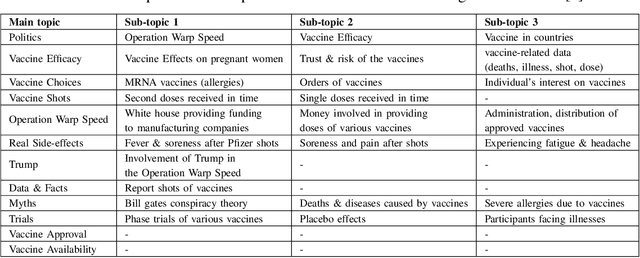
We demonstrate the Misinformation Concierge, a proof-of-concept that provides actionable intelligence on misinformation prevalent in social media. Specifically, it uses language processing and machine learning tools to identify subtopics of discourse and discern non/misleading posts; presents statistical reports for policy-makers to understand the big picture of prevalent misinformation in a timely manner; and recommends rebuttal messages for specific pieces of misinformation, identified from within the corpus of data - providing means to intervene and counter misinformation promptly. The Misinformation Concierge proof-of-concept using a curated dataset is accessible at: https://demo-frontend-uy34.onrender.com/
GAME-ON: Graph Attention Network based Multimodal Fusion for Fake News Detection
Mar 01, 2022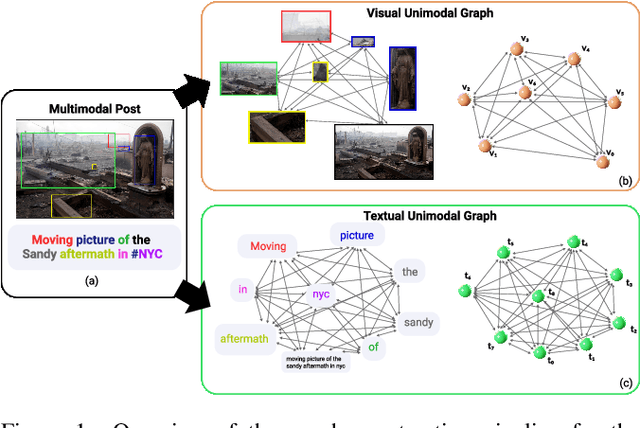
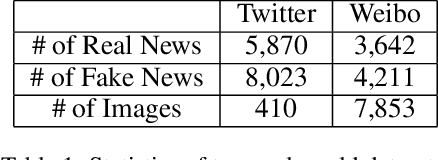

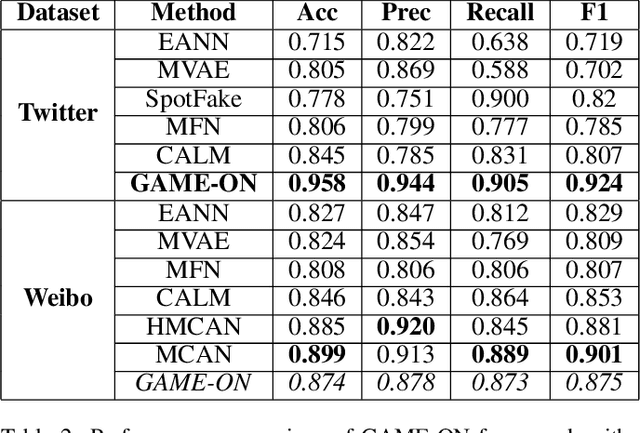
Social media in present times has a significant and growing influence. Fake news being spread on these platforms have a disruptive and damaging impact on our lives. Furthermore, as multimedia content improves the visibility of posts more than text data, it has been observed that often multimedia is being used for creating fake content. A plethora of previous multimodal-based work has tried to address the problem of modeling heterogeneous modalities in identifying fake content. However, these works have the following limitations: (1) inefficient encoding of inter-modal relations by utilizing a simple concatenation operator on the modalities at a later stage in a model, which might result in information loss; (2) training very deep neural networks with a disproportionate number of parameters on small but complex real-life multimodal datasets result in higher chances of overfitting. To address these limitations, we propose GAME-ON, a Graph Neural Network based end-to-end trainable framework that allows granular interactions within and across different modalities to learn more robust data representations for multimodal fake news detection. We use two publicly available fake news datasets, Twitter and Weibo, for evaluations. Our model outperforms on Twitter by an average of 11% and keeps competitive performance on Weibo, within a 2.6% margin, while using 65% fewer parameters than the best comparable state-of-the-art baseline.
