 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Replace Reduction: An effective visual token reduction method via semantic match
Paper and Code
Oct 09, 2024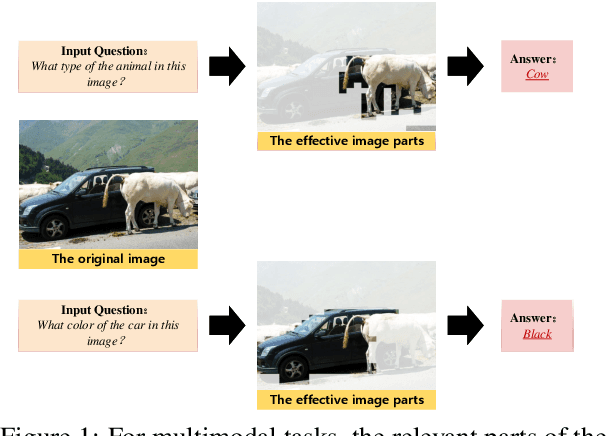

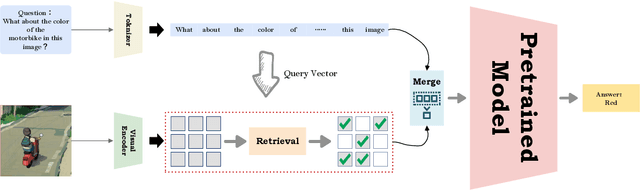

Multimodal large language models (MLLMs) have demonstrated strong performance across various tasks without requiring training from scratch. However, they face significant computational and memory constraints, particularly when processing multimodal inputs that exceed context length, limiting their scalability. In this paper, we introduce a new approach, \textbf{TRSM} (\textbf{T}oken \textbf{R}eduction via \textbf{S}emantic \textbf{M}atch), which effectively reduces the number of visual tokens without compromising MLLM performance. Inspired by how humans process multimodal tasks, TRSM leverages semantic information from one modality to match relevant semantics in another, reducing the number of visual tokens.Specifically, to retain task relevant visual tokens, we use the text prompt as a query vector to retrieve the most similar vectors from the visual prompt and merge them with the text tokens. Based on experimental results, when applied to LLaVA-1.5\cite{liu2023}, our approach compresses the visual tokens by 20\%, achieving comparable performance across diverse visual question-answering and reasoning tasks.