 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Very Long Video Understanding
Jan 26, 2026The advent of always-on personal AI assistants, enabled by all-day wearable devices such as smart glasses, demands a new level of contextual understanding, one that goes beyond short, isolated events to encompass the continuous, longitudinal stream of egocentric video. Achieving this vision requires advances in long-horizon video understanding, where systems must interpret and recall visual and audio information spanning days or even weeks. Existing methods, including large language models and retrieval-augmented generation, are constrained by limited context windows and lack the ability to perform compositional, multi-hop reasoning over very long video streams. In this work, we address these challenges through EGAgent, an enhanced agentic framework centered on entity scene graphs, which represent people, places, objects, and their relationships over time. Our system equips a planning agent with tools for structured search and reasoning over these graphs, as well as hybrid visual and audio search capabilities, enabling detailed, cross-modal, and temporally coherent reasoning. Experiments on the EgoLifeQA and Video-MME (Long) datasets show that our method achieves state-of-the-art performance on EgoLifeQA (57.5%) and competitive performance on Video-MME (Long) (74.1%) for complex longitudinal video understanding tasks.
Sparks of Cooperative Reasoning: LLMs as Strategic Hanabi Agents
Jan 26, 2026Cooperative reasoning under incomplete information remains challenging for both humans and multi-agent systems. The card game Hanabi embodies this challenge, requiring theory-of-mind reasoning and strategic communication. We benchmark 17 state-of-the-art LLM agents in 2-5 player games and study the impact of context engineering across model scales (4B to 600B+) to understand persistent coordination failures and robustness to scaffolding: from a minimal prompt with only explicit card details (Watson setting), to scaffolding with programmatic, Bayesian-motivated deductions (Sherlock setting), to multi-turn state tracking via working memory (Mycroft setting). We show that (1) agents can maintain an internal working memory for state tracking and (2) cross-play performance between different LLMs smoothly interpolates with model strength. In the Sherlock setting, the strongest reasoning models exceed 15 points on average across player counts, yet still trail experienced humans and specialist Hanabi agents, both consistently scoring above 20. We release the first public Hanabi datasets with annotated trajectories and move utilities: (1) HanabiLogs, containing 1,520 full game logs for instruction tuning, and (2) HanabiRewards, containing 560 games with dense move-level value annotations for all candidate moves. Supervised and RL finetuning of a 4B open-weight model (Qwen3-Instruct) on our datasets improves cooperative Hanabi play by 21% and 156% respectively, bringing performance to within ~3 points of a strong proprietary reasoning model (o4-mini) and surpassing the best non-reasoning model (GPT-4.1) by 52%. The HanabiRewards RL-finetuned model further generalizes beyond Hanabi, improving performance on a cooperative group-guessing benchmark by 11%, temporal reasoning on EventQA by 6.4%, instruction-following on IFBench-800K by 1.7 Pass@10, and matching AIME 2025 mathematical reasoning Pass@10.
CuRe: Cultural Gaps in the Long Tail of Text-to-Image Systems
Jun 09, 2025Popular text-to-image (T2I) systems are trained on web-scraped data, which is heavily Amero and Euro-centric, underrepresenting the cultures of the Global South. To analyze these biases, we introduce CuRe, a novel and scalable benchmarking and scoring suite for cultural representativeness that leverages the marginal utility of attribute specification to T2I systems as a proxy for human judgments. Our CuRe benchmark dataset has a novel categorical hierarchy built from the crowdsourced Wikimedia knowledge graph, with 300 cultural artifacts across 32 cultural subcategories grouped into six broad cultural axes (food, art, fashion, architecture, celebrations, and people). Our dataset's categorical hierarchy enables CuRe scorers to evaluate T2I systems by analyzing their response to increasing the informativeness of text conditioning, enabling fine-grained cultural comparisons. We empirically observe much stronger correlations of our class of scorers to human judgments of perceptual similarity, image-text alignment, and cultural diversity across image encoders (SigLIP 2, AIMV2 and DINOv2), vision-language models (OpenCLIP, SigLIP 2, Gemini 2.0 Flash) and state-of-the-art text-to-image systems, including three variants of Stable Diffusion (1.5, XL, 3.5 Large), FLUX.1 [dev], Ideogram 2.0, and DALL-E 3. The code and dataset is open-sourced and available at https://aniketrege.github.io/cure/.
