 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Small-Scale Dataset Expansion with Triplet-Connection-based Sample Re-Weighting
Aug 11, 2025The performance of computer vision models in certain real-world applications, such as medical diagnosis, is often limited by the scarcity of available images. Expanding datasets using pre-trained generative models is an effective solution. However, due to the uncontrollable generation process and the ambiguity of natural language, noisy images may be generated. Re-weighting is an effective way to address this issue by assigning low weights to such noisy images. We first theoretically analyze three types of supervision for the generated images. Based on the theoretical analysis, we develop TriReWeight, a triplet-connection-based sample re-weighting method to enhance generative data augmentation. Theoretically, TriReWeight can be integrated with any generative data augmentation methods and never downgrade their performance. Moreover, its generalization approaches the optimal in the order $O(\sqrt{d\ln (n)/n})$. Our experiments validate the correctness of the theoretical analysis and demonstrate that our method outperforms the existing SOTA methods by $7.9\%$ on average over six natural image datasets and by $3.4\%$ on average over three medical datasets. We also experimentally validate that our method can enhance the performance of different generative data augmentation methods.
FedMPQ: Secure and Communication-Efficient Federated Learning with Multi-codebook Product Quantization
Apr 21, 2024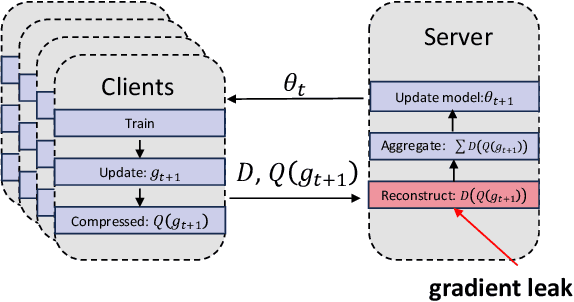

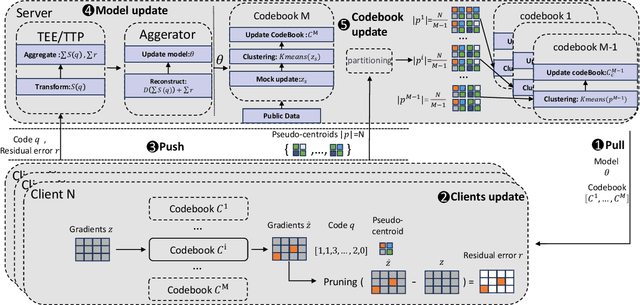
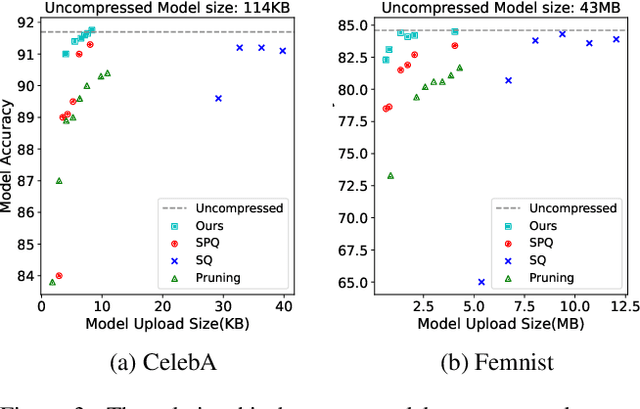
In federated learning, particularly in cross-device scenarios, secure aggregation has recently gained popularity as it effectively defends against inference attacks by malicious aggregators. However, secure aggregation often requires additional communication overhead and can impede the convergence rate of the global model, which is particularly challenging in wireless network environments with extremely limited bandwidth. Therefore, achieving efficient communication compression under the premise of secure aggregation presents a highly challenging and valuable problem. In this work, we propose a novel uplink communication compression method for federated learning, named FedMPQ, which is based on multi shared codebook product quantization.Specifically, we utilize updates from the previous round to generate sufficiently robust codebooks. Secure aggregation is then achieved through trusted execution environments (TEE) or a trusted third party (TTP).In contrast to previous works, our approach exhibits greater robustness in scenarios where data is not independently and identically distributed (non-IID) and there is a lack of sufficient public data. The experiments conducted on the LEAF dataset demonstrate that our proposed method achieves 99% of the baseline's final accuracy, while reducing uplink communications by 90-95%
Imitation and Adaptation Based on Consistency: A Quadruped Robot Imitates Animals from Videos Using Deep Reinforcement Learning
Mar 02, 2022

