 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-time Unlearning Using Conformal Prediction
Feb 03, 2026Machine unlearning is the process of efficiently removing specific information from a trained machine learning model without retraining from scratch. Existing unlearning methods, which often provide provable guarantees, typically involve retraining a subset of model parameters based on a forget set. While these approaches show promise in certain scenarios, their underlying assumptions are often challenged in real-world applications -- particularly when applied to generative models. Furthermore, updating parameters using these unlearning procedures often degrades the general-purpose capabilities the model acquired during pre-training. Motivated by these shortcomings, this paper considers the paradigm of inference time unlearning -- wherein, the generative model is equipped with an (approximately correct) verifier that judges whether the model's response satisfies appropriate unlearning guarantees. This paper introduces a framework that iteratively refines the quality of the generated responses using feedback from the verifier without updating the model parameters. The proposed framework leverages conformal prediction to reduce computational overhead and provide distribution-free unlearning guarantees. This paper's approach significantly outperforms existing state-of-the-art methods, reducing unlearning error by up to 93% across challenging unlearning benchmarks.
Linear Transformer Topological Masking with Graph Random Features
Oct 04, 2024



When training transformers on graph-structured data, incorporating information about the underlying topology is crucial for good performance. Topological masking, a type of relative position encoding, achieves this by upweighting or downweighting attention depending on the relationship between the query and keys in a graph. In this paper, we propose to parameterise topological masks as a learnable function of a weighted adjacency matrix -- a novel, flexible approach which incorporates a strong structural inductive bias. By approximating this mask with graph random features (for which we prove the first known concentration bounds), we show how this can be made fully compatible with linear attention, preserving $\mathcal{O}(N)$ time and space complexity with respect to the number of input tokens. The fastest previous alternative was $\mathcal{O}(N \log N)$ and only suitable for specific graphs. Our efficient masking algorithms provide strong performance gains for tasks on image and point cloud data, including with $>30$k nodes.
Conditioned Language Policy: A General Framework for Steerable Multi-Objective Finetuning
Jul 22, 2024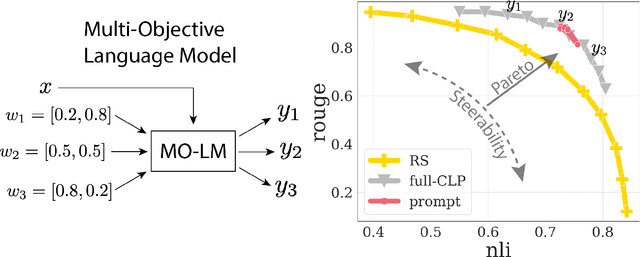
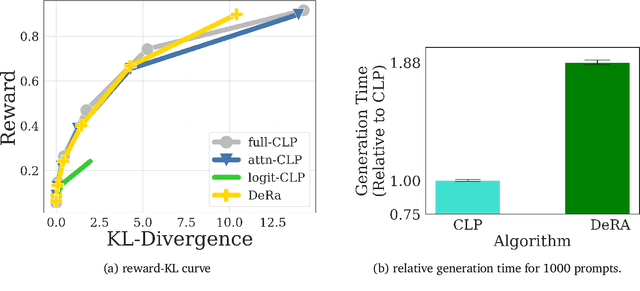
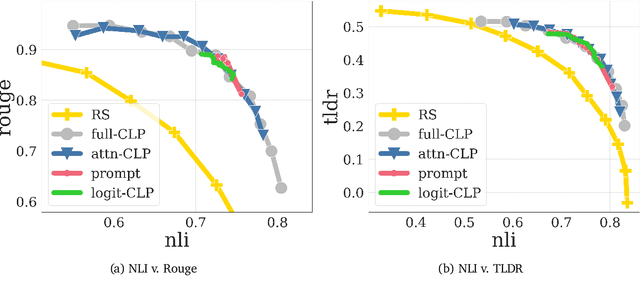
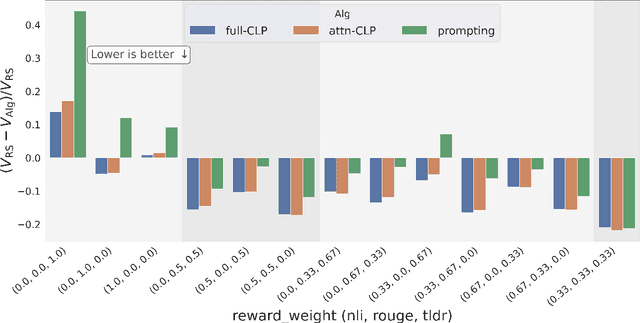
Reward-based finetuning is crucial for aligning language policies with intended behaviors (e.g., creativity and safety). A key challenge here is to develop steerable language models that trade-off multiple (conflicting) objectives in a flexible and efficient manner. This paper presents Conditioned Language Policy (CLP), a general framework for finetuning language models on multiple objectives. Building on techniques from multi-task training and parameter-efficient finetuning, CLP can learn steerable models that effectively trade-off conflicting objectives at inference time. Notably, this does not require training or maintaining multiple models to achieve different trade-offs between the objectives. Through an extensive set of experiments and ablations, we show that the CLP framework learns steerable models that outperform and Pareto-dominate the current state-of-the-art approaches for multi-objective finetuning.
