 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Connection between Pre-training Data Diversity and Fine-tuning Robustness
Paper and Code
Jul 24, 2023

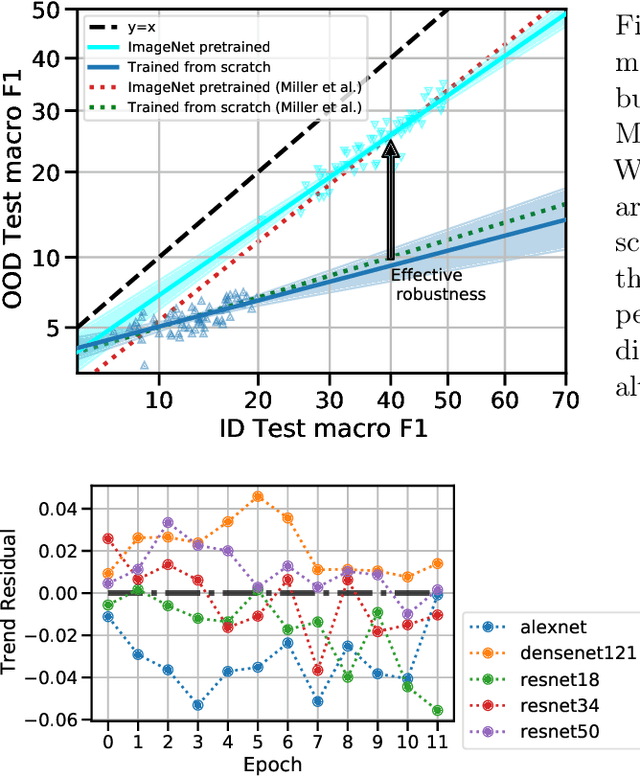

Pre-training has been widely adopted in deep learning to improve model performance, especially when the training data for a target task is limited. In our work, we seek to understand the implications of this training strategy on the generalization properties of downstream models. More specifically, we ask the following question: how do properties of the pre-training distribution affect the robustness of a fine-tuned model? The properties we explore include the label space, label semantics, image diversity, data domains, and data quantity of the pre-training distribution. We find that the primary factor influencing downstream effective robustness (Taori et al., 2020) is data quantity, while other factors have limited significance. For example, reducing the number of ImageNet pre-training classes by 4x while increasing the number of images per class by 4x (that is, keeping total data quantity fixed) does not impact the robustness of fine-tuned models. We demonstrate our findings on pre-training distributions drawn from various natural and synthetic data sources, primarily using the iWildCam-WILDS distribution shift as a test for downstream robustness.