 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSF-MAP: Neurosymbolic Multimodal Fusion for Robust and Interpretable Anomaly Prediction in Assembly Pipelines
May 09, 2025In modern assembly pipelines, identifying anomalies is crucial in ensuring product quality and operational efficiency. Conventional single-modality methods fail to capture the intricate relationships required for precise anomaly prediction in complex predictive environments with abundant data and multiple modalities. This paper proposes a neurosymbolic AI and fusion-based approach for multimodal anomaly prediction in assembly pipelines. We introduce a time series and image-based fusion model that leverages decision-level fusion techniques. Our research builds upon three primary novel approaches in multimodal learning: time series and image-based decision-level fusion modeling, transfer learning for fusion, and knowledge-infused learning. We evaluate the novel method using our derived and publicly available multimodal dataset and conduct comprehensive ablation studies to assess the impact of our preprocessing techniques and fusion model compared to traditional baselines. The results demonstrate that a neurosymbolic AI-based fusion approach that uses transfer learning can effectively harness the complementary strengths of time series and image data, offering a robust and interpretable approach for anomaly prediction in assembly pipelines with enhanced performance. \noindent The datasets, codes to reproduce the results, supplementary materials, and demo are available at https://github.com/ChathurangiShyalika/NSF-MAP.
Time-Series Forecasting in Smart Manufacturing Systems: An Experimental Evaluation of the State-of-the-art Algorithms
Nov 26, 2024TSF is growing in various domains including manufacturing. Although numerous TSF algorithms have been developed recently, the validation and evaluation of algorithms hold substantial value for researchers and practitioners and are missing. This study aims to fill this gap by evaluating the SoTA TSF algorithms on thirteen manufacturing datasets, focusing on their applicability in manufacturing. Each algorithm was selected based on its TSF category to ensure a representative set of algorithms. The evaluation includes different scenarios to evaluate the models using two problem categories and two forecasting horizons. To evaluate the performance, the WAPE was calculated, and additional post hoc analyses were conducted to assess the significance of observed differences. Only algorithms with codes from open-source libraries were utilized, and no hyperparameter tuning was done. This allowed us to evaluate the algorithms as "out-of-the-box" solutions that can be easily implemented, ensuring their usability within the manufacturing by practitioners with limited technical knowledge. This aligns to facilitate the adoption of these techniques in smart manufacturing systems. Based on the results, transformer and MLP-based architectures demonstrated the best performance with MLP-based architecture winning the most scenarios. For univariate TSF, PatchTST emerged as the most robust, particularly for long-term horizons, while for multivariate problems, MLP-based architectures like N-HITS and TiDE showed superior results. The study revealed that simpler algorithms like XGBoost could outperform complex algorithms in certain tasks. These findings challenge the assumption that more sophisticated models produce better results. Additionally, the research highlighted the importance of computational resource considerations, showing variations in runtime and memory usage across different algorithms.
AssemAI: Interpretable Image-Based Anomaly Detection for Manufacturing Pipelines
Aug 05, 2024



Anomaly detection in manufacturing pipelines remains a critical challenge, intensified by the complexity and variability of industrial environments. This paper introduces AssemAI, an interpretable image-based anomaly detection system tailored for smart manufacturing pipelines. Our primary contributions include the creation of a tailored image dataset and the development of a custom object detection model, YOLO-FF, designed explicitly for anomaly detection in manufacturing assembly environments. Utilizing the preprocessed image dataset derived from an industry-focused rocket assembly pipeline, we address the challenge of imbalanced image data and demonstrate the importance of image-based methods in anomaly detection. The proposed approach leverages domain knowledge in data preparation, model development and reasoning. We compare our method against several baselines, including simple CNN and custom Visual Transformer (ViT) models, showcasing the effectiveness of our custom data preparation and pretrained CNN integration. Additionally, we incorporate explainability techniques at both user and model levels, utilizing ontology for user-friendly explanations and SCORE-CAM for in-depth feature and model analysis. Finally, the model was also deployed in a real-time setting. Our results include ablation studies on the baselines, providing a comprehensive evaluation of the proposed system. This work highlights the broader impact of advanced image-based anomaly detection in enhancing the reliability and efficiency of smart manufacturing processes.
