 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColorGrid: A Multi-Agent Non-Stationary Environment for Goal Inference and Assistance
Jan 17, 2025Autonomous agents' interactions with humans are increasingly focused on adapting to their changing preferences in order to improve assistance in real-world tasks. Effective agents must learn to accurately infer human goals, which are often hidden, to collaborate well. However, existing Multi-Agent Reinforcement Learning (MARL) environments lack the necessary attributes required to rigorously evaluate these agents' learning capabilities. To this end, we introduce ColorGrid, a novel MARL environment with customizable non-stationarity, asymmetry, and reward structure. We investigate the performance of Independent Proximal Policy Optimization (IPPO), a state-of-the-art (SOTA) MARL algorithm, in ColorGrid and find through extensive ablations that, particularly with simultaneous non-stationary and asymmetric goals between a ``leader'' agent representing a human and a ``follower'' assistant agent, ColorGrid is unsolved by IPPO. To support benchmarking future MARL algorithms, we release our environment code, model checkpoints, and trajectory visualizations at https://github.com/andreyrisukhin/ColorGrid.
Superposed Decoding: Multiple Generations from a Single Autoregressive Inference Pass
May 29, 2024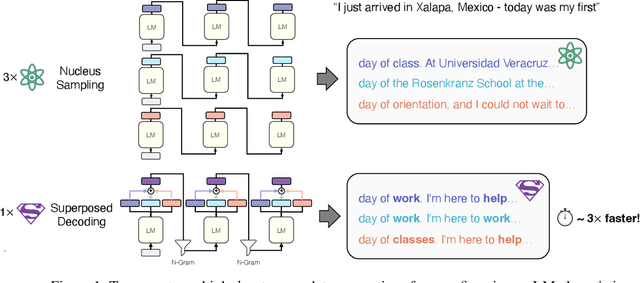

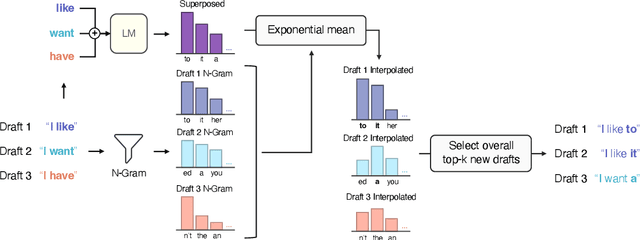

Many applications today provide users with multiple auto-complete drafts as they type, including GitHub's code completion, Gmail's smart compose, and Apple's messaging auto-suggestions. Under the hood, language models support this by running an autoregressive inference pass to provide a draft. Consequently, providing $k$ drafts to the user requires running an expensive language model $k$ times. To alleviate the computation cost of running $k$ inference passes, we propose Superposed Decoding, a new decoding algorithm that generates $k$ drafts at the computation cost of one autoregressive inference pass. We achieve this by feeding a superposition of the most recent token embeddings from the $k$ drafts as input to the next decoding step of the language model. At every inference step we combine the $k$ drafts with the top-$k$ tokens to get $k^2$ new drafts and cache the $k$ most likely options, using an n-gram interpolation with minimal compute overhead to filter out incoherent generations. Our experiments show that $k$ drafts from Superposed Decoding are at least as coherent and factual as Nucleus Sampling and Greedy Decoding respectively, while being at least $2.44\times$ faster for $k\ge3$. In a compute-normalized setting, user evaluations demonstrably favor text generated by Superposed Decoding over Nucleus Sampling. Code and more examples open-sourced at https://github.com/RAIVNLab/SuperposedDecoding.
Objaverse-XL: A Universe of 10M+ 3D Objects
Jul 11, 2023Natural language processing and 2D vision models have attained remarkable proficiency on many tasks primarily by escalating the scale of training data. However, 3D vision tasks have not seen the same progress, in part due to the challenges of acquiring high-quality 3D data. In this work, we present Objaverse-XL, a dataset of over 10 million 3D objects. Our dataset comprises deduplicated 3D objects from a diverse set of sources, including manually designed objects, photogrammetry scans of landmarks and everyday items, and professional scans of historic and antique artifacts. Representing the largest scale and diversity in the realm of 3D datasets, Objaverse-XL enables significant new possibilities for 3D vision. Our experiments demonstrate the improvements enabled with the scale provided by Objaverse-XL. We show that by training Zero123 on novel view synthesis, utilizing over 100 million multi-view rendered images, we achieve strong zero-shot generalization abilities. We hope that releasing Objaverse-XL will enable further innovations in the field of 3D vision at scale.
AdANNS: A Framework for Adaptive Semantic Search
May 30, 2023



Web-scale search systems learn an encoder to embed a given query which is then hooked into an approximate nearest neighbor search (ANNS) pipeline to retrieve similar data points. To accurately capture tail queries and data points, learned representations typically are rigid, high-dimensional vectors that are generally used as-is in the entire ANNS pipeline and can lead to computationally expensive retrieval. In this paper, we argue that instead of rigid representations, different stages of ANNS can leverage adaptive representations of varying capacities to achieve significantly better accuracy-compute trade-offs, i.e., stages of ANNS that can get away with more approximate computation should use a lower-capacity representation of the same data point. To this end, we introduce AdANNS, a novel ANNS design framework that explicitly leverages the flexibility of Matryoshka Representations. We demonstrate state-of-the-art accuracy-compute trade-offs using novel AdANNS-based key ANNS building blocks like search data structures (AdANNS-IVF) and quantization (AdANNS-OPQ). For example on ImageNet retrieval, AdANNS-IVF is up to 1.5% more accurate than the rigid representations-based IVF at the same compute budget; and matches accuracy while being up to 90x faster in wall-clock time. For Natural Questions, 32-byte AdANNS-OPQ matches the accuracy of the 64-byte OPQ baseline constructed using rigid representations -- same accuracy at half the cost! We further show that the gains from AdANNS translate to modern-day composite ANNS indices that combine search structures and quantization. Finally, we demonstrate that AdANNS can enable inference-time adaptivity for compute-aware search on ANNS indices built non-adaptively on matryoshka representations. Code is open-sourced at https://github.com/RAIVNLab/AdANNS.