PAL: Pluralistic Alignment Framework for Learning from Heterogeneous Preferences
Jun 12, 2024



Large foundation models pretrained on raw web-scale data are not readily deployable without additional step of extensive alignment to human preferences. Such alignment is typically done by collecting large amounts of pairwise comparisons from humans ("Do you prefer output A or B?") and learning a reward model or a policy with the Bradley-Terry-Luce (BTL) model as a proxy for a human's underlying implicit preferences. These methods generally suffer from assuming a universal preference shared by all humans, which lacks the flexibility of adapting to plurality of opinions and preferences. In this work, we propose PAL, a framework to model human preference complementary to existing pretraining strategies, which incorporates plurality from the ground up. We propose using the ideal point model as a lens to view alignment using preference comparisons. Together with our novel reformulation and using mixture modeling, our framework captures the plurality of population preferences while simultaneously learning a common preference latent space across different preferences, which can few-shot generalize to new, unseen users. Our approach enables us to use the penultimate-layer representation of large foundation models and simple MLP layers to learn reward functions that are on-par with the existing large state-of-the-art reward models, thereby enhancing efficiency of reward modeling significantly. We show that PAL achieves competitive reward model accuracy compared to strong baselines on 1) Language models with Summary dataset ; 2) Image Generative models with Pick-a-Pic dataset ; 3) A new semisynthetic heterogeneous dataset generated using Anthropic Personas. Finally, our experiments also highlight the shortcoming of current preference datasets that are created using rigid rubrics which wash away heterogeneity, and call for more nuanced data collection approaches.
AdANNS: A Framework for Adaptive Semantic Search
May 30, 2023



Web-scale search systems learn an encoder to embed a given query which is then hooked into an approximate nearest neighbor search (ANNS) pipeline to retrieve similar data points. To accurately capture tail queries and data points, learned representations typically are rigid, high-dimensional vectors that are generally used as-is in the entire ANNS pipeline and can lead to computationally expensive retrieval. In this paper, we argue that instead of rigid representations, different stages of ANNS can leverage adaptive representations of varying capacities to achieve significantly better accuracy-compute trade-offs, i.e., stages of ANNS that can get away with more approximate computation should use a lower-capacity representation of the same data point. To this end, we introduce AdANNS, a novel ANNS design framework that explicitly leverages the flexibility of Matryoshka Representations. We demonstrate state-of-the-art accuracy-compute trade-offs using novel AdANNS-based key ANNS building blocks like search data structures (AdANNS-IVF) and quantization (AdANNS-OPQ). For example on ImageNet retrieval, AdANNS-IVF is up to 1.5% more accurate than the rigid representations-based IVF at the same compute budget; and matches accuracy while being up to 90x faster in wall-clock time. For Natural Questions, 32-byte AdANNS-OPQ matches the accuracy of the 64-byte OPQ baseline constructed using rigid representations -- same accuracy at half the cost! We further show that the gains from AdANNS translate to modern-day composite ANNS indices that combine search structures and quantization. Finally, we demonstrate that AdANNS can enable inference-time adaptivity for compute-aware search on ANNS indices built non-adaptively on matryoshka representations. Code is open-sourced at https://github.com/RAIVNLab/AdANNS.
