 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoomPilot: Controllable Synthesis of Interactive Indoor Environments via Multimodal Semantic Parsing
Dec 12, 2025



Generating controllable and interactive indoor scenes is fundamental to applications in game development, architectural visualization, and embodied AI training. Yet existing approaches either handle a narrow range of input modalities or rely on stochastic processes that hinder controllability. To overcome these limitations, we introduce RoomPilot, a unified framework that parses diverse multi-modal inputs--textual descriptions or CAD floor plans--into an Indoor Domain-Specific Language (IDSL) for indoor structured scene generation. The key insight is that a well-designed IDSL can act as a shared semantic representation, enabling coherent, high-quality scene synthesis from any single modality while maintaining interaction semantics. In contrast to conventional procedural methods that produce visually plausible but functionally inert layouts, RoomPilot leverages a curated dataset of interaction-annotated assets to synthesize environments exhibiting realistic object behaviors. Extensive experiments further validate its strong multi-modal understanding, fine-grained controllability in scene generation, and superior physical consistency and visual fidelity, marking a significant step toward general-purpose controllable 3D indoor scene generation.
LiNeXt: Revisiting LiDAR Completion with Efficient Non-Diffusion Architectures
Nov 13, 20253D LiDAR scene completion from point clouds is a fundamental component of perception systems in autonomous vehicles. Previous methods have predominantly employed diffusion models for high-fidelity reconstruction. However, their multi-step iterative sampling incurs significant computational overhead, limiting its real-time applicability. To address this, we propose LiNeXt-a lightweight, non-diffusion network optimized for rapid and accurate point cloud completion. Specifically, LiNeXt first applies the Noise-to-Coarse (N2C) Module to denoise the input noisy point cloud in a single pass, thereby obviating the multi-step iterative sampling of diffusion-based methods. The Refine Module then takes the coarse point cloud and its intermediate features from the N2C Module to perform more precise refinement, further enhancing structural completeness. Furthermore, we observe that LiDAR point clouds exhibit a distance-dependent spatial distribution, being densely sampled at proximal ranges and sparsely sampled at distal ranges. Accordingly, we propose the Distance-aware Selected Repeat strategy to generate a more uniformly distributed noisy point cloud. On the SemanticKITTI dataset, LiNeXt achieves a 199.8x speedup in inference, reduces Chamfer Distance by 50.7%, and uses only 6.1% of the parameters compared with LiDiff. These results demonstrate the superior efficiency and effectiveness of LiNeXt for real-time scene completion.
RWKV-PCSSC: Exploring RWKV Model for Point Cloud Semantic Scene Completion
Nov 13, 2025