Deep Reinforcement Learning for Sequential Combinatorial Auctions
Jul 10, 2024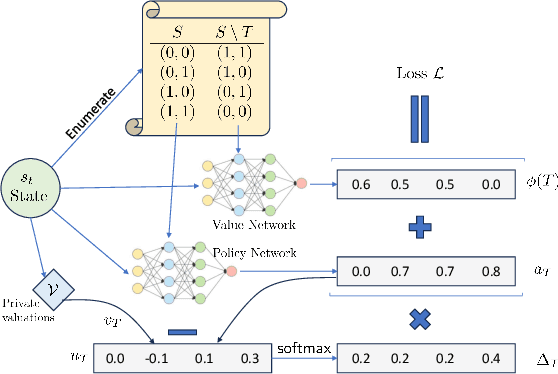
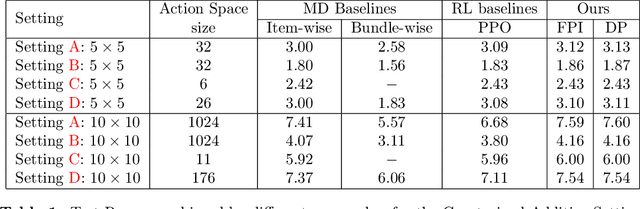
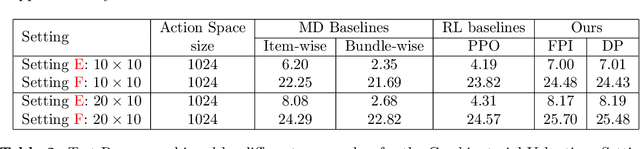

Revenue-optimal auction design is a challenging problem with significant theoretical and practical implications. Sequential auction mechanisms, known for their simplicity and strong strategyproofness guarantees, are often limited by theoretical results that are largely existential, except for certain restrictive settings. Although traditional reinforcement learning methods such as Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC) are applicable in this domain, they struggle with computational demands and convergence issues when dealing with large and continuous action spaces. In light of this and recognizing that we can model transitions differentiable for our settings, we propose using a new reinforcement learning framework tailored for sequential combinatorial auctions that leverages first-order gradients. Our extensive evaluations show that our approach achieves significant improvement in revenue over both analytical baselines and standard reinforcement learning algorithms. Furthermore, we scale our approach to scenarios involving up to 50 agents and 50 items, demonstrating its applicability in complex, real-world auction settings. As such, this work advances the computational tools available for auction design and contributes to bridging the gap between theoretical results and practical implementations in sequential auction design.
Auctions with LLM Summaries
Apr 11, 2024We study an auction setting in which bidders bid for placement of their content within a summary generated by a large language model (LLM), e.g., an ad auction in which the display is a summary paragraph of multiple ads. This generalizes the classic ad settings such as position auctions to an LLM generated setting, which allows us to handle general display formats. We propose a novel factorized framework in which an auction module and an LLM module work together via a prediction model to provide welfare maximizing summary outputs in an incentive compatible manner. We provide a theoretical analysis of this framework and synthetic experiments to demonstrate the feasibility and validity of the system together with welfare comparisons.
