 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Point Cloud Completion based on Multi-View Augmentations of Single Partial Point Cloud
Sep 26, 2025Point cloud completion aims to reconstruct complete shapes from partial observations. Although current methods have achieved remarkable performance, they still have some limitations: Supervised methods heavily rely on ground truth, which limits their generalization to real-world datasets due to the synthetic-to-real domain gap. Unsupervised methods require complete point clouds to compose unpaired training data, and weakly-supervised methods need multi-view observations of the object. Existing self-supervised methods frequently produce unsatisfactory predictions due to the limited capabilities of their self-supervised signals. To overcome these challenges, we propose a novel self-supervised point cloud completion method. We design a set of novel self-supervised signals based on multi-view augmentations of the single partial point cloud. Additionally, to enhance the model's learning ability, we first incorporate Mamba into self-supervised point cloud completion task, encouraging the model to generate point clouds with better quality. Experiments on synthetic and real-world datasets demonstrate that our method achieves state-of-the-art results.
Vision-based 3D Semantic Scene Completion via Capture Dynamic Representations
Mar 08, 2025The vision-based semantic scene completion task aims to predict dense geometric and semantic 3D scene representations from 2D images. However, the presence of dynamic objects in the scene seriously affects the accuracy of the model inferring 3D structures from 2D images. Existing methods simply stack multiple frames of image input to increase dense scene semantic information, but ignore the fact that dynamic objects and non-texture areas violate multi-view consistency and matching reliability. To address these issues, we propose a novel method, CDScene: Vision-based Robust Semantic Scene Completion via Capturing Dynamic Representations. First, we leverage a multimodal large-scale model to extract 2D explicit semantics and align them into 3D space. Second, we exploit the characteristics of monocular and stereo depth to decouple scene information into dynamic and static features. The dynamic features contain structural relationships around dynamic objects, and the static features contain dense contextual spatial information. Finally, we design a dynamic-static adaptive fusion module to effectively extract and aggregate complementary features, achieving robust and accurate semantic scene completion in autonomous driving scenarios. Extensive experimental results on the SemanticKITTI, SSCBench-KITTI360, and SemanticKITTI-C datasets demonstrate the superiority and robustness of CDScene over existing state-of-the-art methods.
VLScene: Vision-Language Guidance Distillation for Camera-Based 3D Semantic Scene Completion
Mar 08, 2025Camera-based 3D semantic scene completion (SSC) provides dense geometric and semantic perception for autonomous driving. However, images provide limited information making the model susceptible to geometric ambiguity caused by occlusion and perspective distortion. Existing methods often lack explicit semantic modeling between objects, limiting their perception of 3D semantic context. To address these challenges, we propose a novel method VLScene: Vision-Language Guidance Distillation for Camera-based 3D Semantic Scene Completion. The key insight is to use the vision-language model to introduce high-level semantic priors to provide the object spatial context required for 3D scene understanding. Specifically, we design a vision-language guidance distillation process to enhance image features, which can effectively capture semantic knowledge from the surrounding environment and improve spatial context reasoning. In addition, we introduce a geometric-semantic sparse awareness mechanism to propagate geometric structures in the neighborhood and enhance semantic information through contextual sparse interactions. Experimental results demonstrate that VLScene achieves rank-1st performance on challenging benchmarks--SemanticKITTI and SSCBench-KITTI-360, yielding remarkably mIoU scores of 17.52 and 19.10, respectively.
Learning Temporal 3D Semantic Scene Completion via Optical Flow Guidance
Feb 20, 2025


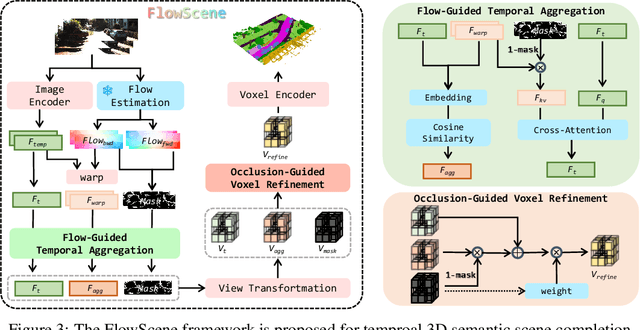
3D Semantic Scene Completion (SSC) provides comprehensive scene geometry and semantics for autonomous driving perception, which is crucial for enabling accurate and reliable decision-making. However, existing SSC methods are limited to capturing sparse information from the current frame or naively stacking multi-frame temporal features, thereby failing to acquire effective scene context. These approaches ignore critical motion dynamics and struggle to achieve temporal consistency. To address the above challenges, we propose a novel temporal SSC method FlowScene: Learning Temporal 3D Semantic Scene Completion via Optical Flow Guidance. By leveraging optical flow, FlowScene can integrate motion, different viewpoints, occlusions, and other contextual cues, thereby significantly improving the accuracy of 3D scene completion. Specifically, our framework introduces two key components: (1) a Flow-Guided Temporal Aggregation module that aligns and aggregates temporal features using optical flow, capturing motion-aware context and deformable structures; and (2) an Occlusion-Guided Voxel Refinement module that injects occlusion masks and temporally aggregated features into 3D voxel space, adaptively refining voxel representations for explicit geometric modeling. Experimental results demonstrate that FlowScene achieves state-of-the-art performance on the SemanticKITTI and SSCBench-KITTI-360 benchmarks.
ATM-R: An Adaptive Tradeoff Model with Reference Points for Constrained Multiobjective Evolutionary Optimization
Jan 09, 2023



The goal of constrained multiobjective evolutionary optimization is to obtain a set of well-converged and welldistributed feasible solutions. To complete this goal, there should be a tradeoff among feasibility, diversity, and convergence. However, it is nontrivial to balance these three elements simultaneously by using a single tradeoff model since the importance of each element varies in different evolutionary phases. As an alternative, we adapt different tradeoff models in different phases and propose a novel algorithm called ATM-R. In the infeasible phase, ATM-R takes the tradeoff between diversity and feasibility into account, aiming to move the population toward feasible regions from diverse search directions. In the semi-feasible phase, ATM-R promotes the transition from "the tradeoff between feasibility and diversity" to "the tradeoff between diversity and convergence", which can facilitate the discovering of enough feasible regions and speed up the search for the feasible Pareto optima in succession. In the feasible phase, the tradeoff between diversity and convergence is considered to attain a set of well-converged and well-distributed feasible solutions. It is worth noting that the merits of reference points are leveraged in ATM-R to accomplish these tradeoff models. Also, in ATM-R, a multiphase mating selection strategy is developed to generate promising solutions beneficial to different evolutionary phases. Systemic experiments on a wide range of benchmark test functions demonstrate that ATM-R is effective and competitive, compared against five state-of-the-art constrained multiobjective optimization evolutionary algorithms.