 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuickDrop: Efficient Federated Unlearning by Integrated Dataset Distillation
Paper and Code
Nov 27, 2023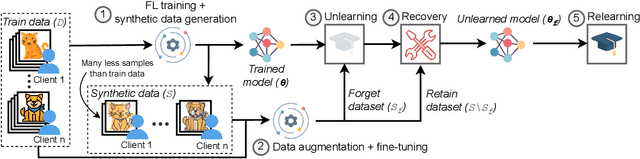
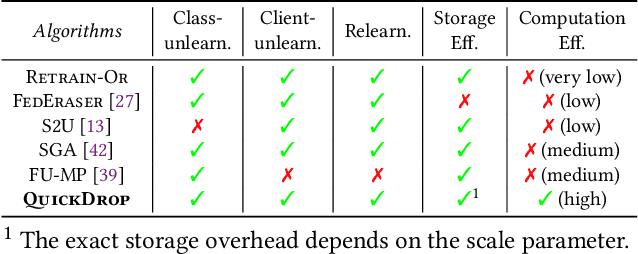
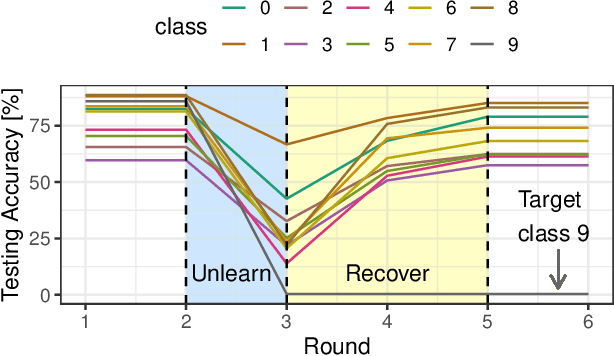
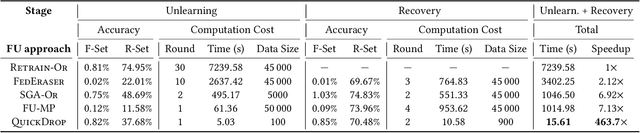
Federated Unlearning (FU) aims to delete specific training data from an ML model trained using Federated Learning (FL). We introduce QuickDrop, an efficient and original FU method that utilizes dataset distillation (DD) to accelerate unlearning and drastically reduces computational overhead compared to existing approaches. In QuickDrop, each client uses DD to generate a compact dataset representative of the original training dataset, called a distilled dataset, and uses this compact dataset during unlearning. To unlearn specific knowledge from the global model, QuickDrop has clients execute Stochastic Gradient Ascent with samples from the distilled datasets, thus significantly reducing computational overhead compared to conventional FU methods. We further increase the efficiency of QuickDrop by ingeniously integrating DD into the FL training process. By reusing the gradient updates produced during FL training for DD, the overhead of creating distilled datasets becomes close to negligible. Evaluations on three standard datasets show that, with comparable accuracy guarantees, QuickDrop reduces the duration of unlearning by 463.8x compared to model retraining from scratch and 65.1x compared to existing FU approaches. We also demonstrate the scalability of QuickDrop with 100 clients and show its effectiveness while handling multiple unlearning operations.