 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisleading the Covid-19 vaccination discourse on Twitter: An exploratory study of infodemic around the pandemic
Paper and Code
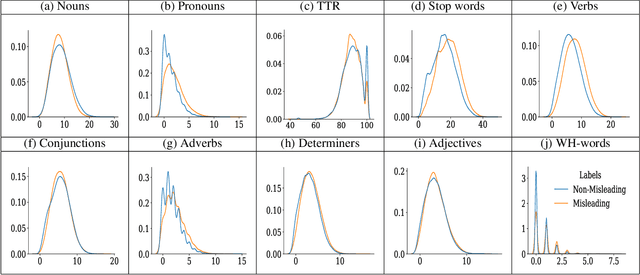
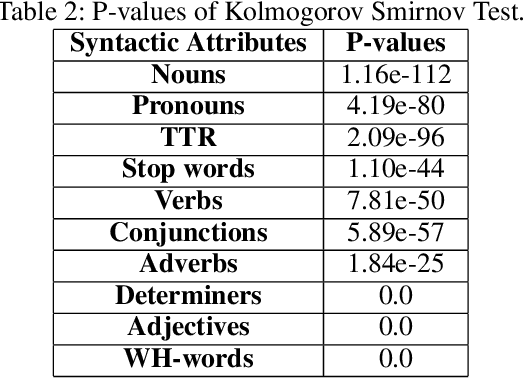
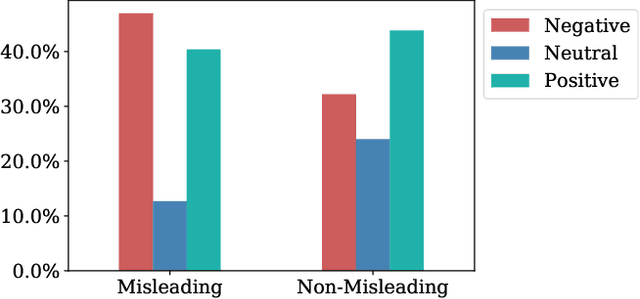
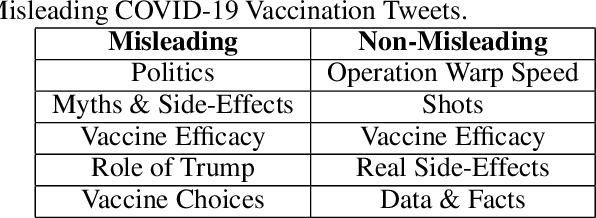
In this work, we collect a moderate-sized representative corpus of tweets (200,000 approx.) pertaining Covid-19 vaccination spanning over a period of seven months (September 2020 - March 2021). Following a Transfer Learning approach, we utilize the pre-trained Transformer-based XLNet model to classify tweets as Misleading or Non-Misleading and validate against a random subset of results manually. We build on this to study and contrast the characteristics of tweets in the corpus that are misleading in nature against non-misleading ones. This exploratory analysis enables us to design features (such as sentiments, hashtags, nouns, pronouns, etc) that can, in turn, be exploited for classifying tweets as (Non-)Misleading using various ML models in an explainable manner. Specifically, several ML models are employed for prediction, with up to 90% accuracy, and the importance of each feature is explained using SHAP Explainable AI (XAI) tool. While the thrust of this work is principally exploratory analysis in order to obtain insights on the online discourse on Covid-19 vaccination, we conclude the paper by outlining how these insights provide the foundations for a more actionable approach to mitigate misinformation. The curated dataset and code is made available (Github repository) so that the research community at large can reproduce, compare against, or build upon this work.