 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Indexing KVCache: Predicting Sparse Attention from Compressed Keys
Mar 15, 2026The KV cache in self-attention has emerged as a major bottleneck in long-context and large-batch inference for LLMs. Existing approaches often treat sparsity prediction and compression as separate modules, relying on auxiliary index structures to select relevant tokens, and on complex quantization schemes to reduce memory usage. This fragmented design introduces redundant overhead and limits scalability. In this paper, we propose a novel paradigm: treating the compressed key representation not merely as storage, but as a self-indexing structure that directly enables efficient sparse attention. By designing a sign-based 1-bit vector quantization (VQ) scheme, our method unifies compression and retrieval in a single, hardware-friendly format. This approach eliminates the need for external indices or learning-based predictors, offering a lightweight yet robust solution for memory-constrained inference. All components are designed to be hardware-efficient and easy to implement. By implementing custom CUDA kernels, our method integrates seamlessly with FlashAttention, minimizing additional runtime and memory overhead. Experimental results demonstrate that our approach delivers both effectiveness and efficiency.
CausalTAD: Injecting Causal Knowledge into Large Language Models for Tabular Anomaly Detection
Feb 08, 2026Detecting anomalies in tabular data is critical for many real-world applications, such as credit card fraud detection. With the rapid advancements in large language models (LLMs), state-of-the-art performance in tabular anomaly detection has been achieved by converting tabular data into text and fine-tuning LLMs. However, these methods randomly order columns during conversion, without considering the causal relationships between them, which is crucial for accurately detecting anomalies. In this paper, we present CausalTaD, a method that injects causal knowledge into LLMs for tabular anomaly detection. We first identify the causal relationships between columns and reorder them to align with these causal relationships. This reordering can be modeled as a linear ordering problem. Since each column contributes differently to the causal relationships, we further propose a reweighting strategy to assign different weights to different columns to enhance this effect. Experiments across more than 30 datasets demonstrate that our method consistently outperforms the current state-of-the-art methods. The code for CausalTAD is available at https://github.com/350234/CausalTAD.
Invisible Clean-Label Backdoor Attacks for Generative Data Augmentation
Feb 03, 2026With the rapid advancement of image generative models, generative data augmentation has become an effective way to enrich training images, especially when only small-scale datasets are available. At the same time, in practical applications, generative data augmentation can be vulnerable to clean-label backdoor attacks, which aim to bypass human inspection. However, based on theoretical analysis and preliminary experiments, we observe that directly applying existing pixel-level clean-label backdoor attack methods (e.g., COMBAT) to generated images results in low attack success rates. This motivates us to move beyond pixel-level triggers and focus instead on the latent feature level. To this end, we propose InvLBA, an invisible clean-label backdoor attack method for generative data augmentation by latent perturbation. We theoretically prove that the generalization of the clean accuracy and attack success rates of InvLBA can be guaranteed. Experiments on multiple datasets show that our method improves the attack success rate by 46.43% on average, with almost no reduction in clean accuracy and high robustness against SOTA defense methods.
LiNeXt: Revisiting LiDAR Completion with Efficient Non-Diffusion Architectures
Nov 13, 20253D LiDAR scene completion from point clouds is a fundamental component of perception systems in autonomous vehicles. Previous methods have predominantly employed diffusion models for high-fidelity reconstruction. However, their multi-step iterative sampling incurs significant computational overhead, limiting its real-time applicability. To address this, we propose LiNeXt-a lightweight, non-diffusion network optimized for rapid and accurate point cloud completion. Specifically, LiNeXt first applies the Noise-to-Coarse (N2C) Module to denoise the input noisy point cloud in a single pass, thereby obviating the multi-step iterative sampling of diffusion-based methods. The Refine Module then takes the coarse point cloud and its intermediate features from the N2C Module to perform more precise refinement, further enhancing structural completeness. Furthermore, we observe that LiDAR point clouds exhibit a distance-dependent spatial distribution, being densely sampled at proximal ranges and sparsely sampled at distal ranges. Accordingly, we propose the Distance-aware Selected Repeat strategy to generate a more uniformly distributed noisy point cloud. On the SemanticKITTI dataset, LiNeXt achieves a 199.8x speedup in inference, reduces Chamfer Distance by 50.7%, and uses only 6.1% of the parameters compared with LiDiff. These results demonstrate the superior efficiency and effectiveness of LiNeXt for real-time scene completion.