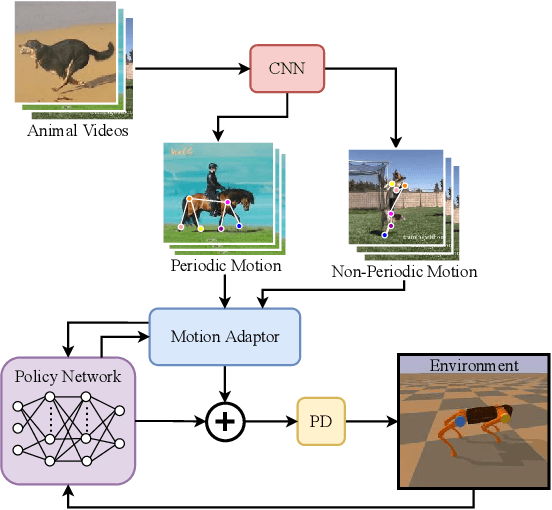

The essence of quadrupeds' movements is the movement of the center of gravity, which has a pattern in the action of quadrupeds. However, the gait motion planning of the quadruped robot is time-consuming. Animals in nature can provide a large amount of gait information for robots to learn and imitate. Common methods learn animal posture with a motion capture system or numerous motion data points. In this paper, we propose a video imitation adaptation network (VIAN) that can imitate the action of animals and adapt it to the robot from a few seconds of video. The deep learning model extracts key points during animal motion from videos. The VIAN eliminates noise and extracts key information of motion with a motion adaptor, and then applies the extracted movements function as the motion pattern into deep reinforcement learning (DRL). To ensure similarity between the learning result and the animal motion in the video, we introduce rewards that are based on the consistency of the motion. DRL explores and learns to maintain balance from movement patterns from videos, imitates the action of animals, and eventually, allows the model to learn the gait or skills from short motion videos of different animals and to transfer the motion pattern to the real robot.
A Transferable Legged Mobile Manipulation Framework Based on Disturbance Predictive Control
Mar 02, 2022
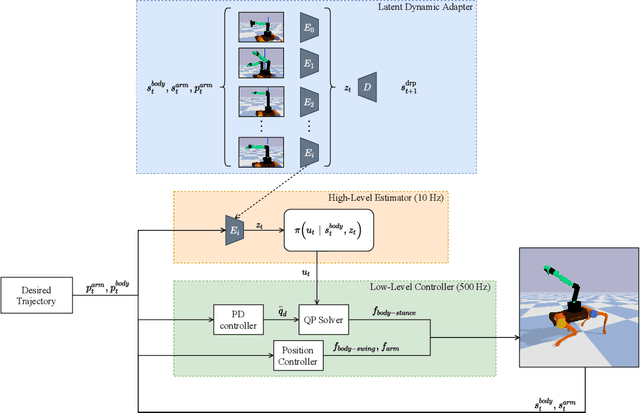

