 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrime the search: Using large language models for guiding geometric task and motion planning by warm-starting tree search
Jun 08, 2025The problem of relocating a set of objects to designated areas amidst movable obstacles can be framed as a Geometric Task and Motion Planning (G-TAMP) problem, a subclass of task and motion planning (TAMP). Traditional approaches to G-TAMP have relied either on domain-independent heuristics or on learning from planning experience to guide the search, both of which typically demand significant computational resources or data. In contrast, humans often use common sense to intuitively decide which objects to manipulate in G-TAMP problems. Inspired by this, we propose leveraging Large Language Models (LLMs), which have common sense knowledge acquired from internet-scale data, to guide task planning in G-TAMP problems. To enable LLMs to perform geometric reasoning, we design a predicate-based prompt that encodes geometric information derived from a motion planning algorithm. We then query the LLM to generate a task plan, which is then used to search for a feasible set of continuous parameters. Since LLMs are prone to mistakes, instead of committing to LLM's outputs, we extend Monte Carlo Tree Search (MCTS) to a hybrid action space and use the LLM to guide the search. Unlike the previous approach that calls an LLM at every node and incurs high computational costs, we use it to warm-start the MCTS with the nodes explored in completing the LLM's task plan. On six different G-TAMP problems, we show our method outperforms previous LLM planners and pure search algorithms. Code can be found at: https://github.com/iMSquared/prime-the-search
* The International Journal of Robotics Research (IJRR)
Hierarchical and Modular Network on Non-prehensile Manipulation in General Environments
Feb 28, 2025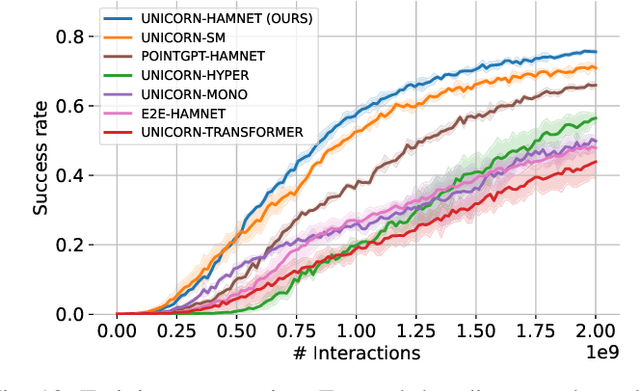
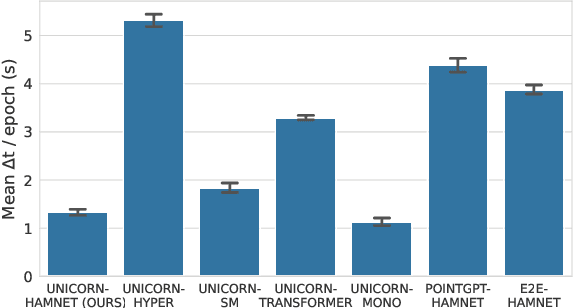
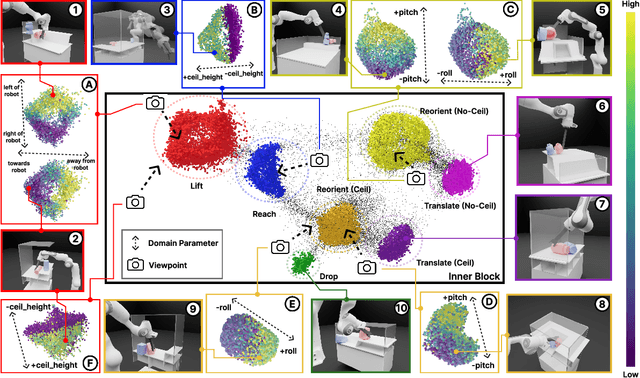
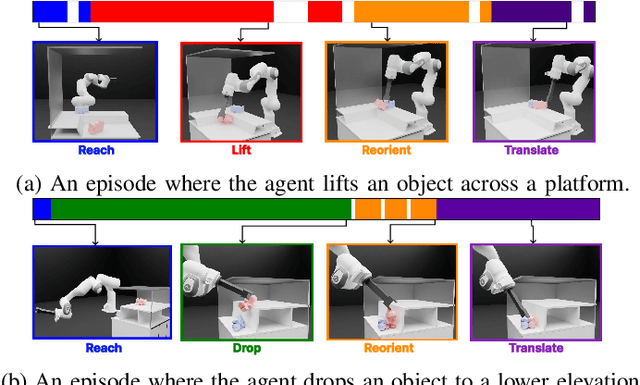
For robots to operate in general environments like households, they must be able to perform non-prehensile manipulation actions such as toppling and rolling to manipulate ungraspable objects. However, prior works on non-prehensile manipulation cannot yet generalize across environments with diverse geometries. The main challenge lies in adapting to varying environmental constraints: within a cabinet, the robot must avoid walls and ceilings; to lift objects to the top of a step, the robot must account for the step's pose and extent. While deep reinforcement learning (RL) has demonstrated impressive success in non-prehensile manipulation, accounting for such variability presents a challenge for the generalist policy, as it must learn diverse strategies for each new combination of constraints. To address this, we propose a modular and reconfigurable architecture that adaptively reconfigures network modules based on task requirements. To capture the geometric variability in environments, we extend the contact-based object representation (CORN) to environment geometries, and propose a procedural algorithm for generating diverse environments to train our agent. Taken together, the resulting policy can zero-shot transfer to novel real-world environments and objects despite training entirely within a simulator. We additionally release a simulation-based benchmark featuring nine digital twins of real-world scenes with 353 objects to facilitate non-prehensile manipulation research in realistic domains.