Self-Supervised Point Cloud Completion based on Multi-View Augmentations of Single Partial Point Cloud
Sep 26, 2025Point cloud completion aims to reconstruct complete shapes from partial observations. Although current methods have achieved remarkable performance, they still have some limitations: Supervised methods heavily rely on ground truth, which limits their generalization to real-world datasets due to the synthetic-to-real domain gap. Unsupervised methods require complete point clouds to compose unpaired training data, and weakly-supervised methods need multi-view observations of the object. Existing self-supervised methods frequently produce unsatisfactory predictions due to the limited capabilities of their self-supervised signals. To overcome these challenges, we propose a novel self-supervised point cloud completion method. We design a set of novel self-supervised signals based on multi-view augmentations of the single partial point cloud. Additionally, to enhance the model's learning ability, we first incorporate Mamba into self-supervised point cloud completion task, encouraging the model to generate point clouds with better quality. Experiments on synthetic and real-world datasets demonstrate that our method achieves state-of-the-art results.
Enhancing Small-Scale Dataset Expansion with Triplet-Connection-based Sample Re-Weighting
Aug 11, 2025The performance of computer vision models in certain real-world applications, such as medical diagnosis, is often limited by the scarcity of available images. Expanding datasets using pre-trained generative models is an effective solution. However, due to the uncontrollable generation process and the ambiguity of natural language, noisy images may be generated. Re-weighting is an effective way to address this issue by assigning low weights to such noisy images. We first theoretically analyze three types of supervision for the generated images. Based on the theoretical analysis, we develop TriReWeight, a triplet-connection-based sample re-weighting method to enhance generative data augmentation. Theoretically, TriReWeight can be integrated with any generative data augmentation methods and never downgrade their performance. Moreover, its generalization approaches the optimal in the order $O(\sqrt{d\ln (n)/n})$. Our experiments validate the correctness of the theoretical analysis and demonstrate that our method outperforms the existing SOTA methods by $7.9\%$ on average over six natural image datasets and by $3.4\%$ on average over three medical datasets. We also experimentally validate that our method can enhance the performance of different generative data augmentation methods.
Interactive Hybrid Rice Breeding with Parametric Dual Projection
Jul 16, 2025



Hybrid rice breeding crossbreeds different rice lines and cultivates the resulting hybrids in fields to select those with desirable agronomic traits, such as higher yields. Recently, genomic selection has emerged as an efficient way for hybrid rice breeding. It predicts the traits of hybrids based on their genes, which helps exclude many undesired hybrids, largely reducing the workload of field cultivation. However, due to the limited accuracy of genomic prediction models, breeders still need to combine their experience with the models to identify regulatory genes that control traits and select hybrids, which remains a time-consuming process. To ease this process, in this paper, we proposed a visual analysis method to facilitate interactive hybrid rice breeding. Regulatory gene identification and hybrid selection naturally ensemble a dual-analysis task. Therefore, we developed a parametric dual projection method with theoretical guarantees to facilitate interactive dual analysis. Based on this dual projection method, we further developed a gene visualization and a hybrid visualization to verify the identified regulatory genes and hybrids. The effectiveness of our method is demonstrated through the quantitative evaluation of the parametric dual projection method, identified regulatory genes and desired hybrids in the case study, and positive feedback from breeders.