Semantic Scene Completion (SSC) aims to generate a complete semantic scene from an incomplete input. Existing approaches often employ dense network architectures with a high parameter count, leading to increased model complexity and resource demands. To address these limitations, we propose RWKV-PCSSC, a lightweight point cloud semantic scene completion network inspired by the Receptance Weighted Key Value (RWKV) mechanism. Specifically, we introduce a RWKV Seed Generator (RWKV-SG) module that can aggregate features from a partial point cloud to produce a coarse point cloud with coarse features. Subsequently, the point-wise feature of the point cloud is progressively restored through multiple stages of the RWKV Point Deconvolution (RWKV-PD) modules. By leveraging a compact and efficient design, our method achieves a lightweight model representation. Experimental results demonstrate that RWKV-PCSSC reduces the parameter count by 4.18$\times$ and improves memory efficiency by 1.37$\times$ compared to state-of-the-art methods PointSSC. Furthermore, our network achieves state-of-the-art performance on established indoor (SSC-PC, NYUCAD-PC) and outdoor (PointSSC) scene dataset, as well as on our proposed datasets (NYUCAD-PC-V2, 3D-FRONT-PC).
* 13 pages, 8 figures, published to ACM MM
Self-Supervised Point Cloud Completion based on Multi-View Augmentations of Single Partial Point Cloud
Sep 26, 2025Point cloud completion aims to reconstruct complete shapes from partial observations. Although current methods have achieved remarkable performance, they still have some limitations: Supervised methods heavily rely on ground truth, which limits their generalization to real-world datasets due to the synthetic-to-real domain gap. Unsupervised methods require complete point clouds to compose unpaired training data, and weakly-supervised methods need multi-view observations of the object. Existing self-supervised methods frequently produce unsatisfactory predictions due to the limited capabilities of their self-supervised signals. To overcome these challenges, we propose a novel self-supervised point cloud completion method. We design a set of novel self-supervised signals based on multi-view augmentations of the single partial point cloud. Additionally, to enhance the model's learning ability, we first incorporate Mamba into self-supervised point cloud completion task, encouraging the model to generate point clouds with better quality. Experiments on synthetic and real-world datasets demonstrate that our method achieves state-of-the-art results.
Vision-based 3D Semantic Scene Completion via Capture Dynamic Representations
Mar 08, 2025The vision-based semantic scene completion task aims to predict dense geometric and semantic 3D scene representations from 2D images. However, the presence of dynamic objects in the scene seriously affects the accuracy of the model inferring 3D structures from 2D images. Existing methods simply stack multiple frames of image input to increase dense scene semantic information, but ignore the fact that dynamic objects and non-texture areas violate multi-view consistency and matching reliability. To address these issues, we propose a novel method, CDScene: Vision-based Robust Semantic Scene Completion via Capturing Dynamic Representations. First, we leverage a multimodal large-scale model to extract 2D explicit semantics and align them into 3D space. Second, we exploit the characteristics of monocular and stereo depth to decouple scene information into dynamic and static features. The dynamic features contain structural relationships around dynamic objects, and the static features contain dense contextual spatial information. Finally, we design a dynamic-static adaptive fusion module to effectively extract and aggregate complementary features, achieving robust and accurate semantic scene completion in autonomous driving scenarios. Extensive experimental results on the SemanticKITTI, SSCBench-KITTI360, and SemanticKITTI-C datasets demonstrate the superiority and robustness of CDScene over existing state-of-the-art methods.
VLScene: Vision-Language Guidance Distillation for Camera-Based 3D Semantic Scene Completion
Mar 08, 2025Camera-based 3D semantic scene completion (SSC) provides dense geometric and semantic perception for autonomous driving. However, images provide limited information making the model susceptible to geometric ambiguity caused by occlusion and perspective distortion. Existing methods often lack explicit semantic modeling between objects, limiting their perception of 3D semantic context. To address these challenges, we propose a novel method VLScene: Vision-Language Guidance Distillation for Camera-based 3D Semantic Scene Completion. The key insight is to use the vision-language model to introduce high-level semantic priors to provide the object spatial context required for 3D scene understanding. Specifically, we design a vision-language guidance distillation process to enhance image features, which can effectively capture semantic knowledge from the surrounding environment and improve spatial context reasoning. In addition, we introduce a geometric-semantic sparse awareness mechanism to propagate geometric structures in the neighborhood and enhance semantic information through contextual sparse interactions. Experimental results demonstrate that VLScene achieves rank-1st performance on challenging benchmarks--SemanticKITTI and SSCBench-KITTI-360, yielding remarkably mIoU scores of 17.52 and 19.10, respectively.
Learning Temporal 3D Semantic Scene Completion via Optical Flow Guidance
Feb 20, 2025


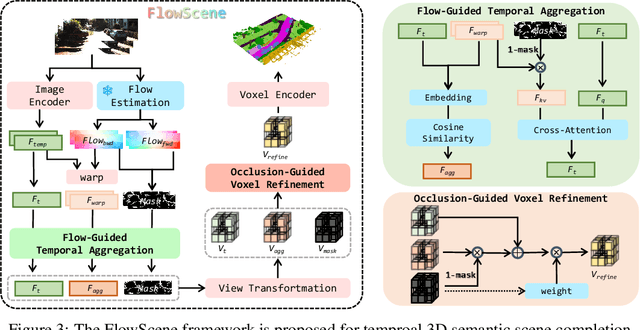
3D Semantic Scene Completion (SSC) provides comprehensive scene geometry and semantics for autonomous driving perception, which is crucial for enabling accurate and reliable decision-making. However, existing SSC methods are limited to capturing sparse information from the current frame or naively stacking multi-frame temporal features, thereby failing to acquire effective scene context. These approaches ignore critical motion dynamics and struggle to achieve temporal consistency. To address the above challenges, we propose a novel temporal SSC method FlowScene: Learning Temporal 3D Semantic Scene Completion via Optical Flow Guidance. By leveraging optical flow, FlowScene can integrate motion, different viewpoints, occlusions, and other contextual cues, thereby significantly improving the accuracy of 3D scene completion. Specifically, our framework introduces two key components: (1) a Flow-Guided Temporal Aggregation module that aligns and aggregates temporal features using optical flow, capturing motion-aware context and deformable structures; and (2) an Occlusion-Guided Voxel Refinement module that injects occlusion masks and temporally aggregated features into 3D voxel space, adaptively refining voxel representations for explicit geometric modeling. Experimental results demonstrate that FlowScene achieves state-of-the-art performance on the SemanticKITTI and SSCBench-KITTI-360 benchmarks.
Retrieval Replace Reduction: An effective visual token reduction method via semantic match
Oct 09, 2024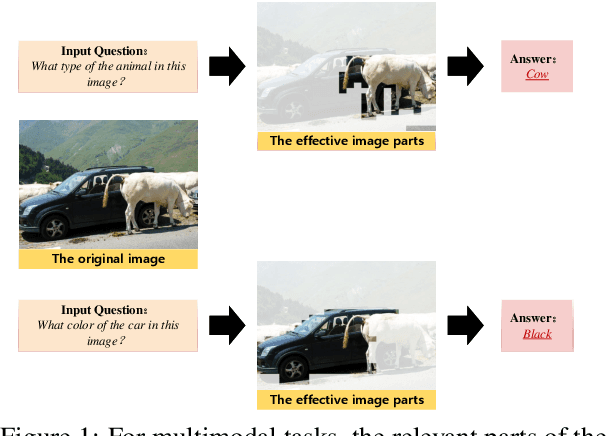

