 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine unlearning through fine-grained model parameters perturbation
Jan 09, 2024Machine unlearning techniques, which involve retracting data records and reducing influence of said data on trained models, help with the user privacy protection objective but incur significant computational costs. Weight perturbation-based unlearning is a general approach, but it typically involves globally modifying the parameters. We propose fine-grained Top-K and Random-k parameters perturbed inexact machine unlearning strategies that address the privacy needs while keeping the computational costs tractable. In order to demonstrate the efficacy of our strategies we also tackle the challenge of evaluating the effectiveness of machine unlearning by considering the model's generalization performance across both unlearning and remaining data. To better assess the unlearning effect and model generalization, we propose novel metrics, namely, the forgetting rate and memory retention rate. However, for inexact machine unlearning, current metrics are inadequate in quantifying the degree of forgetting that occurs after unlearning strategies are applied. To address this, we introduce SPD-GAN, which subtly perturbs the distribution of data targeted for unlearning. Then, we evaluate the degree of unlearning by measuring the performance difference of the models on the perturbed unlearning data before and after the unlearning process. By implementing these innovative techniques and metrics, we achieve computationally efficacious privacy protection in machine learning applications without significant sacrifice of model performance. Furthermore, this approach provides a novel method for evaluating the degree of unlearning.
eCIL-MU: Embedding based Class Incremental Learning and Machine Unlearning
Jan 04, 2024



New categories may be introduced over time, or existing categories may need to be reclassified. Class incremental learning (CIL) is employed for the gradual acquisition of knowledge about new categories while preserving information about previously learned ones in such dynamic environments. It might also be necessary to also eliminate the influence of related categories on the model to adapt to reclassification. We thus introduce class-level machine unlearning (MU) within CIL. Typically, MU methods tend to be time-consuming and can potentially harm the model's performance. A continuous stream of unlearning requests could lead to catastrophic forgetting. To address these issues, we propose a non-destructive eCIL-MU framework based on embedding techniques to map data into vectors and then be stored in vector databases. Our approach exploits the overlap between CIL and MU tasks for acceleration. Experiments demonstrate the capability of achieving unlearning effectiveness and orders of magnitude (upto $\sim 278\times$) of acceleration.
