 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneity-Aware Client Selection Methodology For Efficient Federated Learning
Feb 24, 2026Federated Learning (FL) enables a distributed client-server architecture where multiple clients collaboratively train a global Machine Learning (ML) model without sharing sensitive local data. However, FL often results in lower accuracy than traditional ML algorithms due to statistical heterogeneity across clients. Prior works attempt to address this by using model updates, such as loss and bias, from client models to select participants that can improve the global model's accuracy. However, these updates neither accurately represent a client's heterogeneity nor are their selection methods deterministic. We mitigate these limitations by introducing Terraform, a novel client selection methodology that uses gradient updates and a deterministic selection algorithm to select heterogeneous clients for retraining. This bi-pronged approach allows Terraform to achieve up to 47 percent higher accuracy over prior works. We further demonstrate its efficiency through comprehensive ablation studies and training time analyses, providing strong justification for the robustness of Terraform.
Transfer Learning via Latent Dependency Factor for Estimating PM 2.5
Apr 10, 2024Air pollution, especially particulate matter 2.5 (PM 2.5), is a pressing concern for public health and is difficult to estimate in developing countries (data-poor regions) due to a lack of ground sensors. Transfer learning models can be leveraged to solve this problem, as they use alternate data sources to gain knowledge (i.e., data from data-rich regions). However, current transfer learning methodologies do not account for dependencies between the source and the target domains. We recognize this transfer problem as spatial transfer learning and propose a new feature named Latent Dependency Factor (LDF) that captures spatial and semantic dependencies of both domains and is subsequently added to the datasets. We generate LDF using a novel two-stage autoencoder model that learns from clusters of similar source and target domain data. Our experiments show that transfer models using LDF have a $19.34\%$ improvement over the best-performing baselines. We additionally support our experiments with qualitative results.
Towards Effective Paraphrasing for Information Disguise
Nov 08, 2023Information Disguise (ID), a part of computational ethics in Natural Language Processing (NLP), is concerned with best practices of textual paraphrasing to prevent the non-consensual use of authors' posts on the Internet. Research on ID becomes important when authors' written online communication pertains to sensitive domains, e.g., mental health. Over time, researchers have utilized AI-based automated word spinners (e.g., SpinRewriter, WordAI) for paraphrasing content. However, these tools fail to satisfy the purpose of ID as their paraphrased content still leads to the source when queried on search engines. There is limited prior work on judging the effectiveness of paraphrasing methods for ID on search engines or their proxies, neural retriever (NeurIR) models. We propose a framework where, for a given sentence from an author's post, we perform iterative perturbation on the sentence in the direction of paraphrasing with an attempt to confuse the search mechanism of a NeurIR system when the sentence is queried on it. Our experiments involve the subreddit 'r/AmItheAsshole' as the source of public content and Dense Passage Retriever as a NeurIR system-based proxy for search engines. Our work introduces a novel method of phrase-importance rankings using perplexity scores and involves multi-level phrase substitutions via beam search. Our multi-phrase substitution scheme succeeds in disguising sentences 82% of the time and hence takes an essential step towards enabling researchers to disguise sensitive content effectively before making it public. We also release the code of our approach.
* Accepted at ECIR 2023
Learning to Automate Follow-up Question Generation using Process Knowledge for Depression Triage on Reddit Posts
May 27, 2022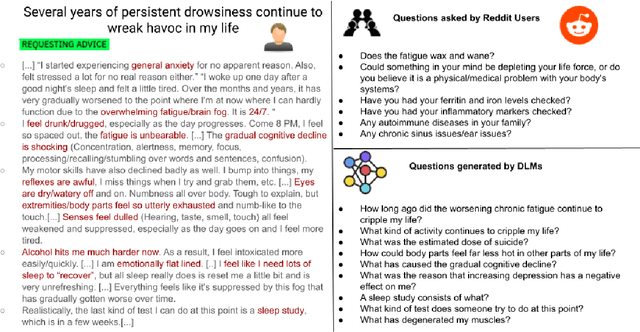

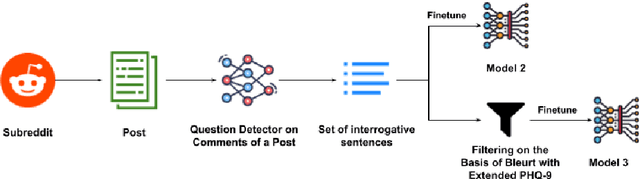
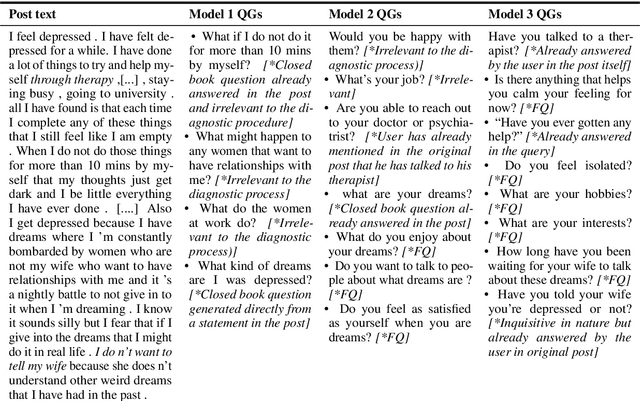
Conversational Agents (CAs) powered with deep language models (DLMs) have shown tremendous promise in the domain of mental health. Prominently, the CAs have been used to provide informational or therapeutic services to patients. However, the utility of CAs to assist in mental health triaging has not been explored in the existing work as it requires a controlled generation of follow-up questions (FQs), which are often initiated and guided by the mental health professionals (MHPs) in clinical settings. In the context of depression, our experiments show that DLMs coupled with process knowledge in a mental health questionnaire generate 12.54% and 9.37% better FQs based on similarity and longest common subsequence matches to questions in the PHQ-9 dataset respectively, when compared with DLMs without process knowledge support. Despite coupling with process knowledge, we find that DLMs are still prone to hallucination, i.e., generating redundant, irrelevant, and unsafe FQs. We demonstrate the challenge of using existing datasets to train a DLM for generating FQs that adhere to clinical process knowledge. To address this limitation, we prepared an extended PHQ-9 based dataset, PRIMATE, in collaboration with MHPs. PRIMATE contains annotations regarding whether a particular question in the PHQ-9 dataset has already been answered in the user's initial description of the mental health condition. We used PRIMATE to train a DLM in a supervised setting to identify which of the PHQ-9 questions can be answered directly from the user's post and which ones would require more information from the user. Using performance analysis based on MCC scores, we show that PRIMATE is appropriate for identifying questions in PHQ-9 that could guide generative DLMs towards controlled FQ generation suitable for aiding triaging. Dataset created as a part of this research: https://github.com/primate-mh/Primate2022
ISTRBoost: Importance Sampling Transfer Regression using Boosting
Apr 26, 2022



