 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormDial: A Comparable Bilingual Synthetic Dialog Dataset for Modeling Social Norm Adherence and Violation
Oct 25, 2023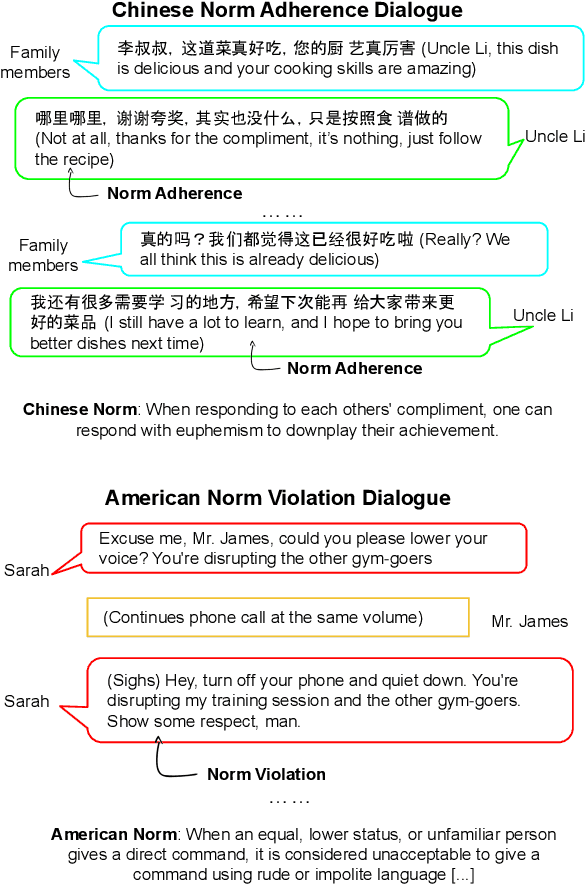

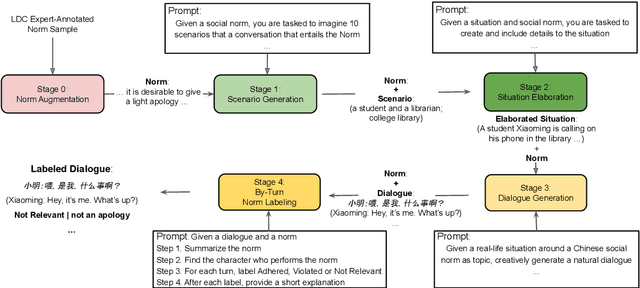
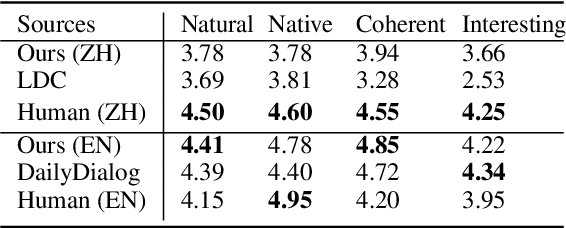
Social norms fundamentally shape interpersonal communication. We present NormDial, a high-quality dyadic dialogue dataset with turn-by-turn annotations of social norm adherences and violations for Chinese and American cultures. Introducing the task of social norm observance detection, our dataset is synthetically generated in both Chinese and English using a human-in-the-loop pipeline by prompting large language models with a small collection of expert-annotated social norms. We show that our generated dialogues are of high quality through human evaluation and further evaluate the performance of existing large language models on this task. Our findings point towards new directions for understanding the nuances of social norms as they manifest in conversational contexts that span across languages and cultures.
Battling Hateful Content in Indic Languages HASOC '21
Nov 05, 2021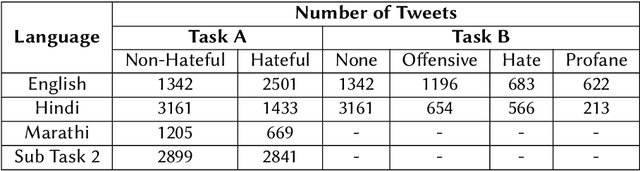
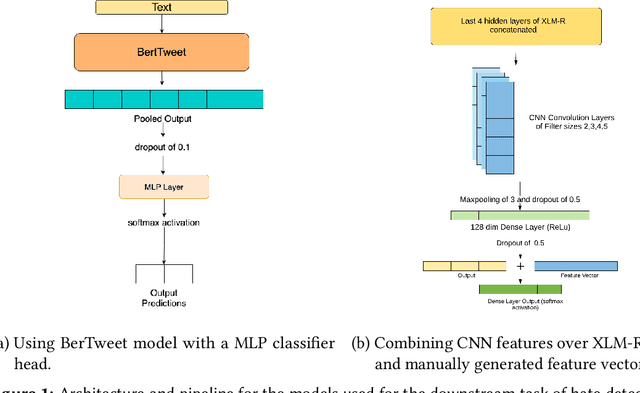
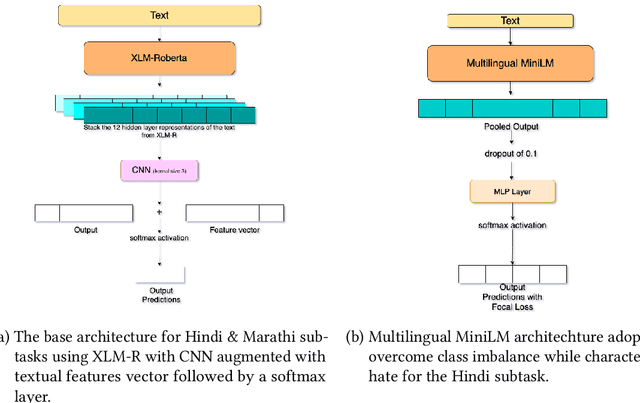
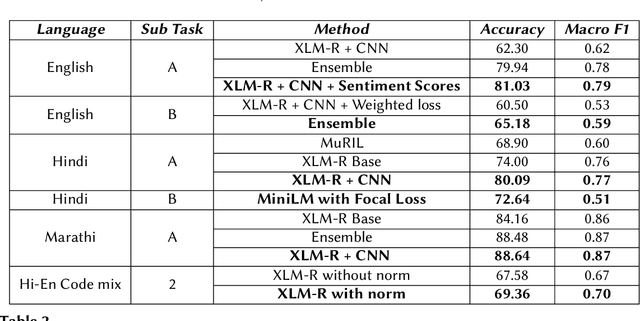
The extensive rise in consumption of online social media (OSMs) by a large number of people poses a critical problem of curbing the spread of hateful content on these platforms. With the growing usage of OSMs in multiple languages, the task of detecting and characterizing hate becomes more complex. The subtle variations of code-mixed texts along with switching scripts only add to the complexity. This paper presents a solution for the HASOC 2021 Multilingual Twitter Hate-Speech Detection challenge by team PreCog IIIT Hyderabad. We adopt a multilingual transformer based approach and describe our architecture for all 6 subtasks as part of the challenge. Out of the 6 teams that participated in all the subtasks, our submissions rank 3rd overall.
