 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLIPS: Instance-Fingerprinting for LLMs via Pseudo-random Sequences
Jun 02, 2026Literature reveals that a Large Language Model's (LLM) behavior is not only conditioned by its original weights but also its instance-level parameters, such as instructional prompt, sampling configuration or quantization. A model that generates safe outputs under one configuration may produce toxic content under another. However, current LLM identification techniques (such as fingerprinting) focus on intellectual property protection, and their design favors robustness to changes in these instance-level parameters. This poses a critical challenge for AI regulation in which compliance assessments target actual deployed behaviors, not model provenance. In this paper, we introduce instance-level fingerprinting, a regulator-oriented paradigm that distinguishes configurations of the same LLM. Our method FLIPS, exploits biases in generated binary random sequences to reach 96% (closed-set) and 90% (open-set, where some targets are unknown) identification accuracy across 237 model instances, versus 35% for the adapted LLMmap baseline. This shows that instance-level fingerprinting is both necessary for regulation and practically feasible. Code available at https://github.com/GurvanR/FLIPS-LLM-Instance-Fingerprinting.
Token-Efficient Change Detection in LLM APIs
Feb 11, 2026Remote change detection in LLMs is a difficult problem. Existing methods are either too expensive for deployment at scale, or require initial white-box access to model weights or grey-box access to log probabilities. We aim to achieve both low cost and strict black-box operation, observing only output tokens. Our approach hinges on specific inputs we call Border Inputs, for which there exists more than one output top token. From a statistical perspective, optimal change detection depends on the model's Jacobian and the Fisher information of the output distribution. Analyzing these quantities in low-temperature regimes shows that border inputs enable powerful change detection tests. Building on this insight, we propose the Black-Box Border Input Tracking (B3IT) scheme. Extensive in-vivo and in-vitro experiments show that border inputs are easily found for non-reasoning tested endpoints, and achieve performance on par with the best available grey-box approaches. B3IT reduces costs by $30\times$ compared to existing methods, while operating in a strict black-box setting.
Robust ML Auditing using Prior Knowledge
May 07, 2025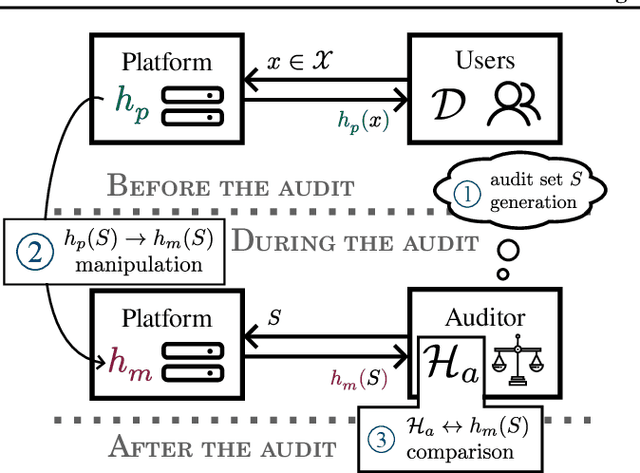

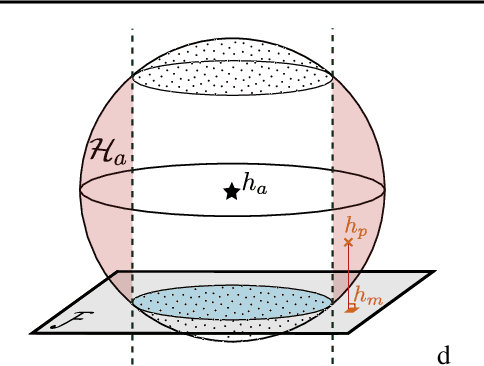
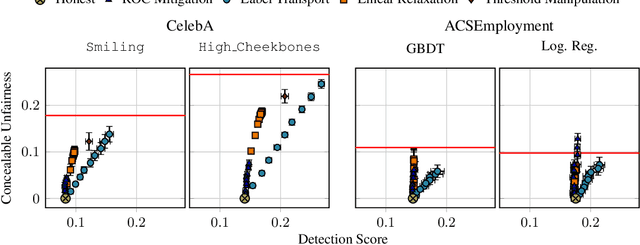
The rapid adoption of ML decision-making systems across products and services has led to a set of regulations on how such systems should behave and be built. Among all the technical challenges to enforcing these regulations, one crucial, yet under-explored problem is the risk of manipulation while these systems are being audited for fairness. This manipulation occurs when a platform deliberately alters its answers to a regulator to pass an audit without modifying its answers to other users. In this paper, we introduce a novel approach to manipulation-proof auditing by taking into account the auditor's prior knowledge of the task solved by the platform. We first demonstrate that regulators must not rely on public priors (e.g. a public dataset), as platforms could easily fool the auditor in such cases. We then formally establish the conditions under which an auditor can prevent audit manipulations using prior knowledge about the ground truth. Finally, our experiments with two standard datasets exemplify the maximum level of unfairness a platform can hide before being detected as malicious. Our formalization and generalization of manipulation-proof auditing with a prior opens up new research directions for more robust fairness audits.