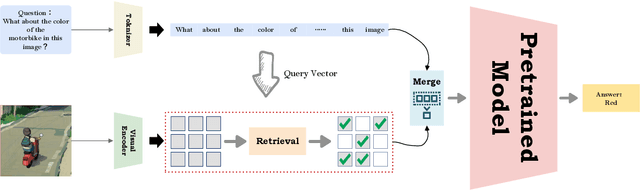

Multimodal large language models (MLLMs) have demonstrated strong performance across various tasks without requiring training from scratch. However, they face significant computational and memory constraints, particularly when processing multimodal inputs that exceed context length, limiting their scalability. In this paper, we introduce a new approach, \textbf{TRSM} (\textbf{T}oken \textbf{R}eduction via \textbf{S}emantic \textbf{M}atch), which effectively reduces the number of visual tokens without compromising MLLM performance. Inspired by how humans process multimodal tasks, TRSM leverages semantic information from one modality to match relevant semantics in another, reducing the number of visual tokens.Specifically, to retain task relevant visual tokens, we use the text prompt as a query vector to retrieve the most similar vectors from the visual prompt and merge them with the text tokens. Based on experimental results, when applied to LLaVA-1.5\cite{liu2023}, our approach compresses the visual tokens by 20\%, achieving comparable performance across diverse visual question-answering and reasoning tasks.
Artistic Portrait Drawing with Vector Strokes
Oct 05, 2024



In this paper, we present a method, VectorPD, for converting a given human face image into a vector portrait sketch. VectorPD supports different levels of abstraction by simply controlling the number of strokes. Since vector graphics are composed of different shape primitives, it is challenging for rendering complex faces to accurately express facial details and structure. To address this, VectorPD employs a novel two-round optimization mechanism. We first initialize the strokes with facial keypoints, and generate a basic portrait sketch by a CLIP-based Semantic Loss. Then we complete the face structure through VGG-based Structure Loss, and propose a novel Crop-based Shadow Loss to enrich the shadow details of the sketch, achieving a visually pleasing portrait sketch. Quantitative and qualitative evaluations both demonstrate that the portrait sketches generated by VectorPD can produce better visual effects than existing state-of-the-art methods, maintaining as much fidelity as possible at different levels of abstraction.
Multi-Round Region-Based Optimization for Scene Sketching
Oct 05, 2024Scene sketching is to convert a scene into a simplified, abstract representation that captures the essential elements and composition of the original scene. It requires semantic understanding of the scene and consideration of different regions within the scene. Since scenes often contain diverse visual information across various regions, such as foreground objects, background elements, and spatial divisions, dealing with these different regions poses unique difficulties. In this paper, we define a sketch as some sets of Bezier curves. We optimize the different regions of input scene in multiple rounds. In each round of optimization, strokes sampled from the next region can seamlessly be integrated into the sketch generated in the previous round of optimization. We propose additional stroke initialization method to ensure the integrity of the scene and the convergence of optimization. A novel CLIP-Based Semantic loss and a VGG-Based Feature loss are utilized to guide our multi-round optimization. Extensive experimental results on the quality and quantity of the generated sketches confirm the effectiveness of our method.