Evaluating the Role of Data Enrichment Approaches Towards Rare Event Analysis in Manufacturing
Jul 01, 2024Rare events are occurrences that take place with a significantly lower frequency than more common regular events. In manufacturing, predicting such events is particularly important, as they lead to unplanned downtime, shortening equipment lifespan, and high energy consumption. The occurrence of events is considered frequently-rare if observed in more than 10% of all instances, very-rare if it is 1-5%, moderately-rare if it is 5-10%, and extremely-rare if less than 1%. The rarity of events is inversely correlated with the maturity of a manufacturing industry. Typically, the rarity of events affects the multivariate data generated within a manufacturing process to be highly imbalanced, which leads to bias in predictive models. This paper evaluates the role of data enrichment techniques combined with supervised machine-learning techniques for rare event detection and prediction. To address the data scarcity, we use time series data augmentation and sampling methods to amplify the dataset with more multivariate features and data points while preserving the underlying time series patterns in the combined alterations. Imputation techniques are used in handling null values in datasets. Considering 15 learning models ranging from statistical learning to machine learning to deep learning methods, the best-performing model for the selected datasets is obtained and the efficacy of data enrichment is evaluated. Based on this evaluation, our results find that the enrichment procedure enhances up to 48% of F1 measure in rare failure event detection and prediction of supervised prediction models. We also conduct empirical and ablation experiments on the datasets to derive dataset-specific novel insights. Finally, we investigate the interpretability aspect of models for rare event prediction, considering multiple methods.
Analog and Multi-modal Manufacturing Datasets Acquired on the Future Factories Platform
Jan 28, 2024

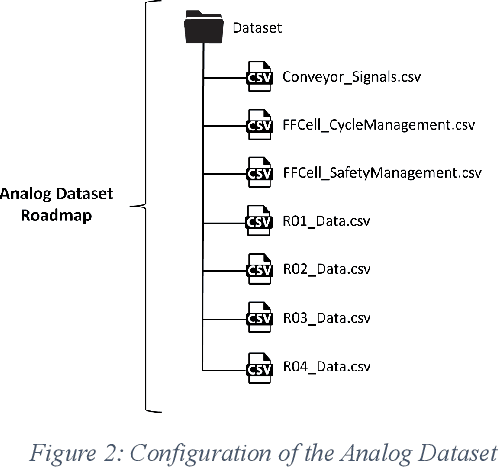
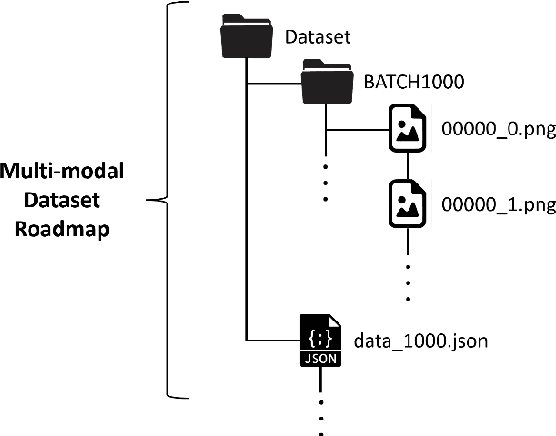
Two industry-grade datasets are presented in this paper that were collected at the Future Factories Lab at the University of South Carolina on December 11th and 12th of 2023. These datasets are generated by a manufacturing assembly line that utilizes industrial standards with respect to actuators, control mechanisms, and transducers. The two datasets were both generated simultaneously by operating the assembly line for 30 consecutive hours (with minor filtering) and collecting data from sensors equipped throughout the system. During operation, defects were also introduced into the assembly operation by manually removing parts needed for the final assembly. The datasets generated include a time series analog dataset and the other is a time series multi-modal dataset which includes images of the system alongside the analog data. These datasets were generated with the objective of providing tools to further the research towards enhancing intelligence in manufacturing. Real manufacturing datasets can be scarce let alone datasets with anomalies or defects. As such these datasets hope to address this gap and provide researchers with a foundation to build and train Artificial Intelligence models applicable for the manufacturing industry. Finally, these datasets are the first iteration of published data from the future Factories lab and can be further adjusted to fit more researchers needs moving forward.