Misleading the Covid-19 vaccination discourse on Twitter: An exploratory study of infodemic around the pandemic
Aug 16, 2021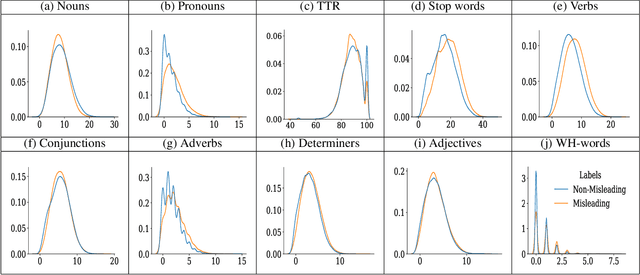
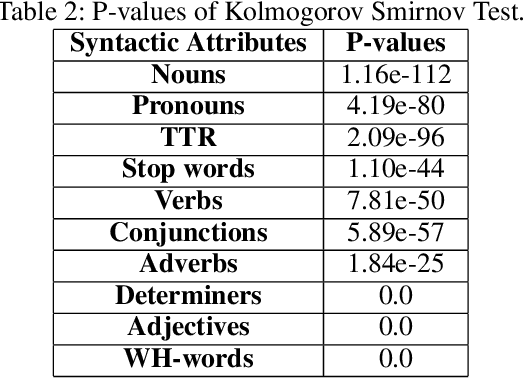
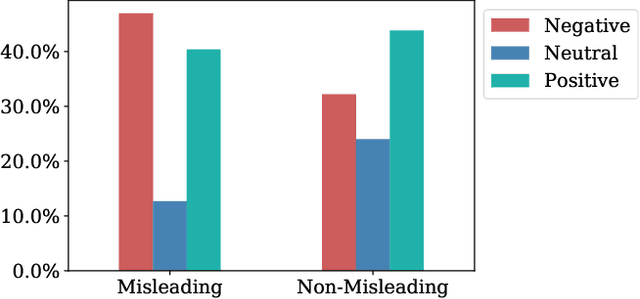
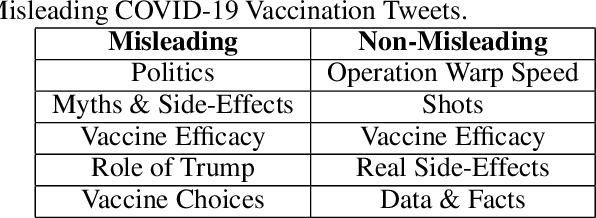
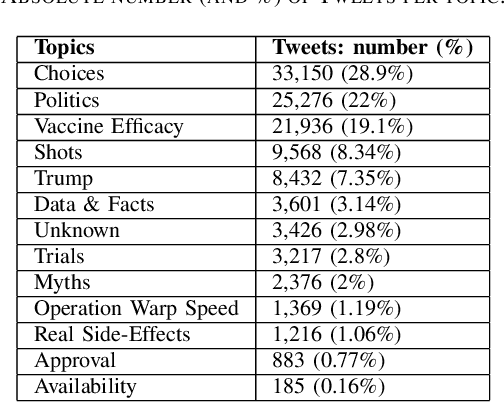
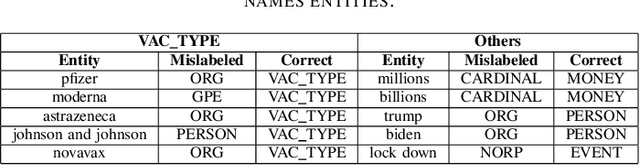
In this work, we collect a moderate-sized representative corpus of tweets (200,000 approx.) pertaining Covid-19 vaccination spanning over a period of seven months (September 2020 - March 2021). Following a Transfer Learning approach, we utilize the pre-trained Transformer-based XLNet model to classify tweets as Misleading or Non-Misleading and validate against a random subset of results manually. We build on this to study and contrast the characteristics of tweets in the corpus that are misleading in nature against non-misleading ones. This exploratory analysis enables us to design features (such as sentiments, hashtags, nouns, pronouns, etc) that can, in turn, be exploited for classifying tweets as (Non-)Misleading using various ML models in an explainable manner. Specifically, several ML models are employed for prediction, with up to 90% accuracy, and the importance of each feature is explained using SHAP Explainable AI (XAI) tool. While the thrust of this work is principally exploratory analysis in order to obtain insights on the online discourse on Covid-19 vaccination, we conclude the paper by outlining how these insights provide the foundations for a more actionable approach to mitigate misinformation. The curated dataset and code is made available (Github repository) so that the research community at large can reproduce, compare against, or build upon this work.