VLScene: Vision-Language Guidance Distillation for Camera-Based 3D Semantic Scene Completion
Mar 08, 2025Camera-based 3D semantic scene completion (SSC) provides dense geometric and semantic perception for autonomous driving. However, images provide limited information making the model susceptible to geometric ambiguity caused by occlusion and perspective distortion. Existing methods often lack explicit semantic modeling between objects, limiting their perception of 3D semantic context. To address these challenges, we propose a novel method VLScene: Vision-Language Guidance Distillation for Camera-based 3D Semantic Scene Completion. The key insight is to use the vision-language model to introduce high-level semantic priors to provide the object spatial context required for 3D scene understanding. Specifically, we design a vision-language guidance distillation process to enhance image features, which can effectively capture semantic knowledge from the surrounding environment and improve spatial context reasoning. In addition, we introduce a geometric-semantic sparse awareness mechanism to propagate geometric structures in the neighborhood and enhance semantic information through contextual sparse interactions. Experimental results demonstrate that VLScene achieves rank-1st performance on challenging benchmarks--SemanticKITTI and SSCBench-KITTI-360, yielding remarkably mIoU scores of 17.52 and 19.10, respectively.
Vision-based 3D Semantic Scene Completion via Capture Dynamic Representations
Mar 08, 2025The vision-based semantic scene completion task aims to predict dense geometric and semantic 3D scene representations from 2D images. However, the presence of dynamic objects in the scene seriously affects the accuracy of the model inferring 3D structures from 2D images. Existing methods simply stack multiple frames of image input to increase dense scene semantic information, but ignore the fact that dynamic objects and non-texture areas violate multi-view consistency and matching reliability. To address these issues, we propose a novel method, CDScene: Vision-based Robust Semantic Scene Completion via Capturing Dynamic Representations. First, we leverage a multimodal large-scale model to extract 2D explicit semantics and align them into 3D space. Second, we exploit the characteristics of monocular and stereo depth to decouple scene information into dynamic and static features. The dynamic features contain structural relationships around dynamic objects, and the static features contain dense contextual spatial information. Finally, we design a dynamic-static adaptive fusion module to effectively extract and aggregate complementary features, achieving robust and accurate semantic scene completion in autonomous driving scenarios. Extensive experimental results on the SemanticKITTI, SSCBench-KITTI360, and SemanticKITTI-C datasets demonstrate the superiority and robustness of CDScene over existing state-of-the-art methods.
Learning Temporal 3D Semantic Scene Completion via Optical Flow Guidance
Feb 20, 2025


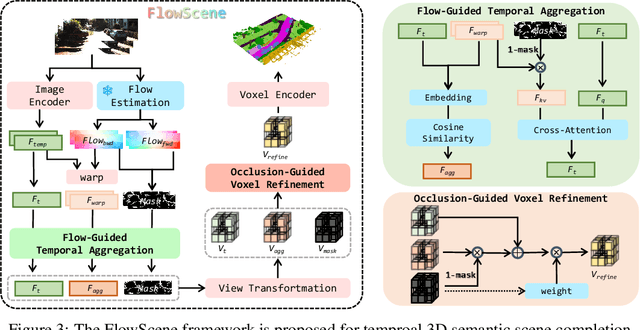
3D Semantic Scene Completion (SSC) provides comprehensive scene geometry and semantics for autonomous driving perception, which is crucial for enabling accurate and reliable decision-making. However, existing SSC methods are limited to capturing sparse information from the current frame or naively stacking multi-frame temporal features, thereby failing to acquire effective scene context. These approaches ignore critical motion dynamics and struggle to achieve temporal consistency. To address the above challenges, we propose a novel temporal SSC method FlowScene: Learning Temporal 3D Semantic Scene Completion via Optical Flow Guidance. By leveraging optical flow, FlowScene can integrate motion, different viewpoints, occlusions, and other contextual cues, thereby significantly improving the accuracy of 3D scene completion. Specifically, our framework introduces two key components: (1) a Flow-Guided Temporal Aggregation module that aligns and aggregates temporal features using optical flow, capturing motion-aware context and deformable structures; and (2) an Occlusion-Guided Voxel Refinement module that injects occlusion masks and temporally aggregated features into 3D voxel space, adaptively refining voxel representations for explicit geometric modeling. Experimental results demonstrate that FlowScene achieves state-of-the-art performance on the SemanticKITTI and SSCBench-KITTI-360 benchmarks.