 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust ML Auditing using Prior Knowledge
May 07, 2025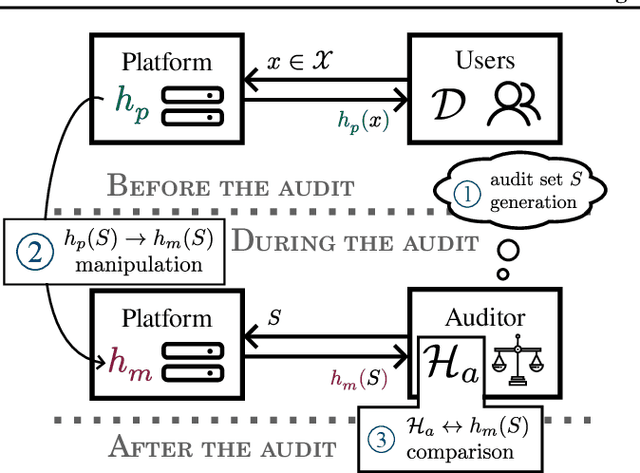

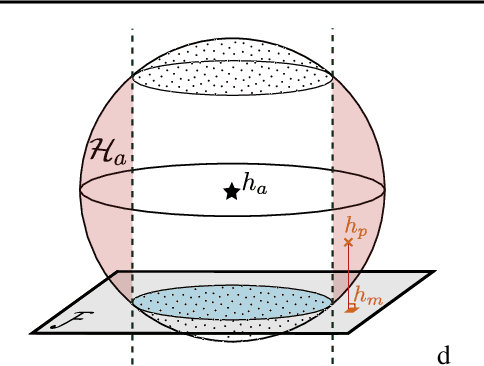
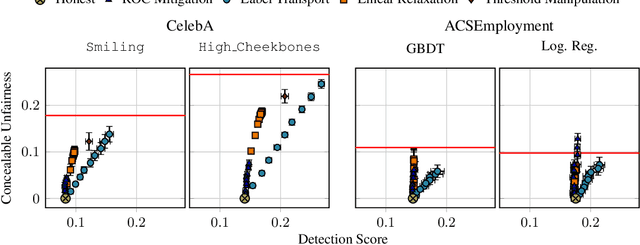
The rapid adoption of ML decision-making systems across products and services has led to a set of regulations on how such systems should behave and be built. Among all the technical challenges to enforcing these regulations, one crucial, yet under-explored problem is the risk of manipulation while these systems are being audited for fairness. This manipulation occurs when a platform deliberately alters its answers to a regulator to pass an audit without modifying its answers to other users. In this paper, we introduce a novel approach to manipulation-proof auditing by taking into account the auditor's prior knowledge of the task solved by the platform. We first demonstrate that regulators must not rely on public priors (e.g. a public dataset), as platforms could easily fool the auditor in such cases. We then formally establish the conditions under which an auditor can prevent audit manipulations using prior knowledge about the ground truth. Finally, our experiments with two standard datasets exemplify the maximum level of unfairness a platform can hide before being detected as malicious. Our formalization and generalization of manipulation-proof auditing with a prior opens up new research directions for more robust fairness audits.
Boosting Asynchronous Decentralized Learning with Model Fragmentation
Oct 16, 2024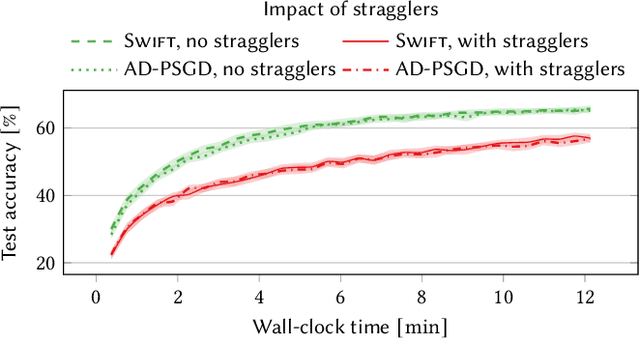

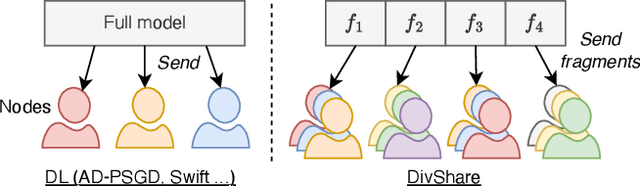
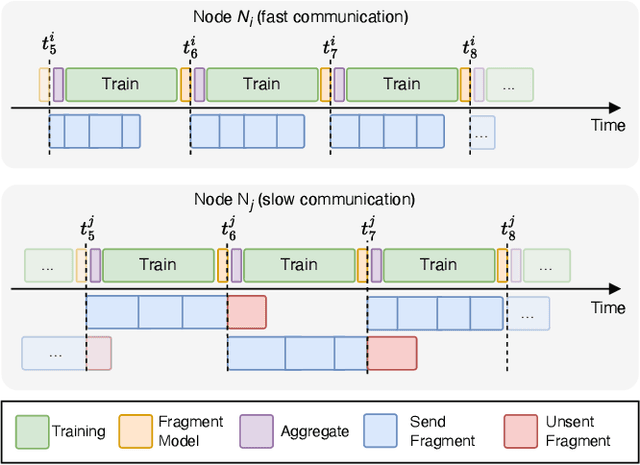
Decentralized learning (DL) is an emerging technique that allows nodes on the web to collaboratively train machine learning models without sharing raw data. Dealing with stragglers, i.e., nodes with slower compute or communication than others, is a key challenge in DL. We present DivShare, a novel asynchronous DL algorithm that achieves fast model convergence in the presence of communication stragglers. DivShare achieves this by having nodes fragment their models into parameter subsets and send, in parallel to computation, each subset to a random sample of other nodes instead of sequentially exchanging full models. The transfer of smaller fragments allows more efficient usage of the collective bandwidth and