DEAP-FAKED: Knowledge Graph based Approach for Fake News Detection
Jul 04, 2021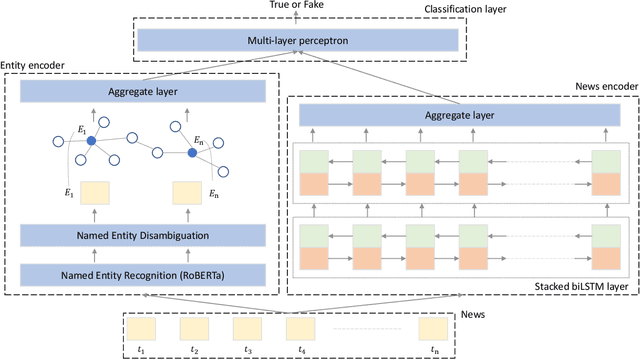


Fake News on social media platforms has attracted a lot of attention in recent times, primarily for events related to politics (2016 US Presidential elections), healthcare (infodemic during COVID-19), to name a few. Various methods have been proposed for detecting Fake News. The approaches span from exploiting techniques related to network analysis, Natural Language Processing (NLP), and the usage of Graph Neural Networks (GNNs). In this work, we propose DEAP-FAKED, a knowleDgE grAPh FAKe nEws Detection framework for identifying Fake News. Our approach is a combination of the NLP -- where we encode the news content, and the GNN technique -- where we encode the Knowledge Graph (KG). A variety of these encodings provides a complementary advantage to our detector. We evaluate our framework using two publicly available datasets containing articles from domains such as politics, business, technology, and healthcare. As part of dataset pre-processing, we also remove the bias, such as the source of the articles, which could impact the performance of the models. DEAP-FAKED obtains an F1-score of 88% and 78% for the two datasets, which is an improvement of 21%, and 3% respectively, which shows the effectiveness of the approach.