Diagnosing Web Data of ICTs to Provide Focused Assistance in Agricultural Adoptions
Oct 29, 2021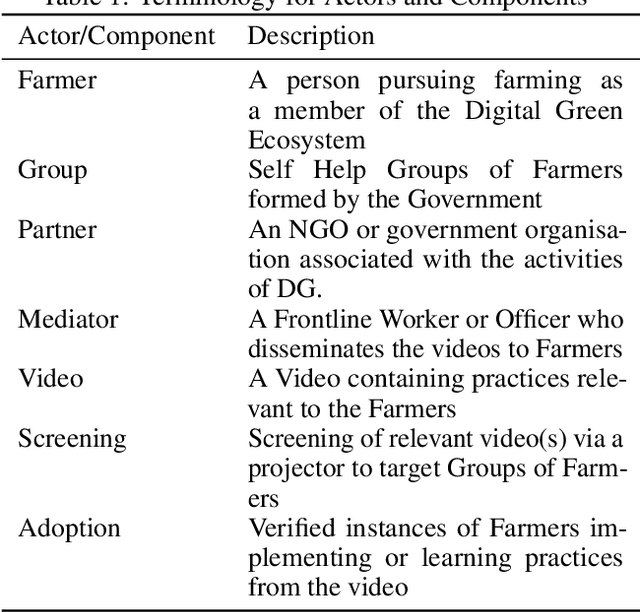


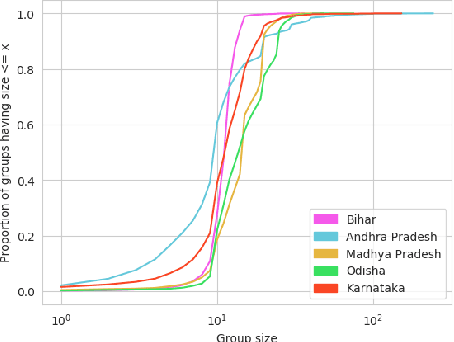
The past decade has witnessed a rapid increase in technology ownership across rural areas of India, signifying the potential for ICT initiatives to empower rural households. In our work, we focus on the web infrastructure of one such ICT - Digital Green that started in 2008. Following a participatory approach for content production, Digital Green disseminates instructional agricultural videos to smallholder farmers via human mediators to improve the adoption of farming practices. Their web-based data tracker, CoCo, captures data related to these processes, storing the attendance and adoption logs of over 2.3 million farmers across three continents and twelve countries. Using this data, we model the components of the Digital Green ecosystem involving the past attendance-adoption behaviours of farmers, the content of the videos screened to them and their demographic features across five states in India. We use statistical tests to identify different factors which distinguish farmers with higher adoption rates to understand why they adopt more than others. Our research finds that farmers with higher adoption rates adopt videos of shorter duration and belong to smaller villages. The co-attendance and co-adoption networks of farmers indicate that they greatly benefit from past adopters of a video from their village and group when it comes to adopting practices from the same video. Following our analysis, we model the adoption of practices from a video as a prediction problem to identify and assist farmers who might face challenges in adoption in each of the five states. We experiment with different model architectures and achieve macro-f1 scores ranging from 79% to 89% using a Random Forest classifier. Finally, we measure the importance of different features using SHAP values and provide implications for improving the adoption rates of nearly a million farmers across five states in India.