 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCROSS-JEM: Accurate and Efficient Cross-encoders for Short-text Ranking Tasks
Sep 15, 2024Ranking a set of items based on their relevance to a given query is a core problem in search and recommendation. Transformer-based ranking models are the state-of-the-art approaches for such tasks, but they score each query-item independently, ignoring the joint context of other relevant items. This leads to sub-optimal ranking accuracy and high computational costs. In response, we propose Cross-encoders with Joint Efficient Modeling (CROSS-JEM), a novel ranking approach that enables transformer-based models to jointly score multiple items for a query, maximizing parameter utilization. CROSS-JEM leverages (a) redundancies and token overlaps to jointly score multiple items, that are typically short-text phrases arising in search and recommendations, and (b) a novel training objective that models ranking probabilities. CROSS-JEM achieves state-of-the-art accuracy and over 4x lower ranking latency over standard cross-encoders. Our contributions are threefold: (i) we highlight the gap between the ranking application's need for scoring thousands of items per query and the limited capabilities of current cross-encoders; (ii) we introduce CROSS-JEM for joint efficient scoring of multiple items per query; and (iii) we demonstrate state-of-the-art accuracy on standard public datasets and a proprietary dataset. CROSS-JEM opens up new directions for designing tailored early-attention-based ranking models that incorporate strict production constraints such as item multiplicity and latency.
GANs Settle Scores!
Jun 02, 2023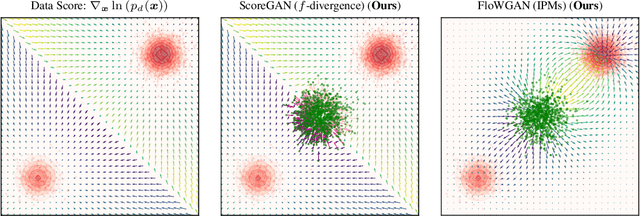



Generative adversarial networks (GANs) comprise a generator, trained to learn the underlying distribution of the desired data, and a discriminator, trained to distinguish real samples from those output by the generator. A majority of GAN literature focuses on understanding the optimality of the discriminator through integral probability metric (IPM) or divergence based analysis. In this paper, we propose a unified approach to analyzing the generator optimization through variational approach. In $f$-divergence-minimizing GANs, we show that the optimal generator is the one that matches the score of its output distribution with that of the data distribution, while in IPM GANs, we show that this optimal generator matches score-like functions, involving the flow-field of the kernel associated with a chosen IPM constraint space. Further, the IPM-GAN optimization can be seen as one of smoothed score-matching, where the scores of the data and the generator distributions are convolved with the kernel associated with the constraint. The proposed approach serves to unify score-based training and existing GAN flavors, leveraging results from normalizing flows, while also providing explanations for empirical phenomena such as the stability of non-saturating GAN losses. Based on these results, we propose novel alternatives to $f$-GAN and IPM-GAN training based on score and flow matching, and discriminator-guided Langevin sampling.
Data Interpolants -- That's What Discriminators in Higher-order Gradient-regularized GANs Are
Jun 01, 2023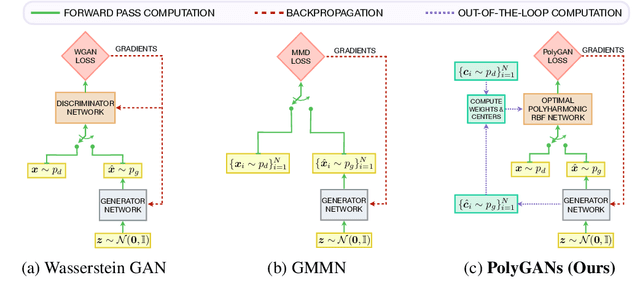



We consider the problem of optimizing the discriminator in generative adversarial networks (GANs) subject to higher-order gradient regularization. We show analytically, via the least-squares (LSGAN) and Wasserstein (WGAN) GAN variants, that the discriminator optimization problem is one of interpolation in $n$-dimensions. The optimal discriminator, derived using variational Calculus, turns out to be the solution to a partial differential equation involving the iterated Laplacian or the polyharmonic operator. The solution is implementable in closed-form via polyharmonic radial basis function (RBF) interpolation. In view of the polyharmonic connection, we refer to the corresponding GANs as Poly-LSGAN and Poly-WGAN. Through experimental validation on multivariate Gaussians, we show that implementing the optimal RBF discriminator in closed-form, with penalty orders $m \approx\lceil \frac{n}{2} \rceil $, results in superior performance, compared to training GAN with arbitrarily chosen discriminator architectures. We employ the Poly-WGAN discriminator to model the latent space distribution of the data with encoder-decoder-based GAN flavors such as Wasserstein autoencoders.
Spider GAN: Leveraging Friendly Neighbors to Accelerate GAN Training
May 12, 2023Training Generative adversarial networks (GANs) stably is a challenging task. The generator in GANs transform noise vectors, typically Gaussian distributed, into realistic data such as images. In this paper, we propose a novel approach for training GANs with images as inputs, but without enforcing any pairwise constraints. The intuition is that images are more structured than noise, which the generator can leverage to learn a more robust transformation. The process can be made efficient by identifying closely related datasets, or a ``friendly neighborhood'' of the target distribution, inspiring the moniker, Spider GAN. To define friendly neighborhoods leveraging proximity between datasets, we propose a new measure called the signed inception distance (SID), inspired by the polyharmonic kernel. We show that the Spider GAN formulation results in faster convergence, as the generator can discover correspondence even between seemingly unrelated datasets, for instance, between Tiny-ImageNet and CelebA faces. Further, we demonstrate cascading Spider GAN, where the output distribution from a pre-trained GAN generator is used as the input to the subsequent network. Effectively, transporting one distribution to another in a cascaded fashion until the target is learnt -- a new flavor of transfer learning. We demonstrate the efficacy of the Spider approach on DCGAN, conditional GAN, PGGAN, StyleGAN2 and StyleGAN3. The proposed approach achieves state-of-the-art Frechet inception distance (FID) values, with one-fifth of the training iterations, in comparison to their baseline counterparts on high-resolution small datasets such as MetFaces, Ukiyo-E Faces and AFHQ-Cats.
Teaching a GAN What Not to Learn
Oct 29, 2020



Generative adversarial networks (GANs) were originally envisioned as unsupervised generative models that learn to follow a target distribution. Variants such as conditional GANs, auxiliary-classifier GANs (ACGANs) project GANs on to supervised and semi-supervised learning frameworks by providing labelled data and using multi-class discriminators. In this paper, we approach the supervised GAN problem from a different perspective, one that is motivated by the philosophy of the famous Persian poet Rumi who said, "The art of knowing is knowing what to ignore." In the GAN framework, we not only provide the GAN positive data that it must learn to model, but also present it with so-called negative samples that it must learn to avoid - we call this "The Rumi Framework." This formulation allows the discriminator to represent the underlying target distribution better by learning to penalize generated samples that are undesirable - we show that this capability accelerates the learning process of the generator. We present a reformulation of the standard GAN (SGAN) and least-squares GAN (LSGAN) within the Rumi setting. The advantage of the reformulation is demonstrated by means of experiments conducted on MNIST, Fashion MNIST, CelebA, and CIFAR-10 datasets. Finally, we consider an application of the proposed formulation to address the important problem of learning an under-represented class in an unbalanced dataset. The Rumi approach results in substantially lower FID scores than the standard GAN frameworks while possessing better generalization capability.