P2NIA: Privacy-Preserving Non-Iterative Auditing
Apr 01, 2025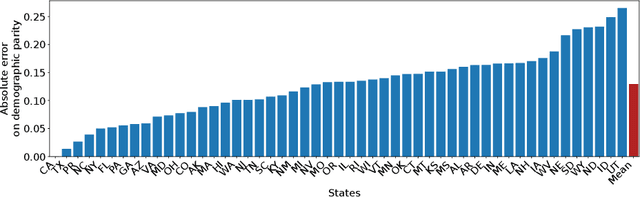
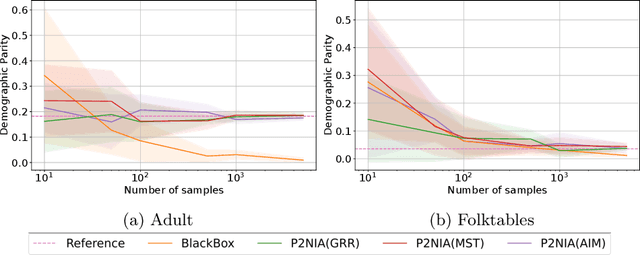
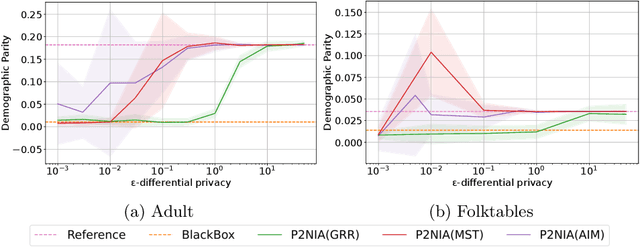
The emergence of AI legislation has increased the need to assess the ethical compliance of high-risk AI systems. Traditional auditing methods rely on platforms' application programming interfaces (APIs), where responses to queries are examined through the lens of fairness requirements. However, such approaches put a significant burden on platforms, as they are forced to maintain APIs while ensuring privacy, facing the possibility of data leaks. This lack of proper collaboration between the two parties, in turn, causes a significant challenge to the auditor, who is subject to estimation bias as they are unaware of the data distribution of the platform. To address these two issues, we present P2NIA, a novel auditing scheme that proposes a mutually beneficial collaboration for both the auditor and the platform. Extensive experiments demonstrate P2NIA's effectiveness in addressing both issues. In summary, our work introduces a privacy-preserving and non-iterative audit scheme that enhances fairness assessments using synthetic or local data, avoiding the challenges associated with traditional API-based audits.