Current Instance Transfer Learning (ITL) methodologies use domain adaptation and sub-space transformation to achieve successful transfer learning. However, these methodologies, in their processes, sometimes overfit on the target dataset or suffer from negative transfer if the test dataset has a high variance. Boosting methodologies have been shown to reduce the risk of overfitting by iteratively re-weighing instances with high-residual. However, this balance is usually achieved with parameter optimization, as well as reducing the skewness in weights produced due to the size of the source dataset. While the former can be achieved, the latter is more challenging and can lead to negative transfer. We introduce a simpler and more robust fix to this problem by building upon the popular boosting ITL regression methodology, two-stage TrAdaBoost.R2. Our methodology,~\us{}, is a boosting and random-forest based ensemble methodology that utilizes importance sampling to reduce the skewness due to the source dataset. We show that~\us{}~performs better than competitive transfer learning methodologies $63\%$ of the time. It also displays consistency in its performance over diverse datasets with varying complexities, as opposed to the sporadic results observed for other transfer learning methodologies.
Diagnosing Web Data of ICTs to Provide Focused Assistance in Agricultural Adoptions
Oct 29, 2021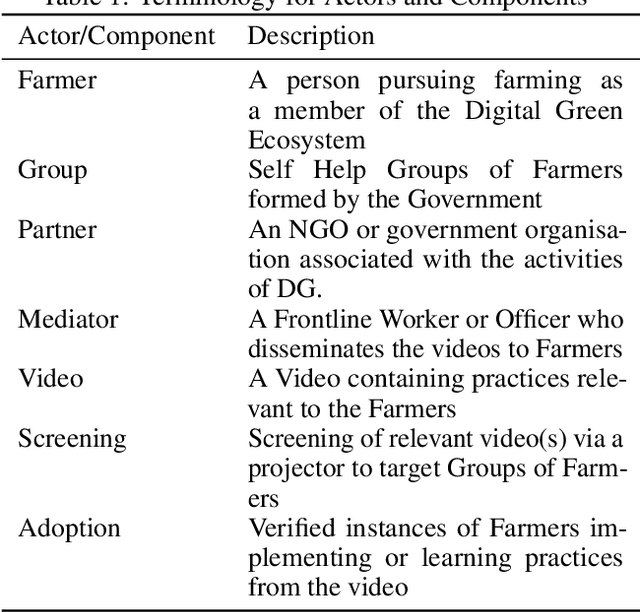


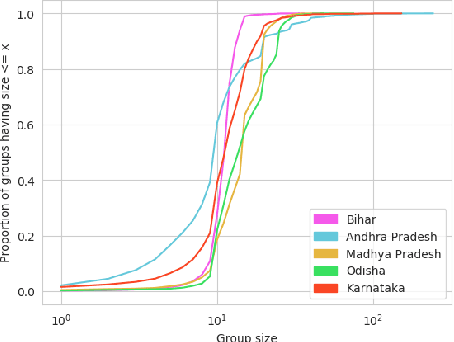
The past decade has witnessed a rapid increase in technology ownership across rural areas of India, signifying the potential for ICT initiatives to empower rural households. In our work, we focus on the web infrastructure of one such ICT - Digital Green that started in 2008. Following a participatory approach for content production, Digital Green disseminates instructional agricultural videos to smallholder farmers via human mediators to improve the adoption of farming practices. Their web-based data tracker, CoCo, captures data related to these processes, storing the attendance and adoption logs of over 2.3 million farmers across three continents and twelve countries. Using this data, we model the components of the Digital Green ecosystem involving the past attendance-adoption behaviours of farmers, the content of the videos screened to them and their demographic features across five states in India. We use statistical tests to identify different factors which distinguish farmers with higher adoption rates to understand why they adopt more than others. Our research finds that farmers with higher adoption rates adopt videos of shorter duration and belong to smaller villages. The co-attendance and co-adoption networks of farmers indicate that they greatly benefit from past adopters of a video from their village and group when it comes to adopting practices from the same video. Following our analysis, we model the adoption of practices from a video as a prediction problem to identify and assist farmers who might face challenges in adoption in each of the five states. We experiment with different model architectures and achieve macro-f1 scores ranging from 79% to 89% using a Random Forest classifier. Finally, we measure the importance of different features using SHAP values and provide implications for improving the adoption rates of nearly a million farmers across five states in India.