Misinformation Detection on YouTube Using Video Captions
Jul 02, 2021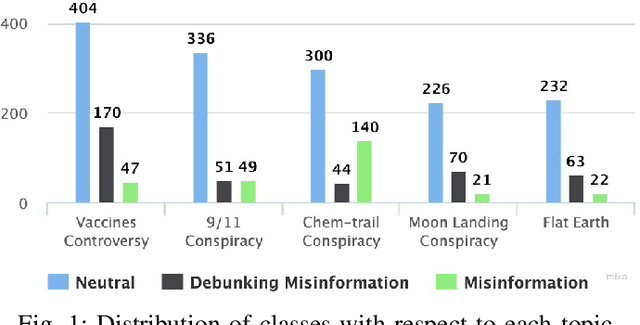

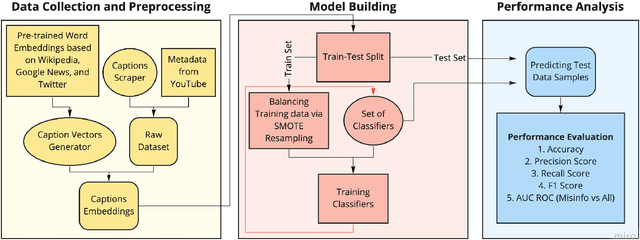
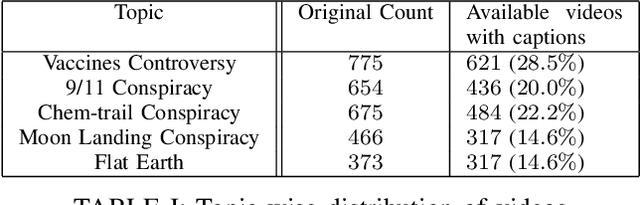
Millions of people use platforms such as YouTube, Facebook, Twitter, and other mass media. Due to the accessibility of these platforms, they are often used to establish a narrative, conduct propaganda, and disseminate misinformation. This work proposes an approach that uses state-of-the-art NLP techniques to extract features from video captions (subtitles). To evaluate our approach, we utilize a publicly accessible and labeled dataset for classifying videos as misinformation or not. The motivation behind exploring video captions stems from our analysis of videos metadata. Attributes such as the number of views, likes, dislikes, and comments are ineffective as videos are hard to differentiate using this information. Using caption dataset, the proposed models can classify videos among three classes (Misinformation, Debunking Misinformation, and Neutral) with 0.85 to 0.90 F1-score. To emphasize the relevance of the misinformation class, we re-formulate our classification problem as a two-class classification - Misinformation vs. others (Debunking Misinformation and Neutral). In our experiments, the proposed models can classify videos with 0.92 to 0.95 F1-score and 0.78 to 0.90 AUC ROC.
A Graph Neural Network based approach for detecting Suspicious Users on Online Social Media
Oct 15, 2020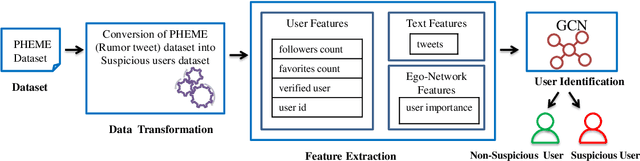



Online Social Media platforms (such as Twitter and Facebook) are extensively used for spreading the news to a wider public effortlessly at a rapid pace. However, now a days these platforms are also used with an aim of spreading rumors and fake news to a large audience in a short time span that can cause panic, fear, and financial loss to society. Thus, it is important to detect and control these rumors before it spreads to the masses. One way to control the spread of these rumors is by identifying possible suspicious users who are often involved in spreading the rumors. Our basic assumption is that the users who are often involved in spreading rumors are more likely to be suspicious in contrast to the users whose involvement in spreading rumors are less. This is due to the fact that sometimes, users may posts the rumor tweets by accident. In this paper, we use PHEME rumor tweet dataset which contains rumor and non-rumor tweets information on five incidents, that is, i) Charlie hebdo, ii)German wings crash, iii)Ottawa shooting, iv)Sydney siege, and v)Ferguson. We transform this rumor tweets dataset into suspicious users dataset before leveraging Graph Neural Network (GNN) based approach for identifying suspicious users. Specifically, we explore Graph Convolutional Network (GCN),which is a type of GNN, for identifying suspicious users and then we compare GCN results with the other three approaches which act as baseline approaches: SVM, RF and LSTM based deep learning architecture. Extensive experiments performed on real-world dataset, where we achieve up to 0.864 value for F1-Score and 0.720 value for AUC ROC, shows the effectiveness of GNN based approach for identifying suspicious users.