Matryoshka Representations for Adaptive Deployment
Jun 01, 2022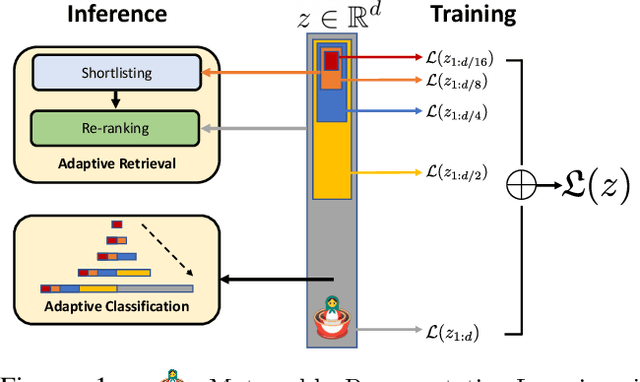
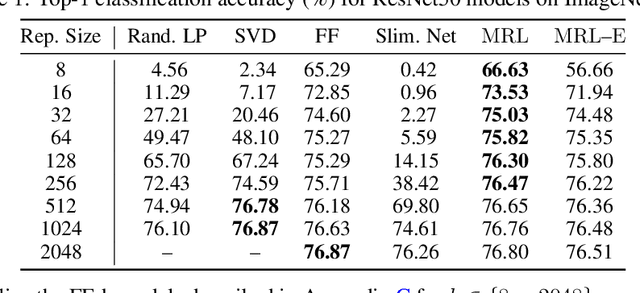
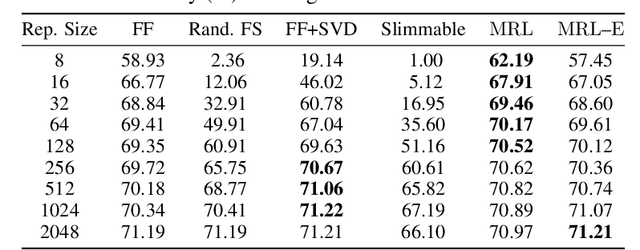
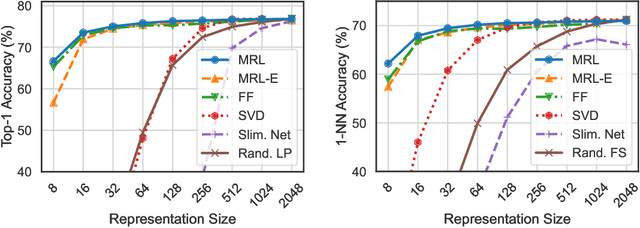
Learned representations are a central component in modern ML systems, serving a multitude of downstream tasks. When training such representations, it is often the case that computational and statistical constraints for each downstream task are unknown. In this context rigid, fixed capacity representations can be either over or under-accommodating to the task at hand. This leads us to ask: can we design a flexible representation that can adapt to multiple downstream tasks with varying computational resources? Our main contribution is Matryoshka Representation Learning (MRL) which encodes information at different granularities and allows a single embedding to adapt to the computational constraints of downstream tasks. MRL minimally modifies existing representation learning pipelines and imposes no additional cost during inference and deployment. MRL learns coarse-to-fine representations that are at least as accurate and rich as independently trained low-dimensional representations. The flexibility within the learned Matryoshka Representations offer: (a) up to 14x smaller embedding size for ImageNet-1K classification at the same level of accuracy; (b) up to 14x real-world speed-ups for large-scale retrieval on ImageNet-1K and 4K; and (c) up to 2% accuracy improvements for long-tail few-shot classification, all while being as robust as the original representations. Finally, we show that MRL extends seamlessly to web-scale datasets (ImageNet, JFT) across various modalities -- vision (ViT, ResNet), vision + language (ALIGN) and language (BERT). MRL code and pretrained models are open-sourced at https://github.com/RAIVNLab/MRL.
Spatio-Temporal Video Representation Learning for AI Based Video Playback Style Prediction
Oct 03, 2021
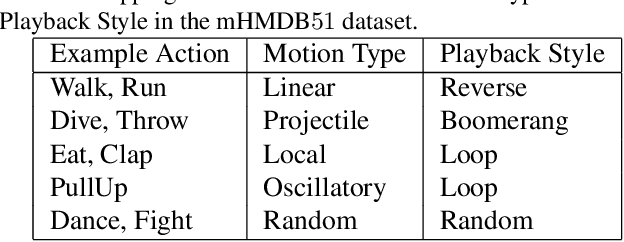
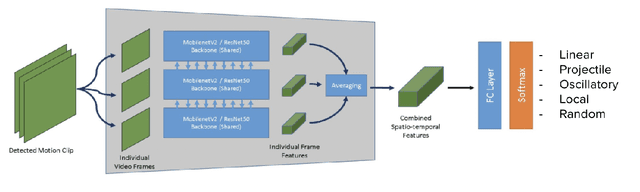
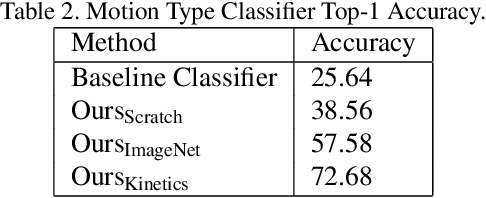
Ever-increasing smartphone-generated video content demands intelligent techniques to edit and enhance videos on power-constrained devices. Most of the best performing algorithms for video understanding tasks like action recognition, localization, etc., rely heavily on rich spatio-temporal representations to make accurate predictions. For effective learning of the spatio-temporal representation, it is crucial to understand the underlying object motion patterns present in the video. In this paper, we propose a novel approach for understanding object motions via motion type classification. The proposed motion type classifier predicts a motion type for the video based on the trajectories of the objects present. Our classifier assigns a motion type for the given video from the following five primitive motion classes: linear, projectile, oscillatory, local and random. We demonstrate that the representations learned from the motion type classification generalizes well for the challenging downstream task of video retrieval. Further, we proposed a recommendation system for video playback style based on the motion type classifier predictions.