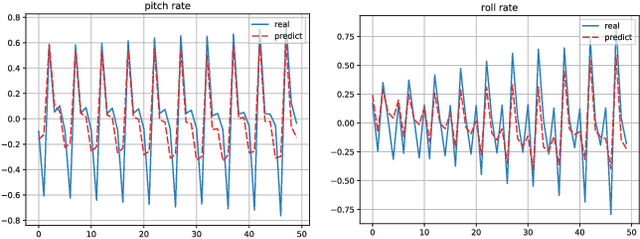
Due to their ability to adapt to different terrains, quadruped robots have drawn much attention in the research field of robot learning. Legged mobile manipulation, where a quadruped robot is equipped with a robotic arm, can greatly enhance the performance of the robot in diverse manipulation tasks. Several prior works have investigated legged mobile manipulation from the viewpoint of control theory. However, modeling a unified structure for various robotic arms and quadruped robots is a challenging task. In this paper, we propose a unified framework disturbance predictive control where a reinforcement learning scheme with a latent dynamic adapter is embedded into our proposed low-level controller. Our method can adapt well to various types of robotic arms with a few random motion samples and the experimental results demonstrate the effectiveness of our method.
Multi-Task Reinforcement Learning based Mobile Manipulation Control for Dynamic Object Tracking and Grasping
Jun 07, 2020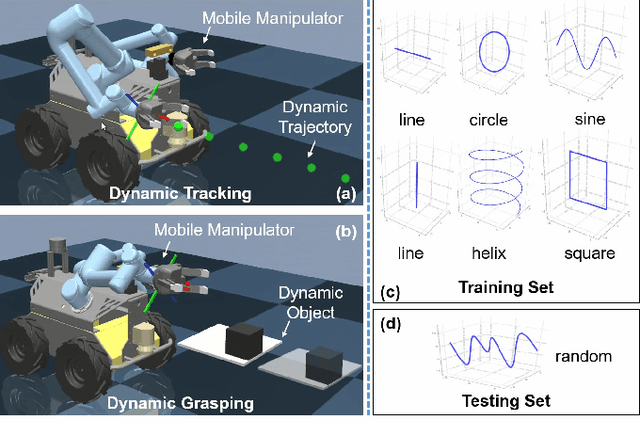
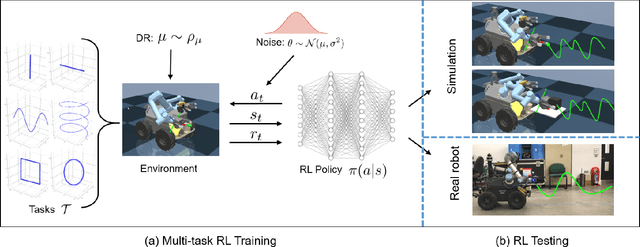
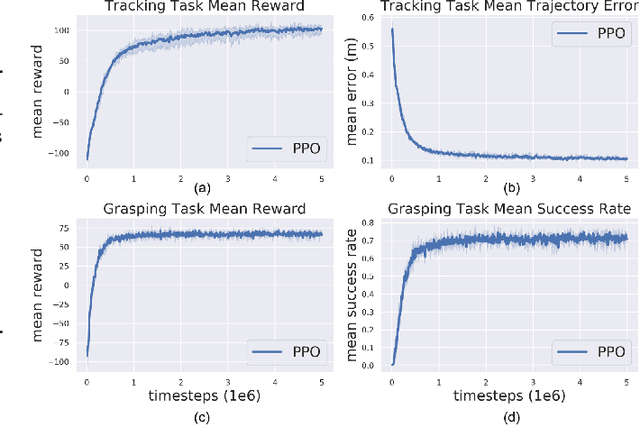

Agile control of mobile manipulator is challenging because of the high complexity coupled by the robotic system and the unstructured working environment. Tracking and grasping a dynamic object with a random trajectory is even harder. In this paper, a multi-task reinforcement learning-based mobile manipulation control framework is proposed to achieve general dynamic object tracking and grasping. Several basic types of dynamic trajectories are chosen as the task training set. To improve the policy generalization in practice, random noise and dynamics randomization are introduced during the training process. Extensive experiments show that our policy trained can adapt to unseen random dynamic trajectories with about 0.1m tracking error and 75\% grasping success rate of dynamic objects. The trained policy can also be successfully deployed on a real mobile manipulator.