AMIR: Automated MisInformation Rebuttal -- A COVID-19 Vaccination Datasets based Recommendation System
Oct 29, 2023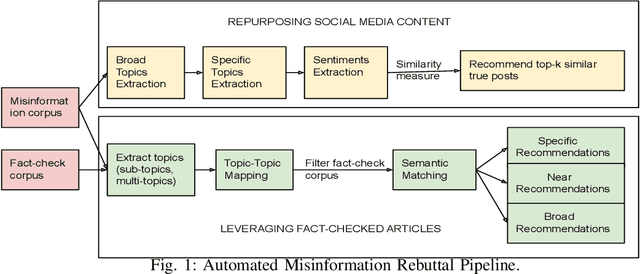
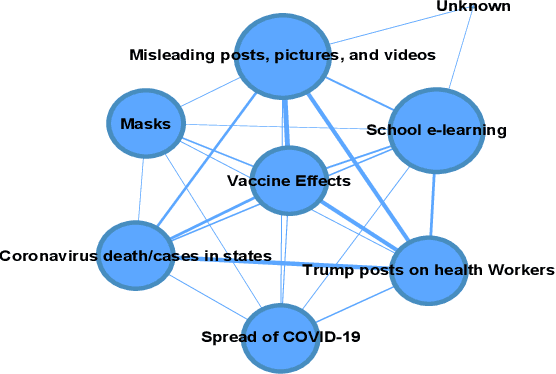
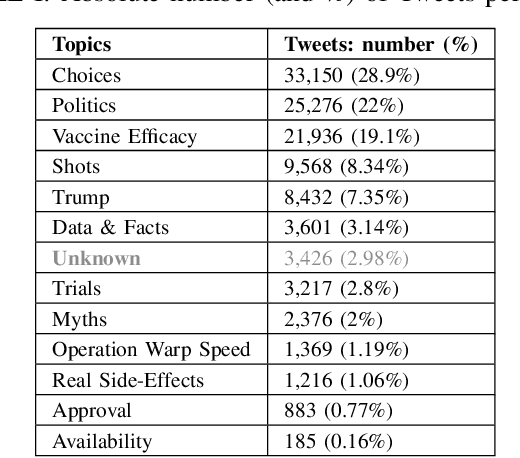
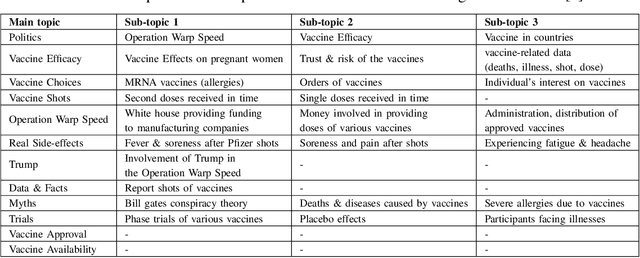
Misinformation has emerged as a major societal threat in recent years in general; specifically in the context of the COVID-19 pandemic, it has wrecked havoc, for instance, by fuelling vaccine hesitancy. Cost-effective, scalable solutions for combating misinformation are the need of the hour. This work explored how existing information obtained from social media and augmented with more curated fact checked data repositories can be harnessed to facilitate automated rebuttal of misinformation at scale. While the ideas herein can be generalized and reapplied in the broader context of misinformation mitigation using a multitude of information sources and catering to the spectrum of social media platforms, this work serves as a proof of concept, and as such, it is confined in its scope to only rebuttal of tweets, and in the specific context of misinformation regarding COVID-19. It leverages two publicly available datasets, viz. FaCov (fact-checked articles) and misleading (social media Twitter) data on COVID-19 Vaccination.
Misinformation Concierge: A Proof-of-Concept with Curated Twitter Dataset on COVID-19 Vaccination
Aug 25, 2023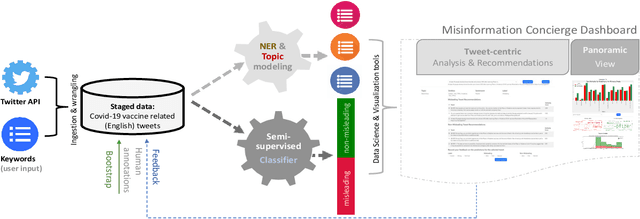
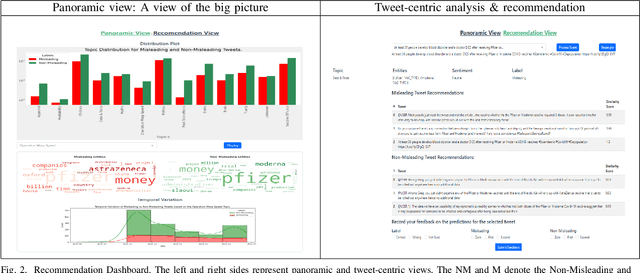
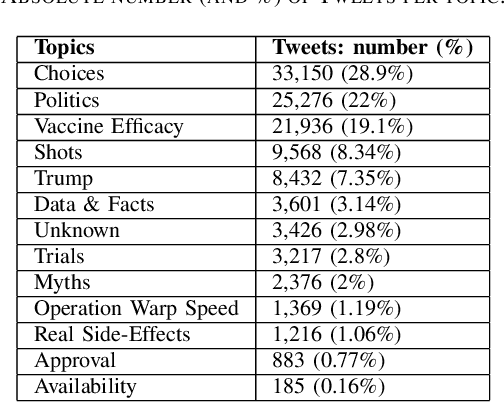
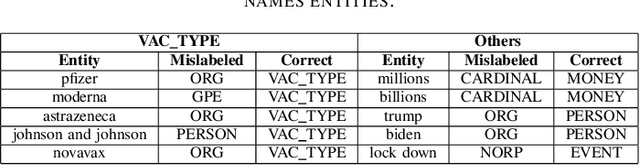
We demonstrate the Misinformation Concierge, a proof-of-concept that provides actionable intelligence on misinformation prevalent in social media. Specifically, it uses language processing and machine learning tools to identify subtopics of discourse and discern non/misleading posts; presents statistical reports for policy-makers to understand the big picture of prevalent misinformation in a timely manner; and recommends rebuttal messages for specific pieces of misinformation, identified from within the corpus of data - providing means to intervene and counter misinformation promptly. The Misinformation Concierge proof-of-concept using a curated dataset is accessible at: https://demo-frontend-uy34.onrender.com/