User Response in Ad Auctions: An MDP Formulation of Long-Term Revenue Optimization
Feb 16, 2023We propose a new Markov Decision Process (MDP) model for ad auctions to capture the user response to the quality of ads, with the objective of maximizing the long-term discounted revenue. By incorporating user response, our model takes into consideration all three parties involved in the auction (advertiser, auctioneer, and user). The state of the user is modeled as a user-specific click-through rate (CTR) with the CTR changing in the next round according to the set of ads shown to the user in the current round. We characterize the optimal mechanism for this MDP as a Myerson's auction with a notion of modified virtual value, which relies on the value distribution of the advertiser, the current user state, and the future impact of showing the ad to the user. Moreover, we propose a simple mechanism built upon second price auctions with personalized reserve prices and show it can achieve a constant-factor approximation to the optimal long term discounted revenue.
Learning Robust Algorithms for Online Allocation Problems Using Adversarial Training
Oct 16, 2020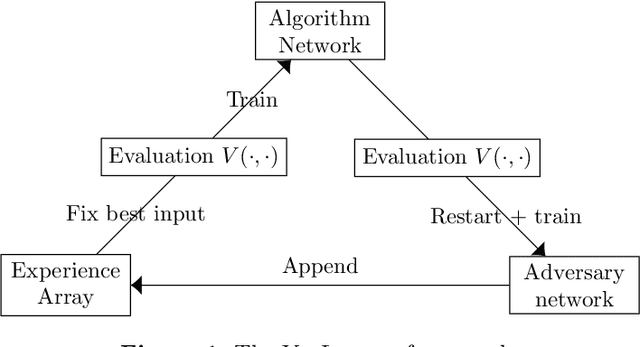
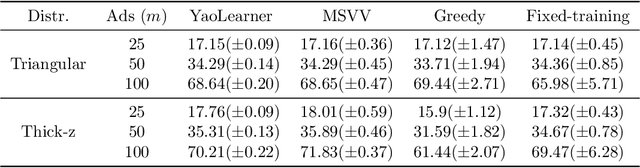
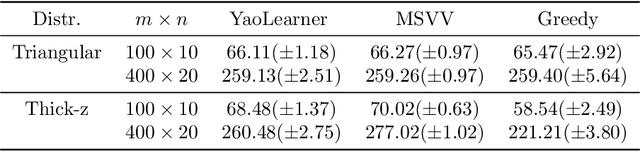
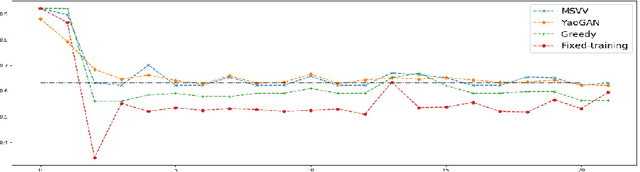
We address the challenge of finding algorithms for online allocation (i.e. bipartite matching) using a machine learning approach. In this paper, we focus on the AdWords problem, which is a classical online budgeted matching problem of both theoretical and practical significance. In contrast to existing work, our goal is to accomplish algorithm design {\em tabula rasa}, i.e., without any human-provided insights or expert-tuned training data beyond specifying the objective and constraints of the optimization problem. We construct a framework based on insights and ideas from game theory, adversarial training and GANs Key to our approach is to generate adversarial examples that expose the weakness of any given algorithm. A unique challenge in our context is to generate complete examples from scratch rather than perturbing given examples and we demonstrate this can be accomplished for the Adwords problem. We use this framework to co-train an algorithm network and an adversarial network against each other until they converge to an equilibrium. This approach finds algorithms and adversarial examples that are consistent with known optimal results. Secondly, we address the question of robustness of the algorithm, namely can we design algorithms that are both strong under practical distributions, as well as exhibit robust performance against adversarial instances. To accomplish this, we train algorithm networks using a mixture of adversarial and practical distributions like power-laws; the resulting networks exhibit a smooth trade-off between the two input regimes.