 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShopTalk: A System for Conversational Faceted Search
Sep 02, 2021


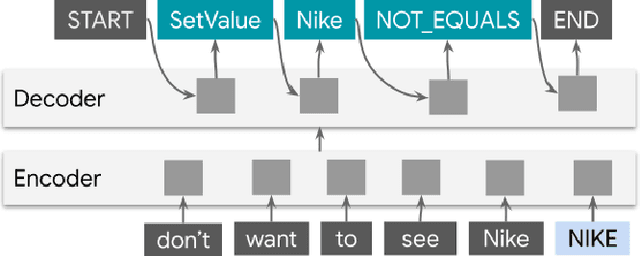
We present ShopTalk, a multi-turn conversational faceted search system for shopping that is designed to handle large and complex schemas that are beyond the scope of state of the art slot-filling systems. ShopTalk decouples dialog management from fulfillment, thereby allowing the dialog understanding system to be domain-agnostic and not tied to the particular shopping application. The dialog understanding system consists of a deep-learned Contextual Language Understanding module, which interprets user utterances, and a primarily rules-based Dialog-State Tracker (DST), which updates the dialog state and formulates search requests intended for the fulfillment engine. The interface between the two modules consists of a minimal set of domain-agnostic "intent operators," which instruct the DST on how to update the dialog state. ShopTalk was deployed in 2020 on the Google Assistant for Shopping searches.
Learning Robust Algorithms for Online Allocation Problems Using Adversarial Training
Oct 16, 2020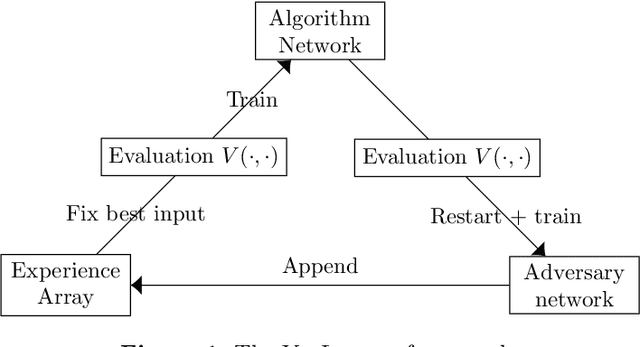
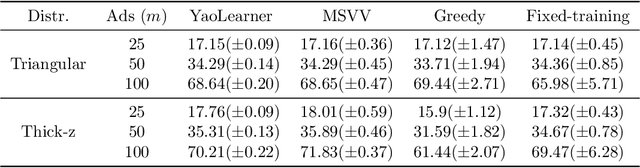
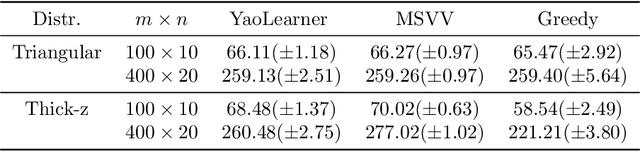
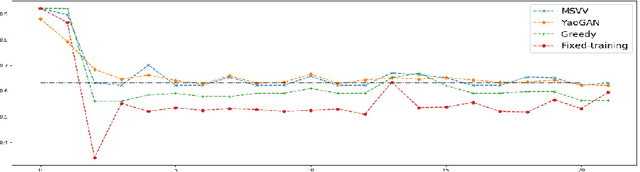
We address the challenge of finding algorithms for online allocation (i.e. bipartite matching) using a machine learning approach. In this paper, we focus on the AdWords problem, which is a classical online budgeted matching problem of both theoretical and practical significance. In contrast to existing work, our goal is to accomplish algorithm design {\em tabula rasa}, i.e., without any human-provided insights or expert-tuned training data beyond specifying the objective and constraints of the optimization problem. We construct a framework based on insights and ideas from game theory, adversarial training and GANs Key to our approach is to generate adversarial examples that expose the weakness of any given algorithm. A unique challenge in our context is to generate complete examples from scratch rather than perturbing given examples and we demonstrate this can be accomplished for the Adwords problem. We use this framework to co-train an algorithm network and an adversarial network against each other until they converge to an equilibrium. This approach finds algorithms and adversarial examples that are consistent with known optimal results. Secondly, we address the question of robustness of the algorithm, namely can we design algorithms that are both strong under practical distributions, as well as exhibit robust performance against adversarial instances. To accomplish this, we train algorithm networks using a mixture of adversarial and practical distributions like power-laws; the resulting networks exhibit a smooth trade-off between the two input regimes.