The 20 questions game to distinguish large language models
Sep 16, 2024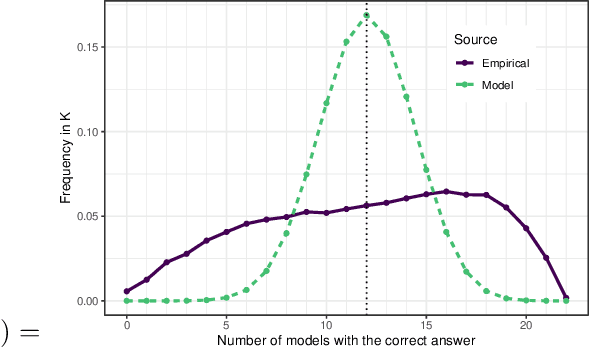
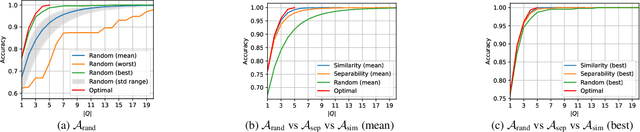
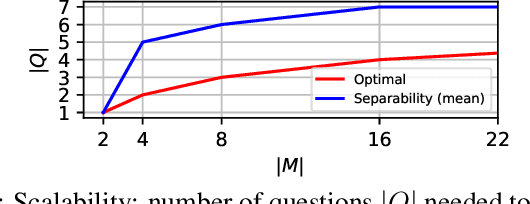
In a parallel with the 20 questions game, we present a method to determine whether two large language models (LLMs), placed in a black-box context, are the same or not. The goal is to use a small set of (benign) binary questions, typically under 20. We formalize the problem and first establish a baseline using a random selection of questions from known benchmark datasets, achieving an accuracy of nearly 100% within 20 questions. After showing optimal bounds for this problem, we introduce two effective questioning heuristics able to discriminate 22 LLMs by using half as many questions for the same task. These methods offer significant advantages in terms of stealth and are thus of interest to auditors or copyright owners facing suspicions of model leaks.
LLMs hallucinate graphs too: a structural perspective
Aug 30, 2024
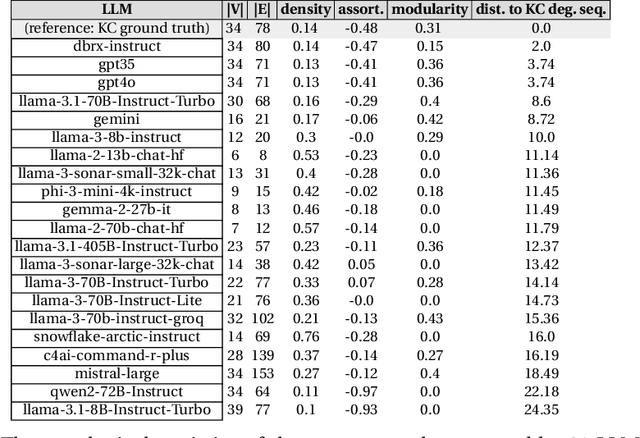

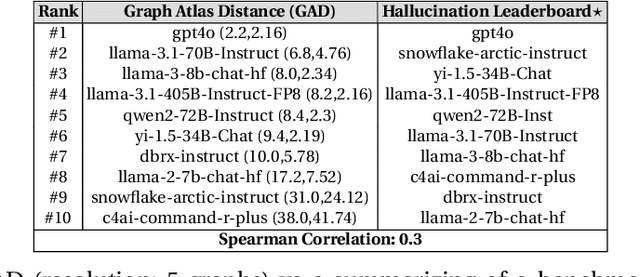
It is known that LLMs do hallucinate, that is, they return incorrect information as facts. In this paper, we introduce the possibility to study these hallucinations under a structured form: graphs. Hallucinations in this context are incorrect outputs when prompted for well known graphs from the literature (e.g. Karate club, Les Mis\'erables, graph atlas). These hallucinated graphs have the advantage of being much richer than the factual accuracy -- or not -- of a fact; this paper thus argues that such rich hallucinations can be used to characterize the outputs of LLMs. Our first contribution observes the diversity of topological hallucinations from major modern LLMs. Our second contribution is the proposal of a metric for the amplitude of such hallucinations: the Graph Atlas Distance, that is the average graph edit distance from several graphs in the graph atlas set. We compare this metric to the Hallucination Leaderboard, a hallucination rank that leverages 10,000 times more prompts to obtain its ranking.
Under manipulations, are some AI models harder to audit?
Feb 14, 2024Auditors need robust methods to assess the compliance of web platforms with the law. However, since they hardly ever have access to the algorithm, implementation, or training data used by a platform, the problem is harder than a simple metric estimation. Within the recent framework of manipulation-proof auditing, we study in this paper the feasibility of robust audits in realistic settings, in which models exhibit large capacities. We first prove a constraining result: if a web platform uses models that may fit any data, no audit strategy -- whether active or not -- can outperform random sampling when estimating properties such as demographic parity. To better understand the conditions under which state-of-the-art auditing techniques may remain competitive, we then relate the manipulability of audits to the capacity of the targeted models, using the Rademacher complexity. We empirically validate these results on popular models of increasing capacities, thus confirming experimentally that large-capacity models, which are commonly used in practice, are particularly hard to audit robustly. These results refine the limits of the auditing problem, and open up enticing questions on the connection between model capacity and the ability of platforms to manipulate audit attempts.
