 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisinformation Detection on YouTube Using Video Captions
Jul 02, 2021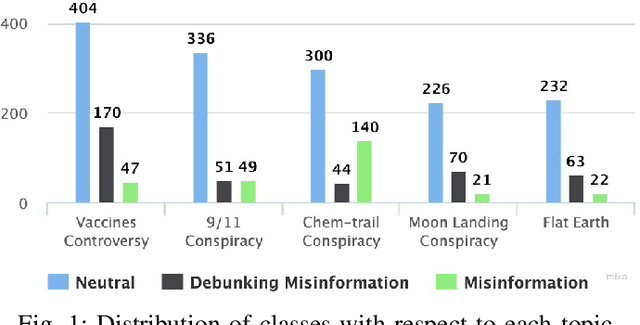

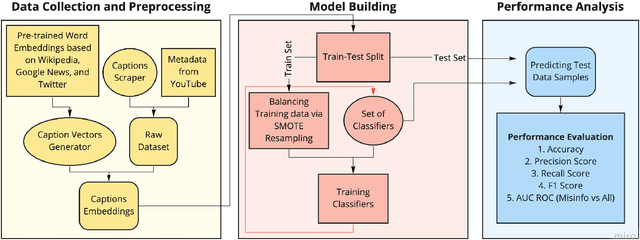
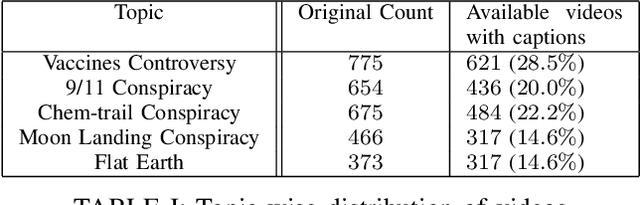
Millions of people use platforms such as YouTube, Facebook, Twitter, and other mass media. Due to the accessibility of these platforms, they are often used to establish a narrative, conduct propaganda, and disseminate misinformation. This work proposes an approach that uses state-of-the-art NLP techniques to extract features from video captions (subtitles). To evaluate our approach, we utilize a publicly accessible and labeled dataset for classifying videos as misinformation or not. The motivation behind exploring video captions stems from our analysis of videos metadata. Attributes such as the number of views, likes, dislikes, and comments are ineffective as videos are hard to differentiate using this information. Using caption dataset, the proposed models can classify videos among three classes (Misinformation, Debunking Misinformation, and Neutral) with 0.85 to 0.90 F1-score. To emphasize the relevance of the misinformation class, we re-formulate our classification problem as a two-class classification - Misinformation vs. others (Debunking Misinformation and Neutral). In our experiments, the proposed models can classify videos with 0.92 to 0.95 F1-score and 0.78 to 0.90 AUC ROC.