 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning-based Knowledge Graph Reasoning for Explainable Fact-checking
Oct 11, 2023



Fact-checking is a crucial task as it ensures the prevention of misinformation. However, manual fact-checking cannot keep up with the rate at which false information is generated and disseminated online. Automated fact-checking by machines is significantly quicker than by humans. But for better trust and transparency of these automated systems, explainability in the fact-checking process is necessary. Fact-checking often entails contrasting a factual assertion with a body of knowledge for such explanations. An effective way of representing knowledge is the Knowledge Graph (KG). There have been sufficient works proposed related to fact-checking with the usage of KG but not much focus is given to the application of reinforcement learning (RL) in such cases. To mitigate this gap, we propose an RL-based KG reasoning approach for explainable fact-checking. Extensive experiments on FB15K-277 and NELL-995 datasets reveal that reasoning over a KG is an effective way of producing human-readable explanations in the form of paths and classifications for fact claims. The RL reasoning agent computes a path that either proves or disproves a factual claim, but does not provide a verdict itself. A verdict is reached by a voting mechanism that utilizes paths produced by the agent. These paths can be presented to human readers so that they themselves can decide whether or not the provided evidence is convincing or not. This work will encourage works in this direction for incorporating RL for explainable fact-checking as it increases trustworthiness by providing a human-in-the-loop approach.
DEAP-FAKED: Knowledge Graph based Approach for Fake News Detection
Jul 04, 2021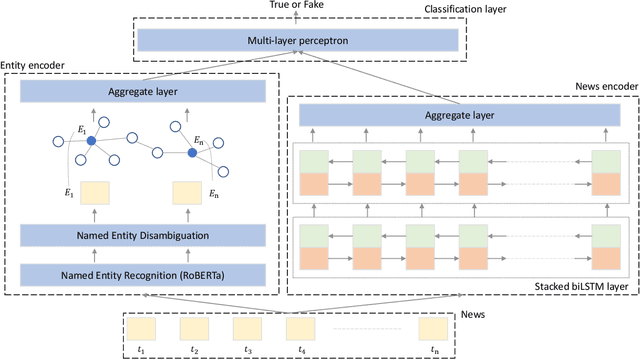


Fake News on social media platforms has attracted a lot of attention in recent times, primarily for events related to politics (2016 US Presidential elections), healthcare (infodemic during COVID-19), to name a few. Various methods have been proposed for detecting Fake News. The approaches span from exploiting techniques related to network analysis, Natural Language Processing (NLP), and the usage of Graph Neural Networks (GNNs). In this work, we propose DEAP-FAKED, a knowleDgE grAPh FAKe nEws Detection framework for identifying Fake News. Our approach is a combination of the NLP -- where we encode the news content, and the GNN technique -- where we encode the Knowledge Graph (KG). A variety of these encodings provides a complementary advantage to our detector. We evaluate our framework using two publicly available datasets containing articles from domains such as politics, business, technology, and healthcare. As part of dataset pre-processing, we also remove the bias, such as the source of the articles, which could impact the performance of the models. DEAP-FAKED obtains an F1-score of 88% and 78% for the two datasets, which is an improvement of 21%, and 3% respectively, which shows the effectiveness of the approach.
Intrinsic analysis for dual word embedding space models
Dec 05, 2020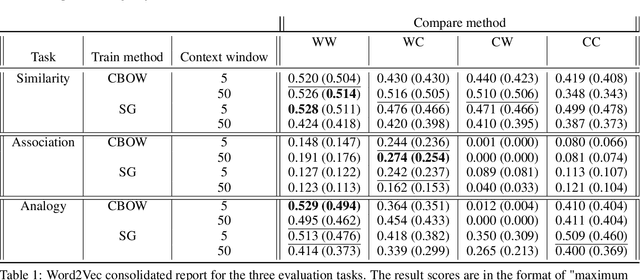
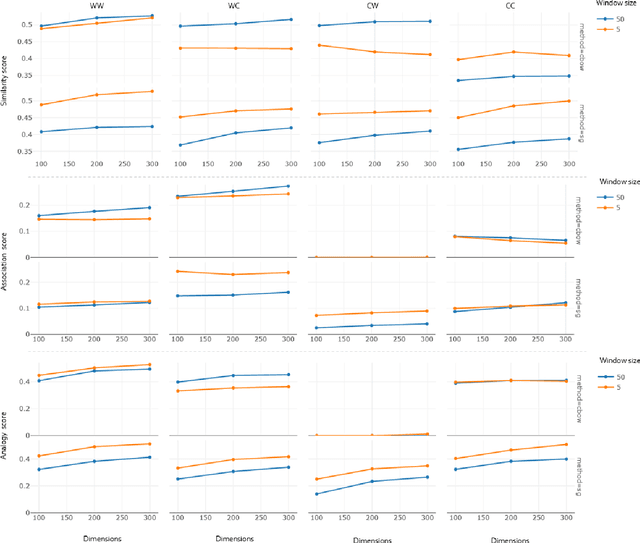
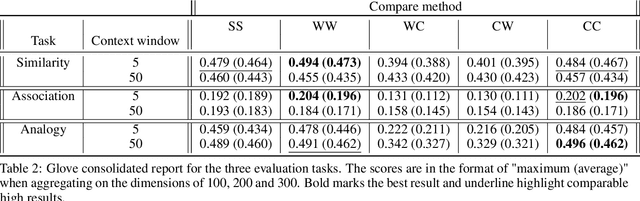
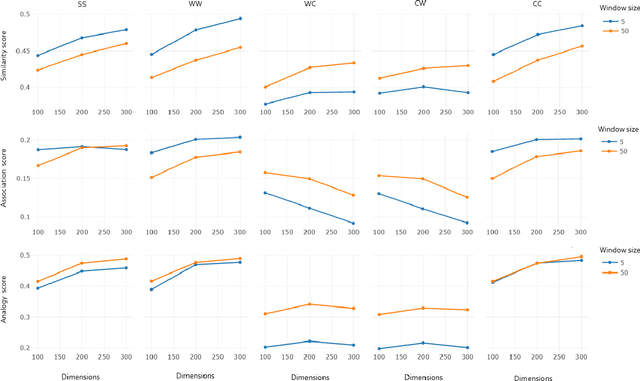
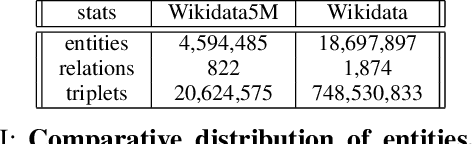
Recent word embeddings techniques represent words in a continuous vector space, moving away from the atomic and sparse representations of the past. Each such technique can further create multiple varieties of embeddings based on different settings of hyper-parameters like embedding dimension size, context window size and training method. One additional variety appears when we especially consider the Dual embedding space techniques which generate not one but two-word embeddings as output. This gives rise to an interesting question - "is there one or a combination of the two word embeddings variety, which works better for a specific task?". This paper tries to answer this question by considering all of these variations. Herein, we compare two classical embedding methods belonging to two different methodologies - Word2Vec from window-based and Glove from count-based. For an extensive evaluation after considering all variations, a total of 84 different models were compared against semantic, association and analogy evaluations tasks which are made up of 9 open-source linguistics datasets. The final Word2vec reports showcase the preference of non-default model for 2 out of 3 tasks. In case of Glove, non-default models outperform in all 3 evaluation tasks.