A Modular Framework for Centrality and Clustering in Complex Networks
Nov 23, 2021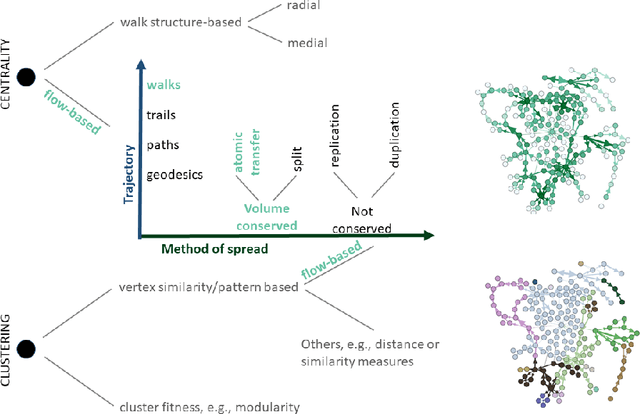

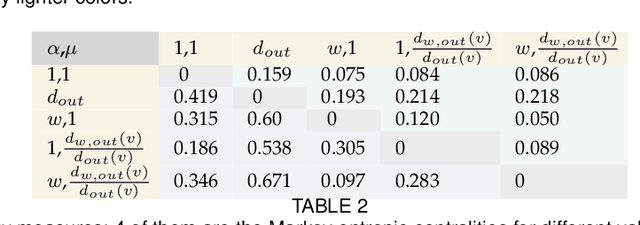
The structure of many complex networks includes edge directionality and weights on top of their topology. Network analysis that can seamlessly consider combination of these properties are desirable. In this paper, we study two important such network analysis techniques, namely, centrality and clustering. An information-flow based model is adopted for clustering, which itself builds upon an information theoretic measure for computing centrality. Our principal contributions include a generalized model of Markov entropic centrality with the flexibility to tune the importance of node degrees, edge weights and directions, with a closed-form asymptotic analysis. It leads to a novel two-stage graph clustering algorithm. The centrality analysis helps reason about the suitability of our approach to cluster a given graph, and determine `query' nodes, around which to explore local community structures, leading to an agglomerative clustering mechanism. The entropic centrality computations are amortized by our clustering algorithm, making it computationally efficient: compared to prior approaches using Markov entropic centrality for clustering, our experiments demonstrate multiple orders of magnitude of speed-up. Our clustering algorithm naturally inherits the flexibility to accommodate edge directionality, as well as different interpretations and interplay between edge weights and node degrees. Overall, this paper thus not only makes significant theoretical and conceptual contributions, but also translates the findings into artifacts of practical relevance, yielding new, effective and scalable centrality computations and graph clustering algorithms, whose efficacy has been validated through extensive benchmarking experiments.
Misleading the Covid-19 vaccination discourse on Twitter: An exploratory study of infodemic around the pandemic
Aug 16, 2021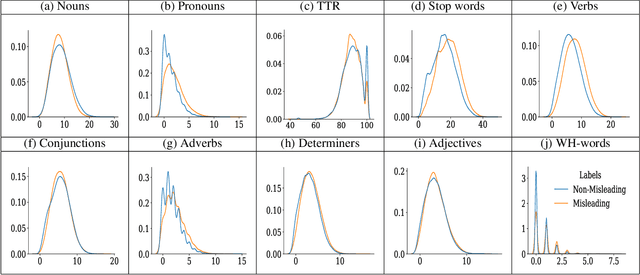
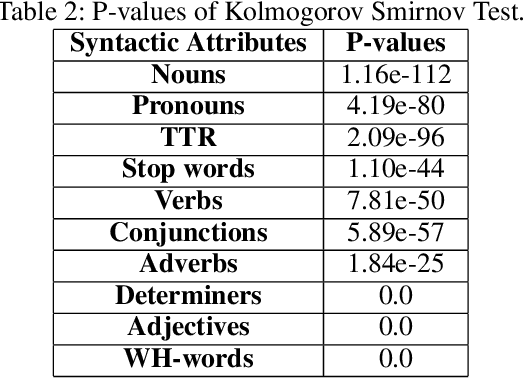
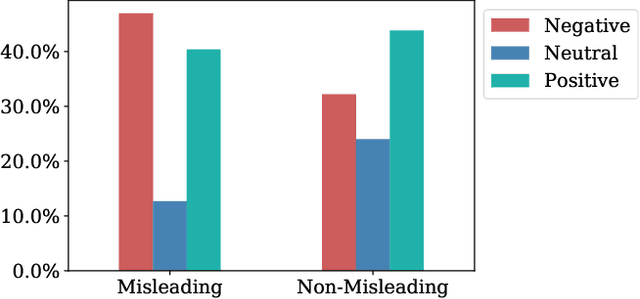
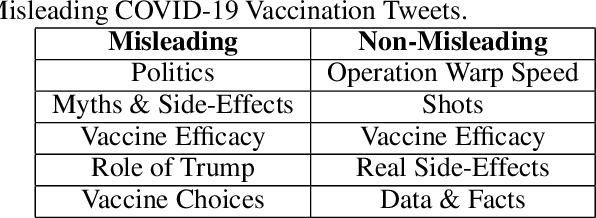
