 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Bouncer Problem: Challenges to Remote Explainability
Paper and Code
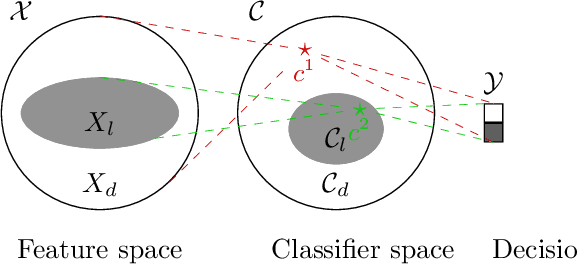
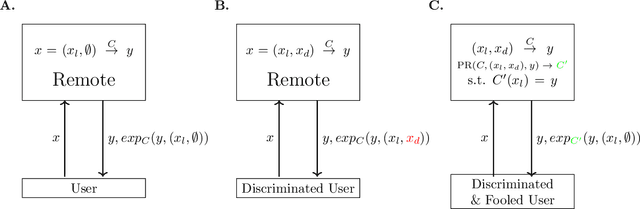
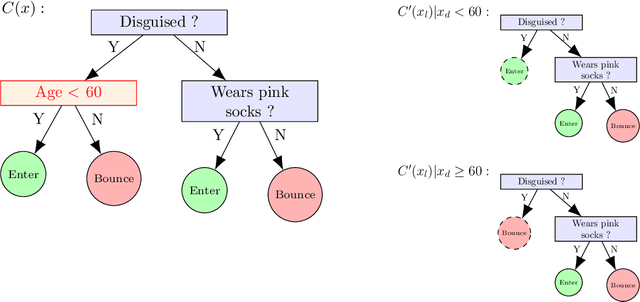
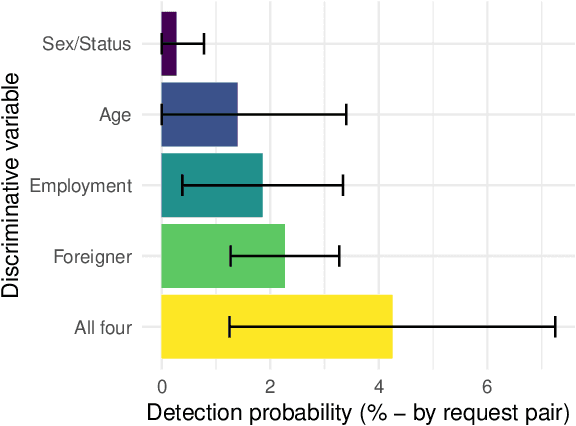
The concept of explainability is envisioned to satisfy society's demands for transparency on machine learning decisions. The concept is simple: like humans, algorithms should explain the rationale behind their decisions so that their fairness can be assessed. While this approach is promising in a local context (e.g. to explain a model during debugging at training time), we argue that this reasoning cannot simply be transposed in a remote context, where a trained model by a service provider is only accessible through its API. This is problematic as it constitutes precisely the target use-case requiring transparency from a societal perspective. Through an analogy with a club bouncer (which may provide untruthful explanations upon customer reject), we show that providing explanations cannot prevent a remote service from lying about the true reasons leading to its decisions. More precisely, we prove the impossibility of remote explainability for single explanations, by constructing an attack on explanations that hides discriminatory features to the querying user. We provide an example implementation of this attack. We then show that the probability that an observer spots the attack, using several explanations for attempting to find incoherences, is low in practical settings. This undermines the very concept of remote explainability in general.