Fairness Auditing with Multi-Agent Collaboration
Feb 13, 2024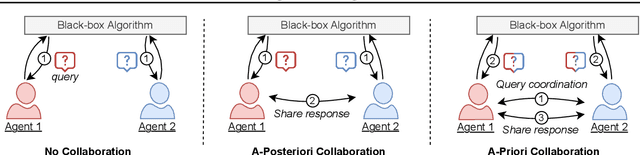
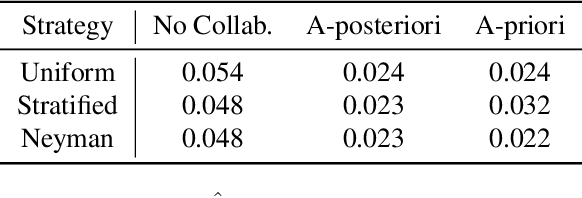
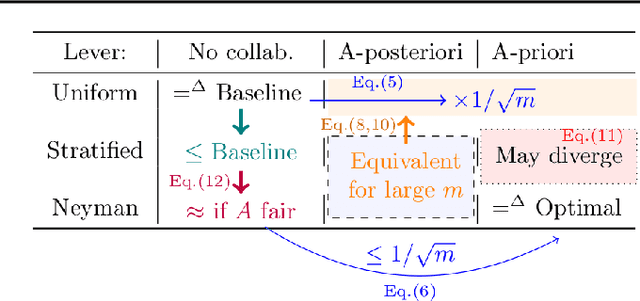
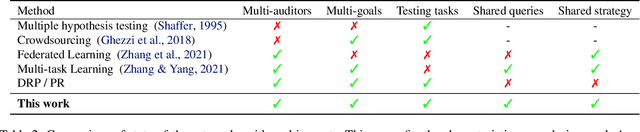
Existing work in fairness audits assumes that agents operate independently. In this paper, we consider the case of multiple agents auditing the same platform for different tasks. Agents have two levers: their collaboration strategy, with or without coordination beforehand, and their sampling method. We theoretically study their interplay when agents operate independently or collaborate. We prove that, surprisingly, coordination can sometimes be detrimental to audit accuracy, whereas uncoordinated collaboration generally yields good results. Experimentation on real-world datasets confirms this observation, as the audit accuracy of uncoordinated collaboration matches that of collaborative optimal sampling.
On the relevance of APIs facing fairwashed audits
May 23, 2023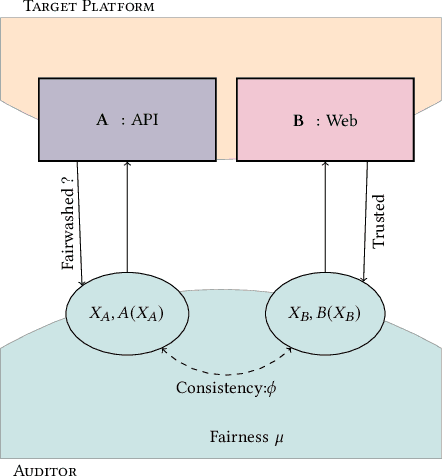
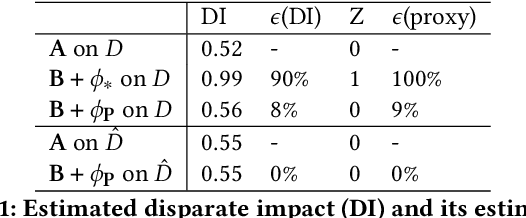
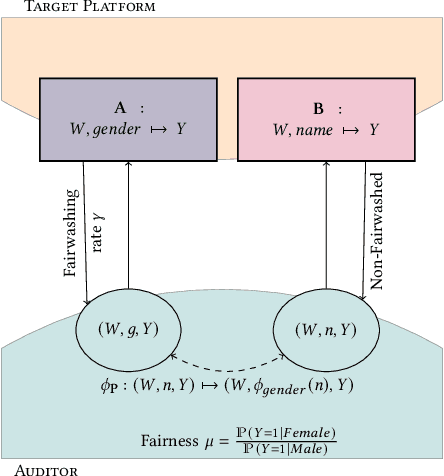
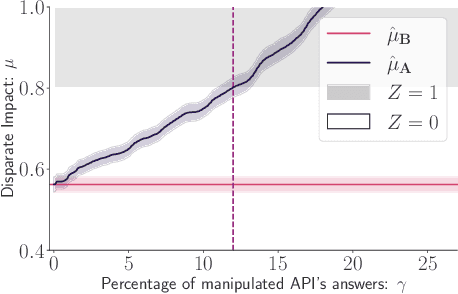
Recent legislation required AI platforms to provide APIs for regulators to assess their compliance with the law. Research has nevertheless shown that platforms can manipulate their API answers through fairwashing. Facing this threat for reliable auditing, this paper studies the benefits of the joint use of platform scraping and of APIs. In this setup, we elaborate on the use of scraping to detect manipulated answers: since fairwashing only manipulates API answers, exploiting scraps may reveal a manipulation. To abstract the wide range of specific API-scrap situations, we introduce a notion of proxy that captures the consistency an auditor might expect between both data sources. If the regulator has a good proxy of the consistency, then she can easily detect manipulation and even bypass the API to conduct her audit. On the other hand, without a good proxy, relying on the API is