In this work, we collect a moderate-sized representative corpus of tweets (200,000 approx.) pertaining Covid-19 vaccination spanning over a period of seven months (September 2020 - March 2021). Following a Transfer Learning approach, we utilize the pre-trained Transformer-based XLNet model to classify tweets as Misleading or Non-Misleading and validate against a random subset of results manually. We build on this to study and contrast the characteristics of tweets in the corpus that are misleading in nature against non-misleading ones. This exploratory analysis enables us to design features (such as sentiments, hashtags, nouns, pronouns, etc) that can, in turn, be exploited for classifying tweets as (Non-)Misleading using various ML models in an explainable manner. Specifically, several ML models are employed for prediction, with up to 90% accuracy, and the importance of each feature is explained using SHAP Explainable AI (XAI) tool. While the thrust of this work is principally exploratory analysis in order to obtain insights on the online discourse on Covid-19 vaccination, we conclude the paper by outlining how these insights provide the foundations for a more actionable approach to mitigate misinformation. The curated dataset and code is made available (Github repository) so that the research community at large can reproduce, compare against, or build upon this work.
A generic trust framework for large-scale open systems using machine learning
Mar 01, 2011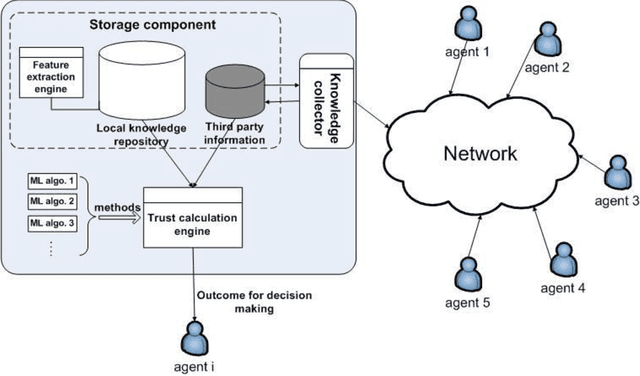
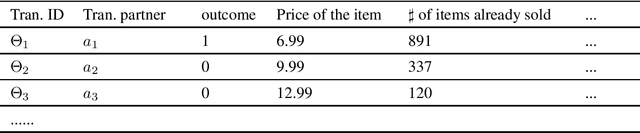
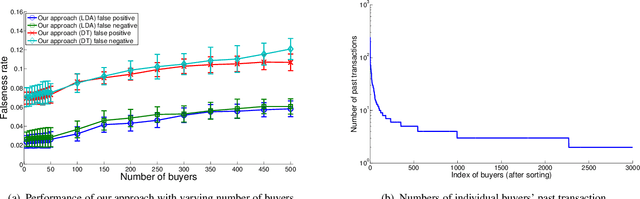
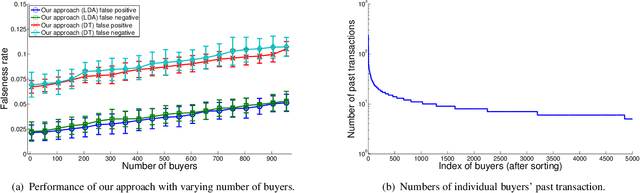
In many large scale distributed systems and on the web, agents need to interact with other unknown agents to carry out some tasks or transactions. The ability to reason about and assess the potential risks in carrying out such transactions is essential for providing a safe and reliable environment. A traditional approach to reason about the trustworthiness of a transaction is to determine the trustworthiness of the specific agent involved, derived from the history of its behavior. As a departure from such traditional trust models, we propose a generic, machine learning approach based trust framework where an agent uses its own previous transactions (with other agents) to build a knowledge base, and utilize this to assess the trustworthiness of a transaction based on associated features, which are capable of distinguishing successful transactions from unsuccessful ones. These features are harnessed using appropriate machine learning algorithms to extract relationships between the potential transaction and previous transactions. The trace driven experiments using real auction dataset show that this approach provides good accuracy and is highly efficient compared to other trust mechanisms, especially when historical information of the specific agent is rare, incomplete or inaccurate.