enables nodes with slow network links to quickly contribute with at least some of their model parameters. By theoretically proving the convergence of DivShare, we provide, to the best of our knowledge, the first formal proof of convergence for a DL algorithm that accounts for the effects of asynchronous communication with delays. We experimentally evaluate DivShare against two state-of-the-art DL baselines, AD-PSGD and Swift, and with two standard datasets, CIFAR-10 and MovieLens. We find that DivShare with communication stragglers lowers time-to-accuracy by up to 3.9x compared to AD-PSGD on the CIFAR-10 dataset. Compared to baselines, DivShare also achieves up to 19.4% better accuracy and 9.5% lower test loss on the CIFAR-10 and MovieLens datasets, respectively.
QuickDrop: Efficient Federated Unlearning by Integrated Dataset Distillation
Nov 27, 2023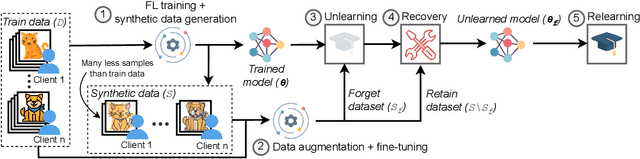
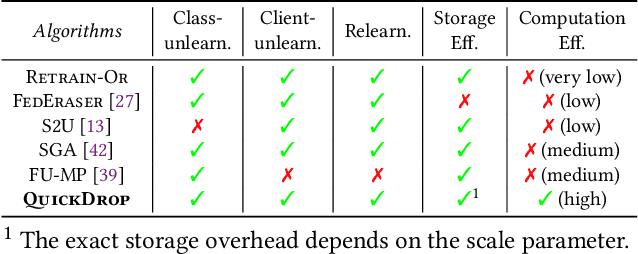
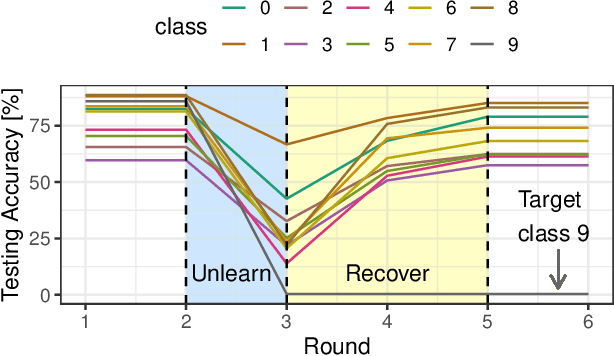
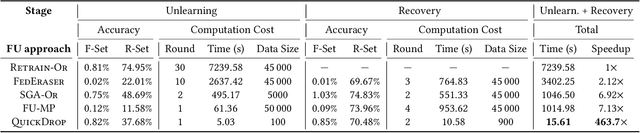
Federated Unlearning (FU) aims to delete specific training data from an ML model trained using Federated Learning (FL). We introduce QuickDrop, an efficient and original FU method that utilizes dataset distillation (DD) to accelerate unlearning and drastically reduces computational overhead compared to existing approaches. In QuickDrop, each client uses DD to generate a compact dataset representative of the original training dataset, called a distilled dataset, and uses this compact dataset during unlearning. To unlearn specific knowledge from the global model, QuickDrop has clients execute Stochastic Gradient Ascent with samples from the distilled datasets, thus significantly reducing computational overhead compared to conventional FU methods. We further increase the efficiency of QuickDrop by ingeniously integrating DD into the FL training process. By reusing the gradient updates produced during FL training for DD, the overhead of creating distilled datasets becomes close to negligible. Evaluations on three standard datasets show that, with comparable accuracy guarantees, QuickDrop reduces the duration of unlearning by 463.8x compared to model retraining from scratch and 65.1x compared to existing FU approaches. We also demonstrate the scalability of QuickDrop with 100 clients and show its effectiveness while handling multiple unlearning operations.