necessary, and the auditor cannot defend against fairwashing. We then simulate practical scenarios in which the auditor may mostly rely on the API to conveniently conduct the audit task, while maintaining her chances to detect a potential manipulation. To highlight the tension between the audit task and the API fairwashing detection task, we identify Pareto-optimal strategies in a practical audit scenario. We believe this research sets the stage for reliable audits in practical and manipulation-prone setups.
The Bouncer Problem: Challenges to Remote Explainability
Oct 03, 2019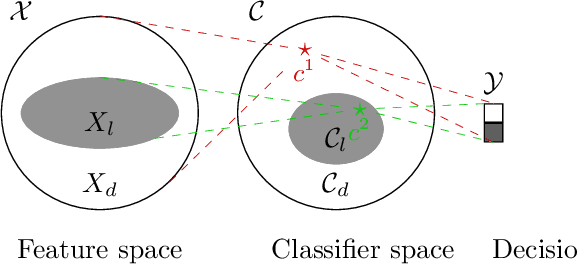
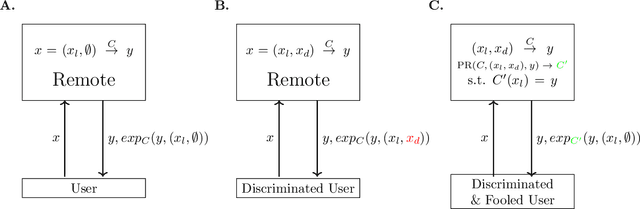
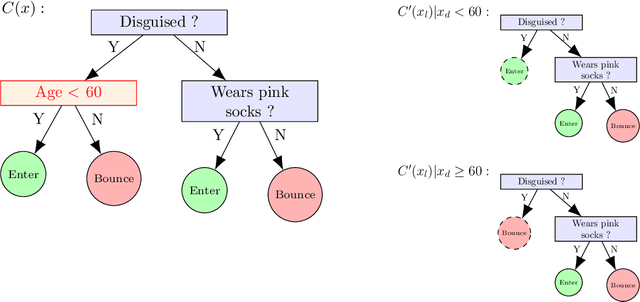
The concept of explainability is envisioned to satisfy society's demands for transparency on machine learning decisions. The concept is simple: like humans, algorithms should explain the rationale behind their decisions so that their fairness can be assessed. While this approach is promising in a local context (e.g. to explain a model during debugging at training time), we argue that this reasoning cannot simply be transposed in a remote context, where a trained model by a service provider is only accessible through its API. This is problematic as it constitutes precisely the target use-case requiring transparency from a societal perspective. Through an analogy with a club bouncer (which may provide untruthful explanations upon customer reject), we show that providing explanations cannot prevent a remote service from lying about the true reasons leading to its decisions. More precisely, we prove the impossibility of remote explainability for single explanations, by constructing an attack on explanations that hides discriminatory features to the querying user. We provide an example implementation of this attack. We then show that the probability that an observer spots the attack, using several explanations for attempting to find incoherences, is low in practical settings. This undermines the very concept of remote explainability in general.