From planning to policy: distilling $\texttt{Skill-RRT}$ for long-horizon prehensile and non-prehensile manipulation
Feb 26, 2025
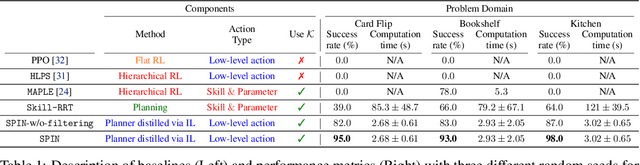
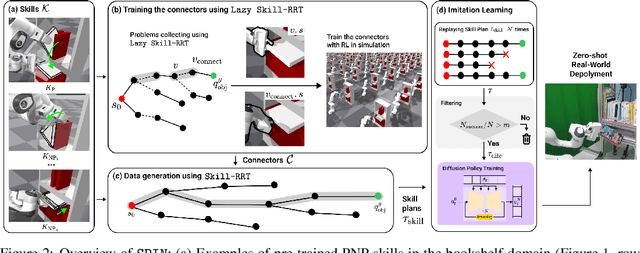
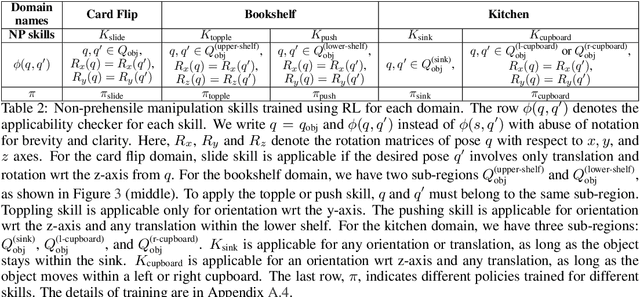
Current robots face challenges in manipulation tasks that require a long sequence of prehensile and non-prehensile skills. This involves handling contact-rich interactions and chaining multiple skills while considering their long-term consequences. This paper presents a framework that leverages imitation learning to distill a planning algorithm, capable of solving long-horizon problems but requiring extensive computation time, into a policy for efficient action inference. We introduce $\texttt{Skill-RRT}$, an extension of the rapidly-exploring random tree (RRT) that incorporates skill applicability checks and intermediate object pose sampling for efficient long-horizon planning. To enable skill chaining, we propose $\textit{connectors}$, goal-conditioned policies that transition between skills while minimizing object disturbance. Using lazy planning, connectors are selectively trained on relevant transitions, reducing the cost of training. High-quality demonstrations are generated with $\texttt{Skill-RRT}$ and refined by a noise-based replay mechanism to ensure robust policy performance. The distilled policy, trained entirely in simulation, zero-shot transfer to the real world, and achieves over 80% success rates across three challenging manipulation tasks. In simulation, our approach outperforms the state-of-the-art skill-based reinforcement learning method, $\texttt{MAPLE}$, and $\texttt{Skill-RRT}$.
Design of a low-cost and lightweight 6 DoF bimanual arm for dynamic and contact-rich manipulation
Feb 24, 2025


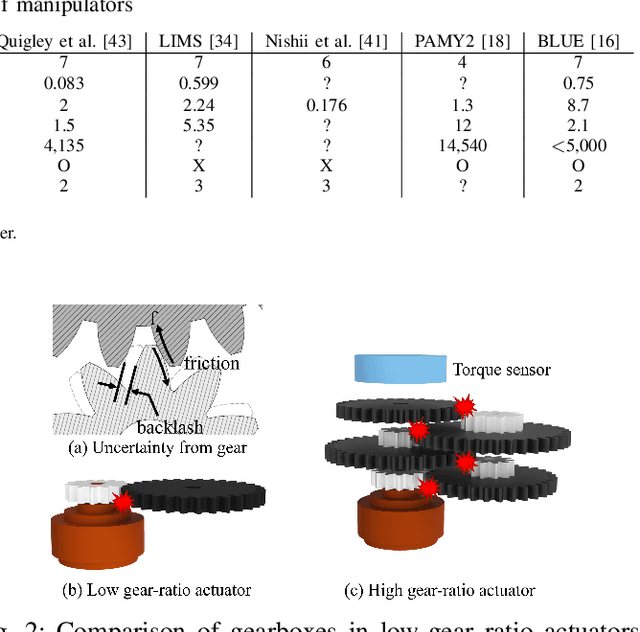
Dynamic and contact-rich object manipulation, such as striking, snatching, or hammering, remains challenging for robotic systems due to hardware limitations. Most existing robots are constrained by high-inertia design, limited compliance, and reliance on expensive torque sensors. To address this, we introduce ARMADA (Affordable Robot for Manipulation and Dynamic Actions), a 6 degrees-of-freedom bimanual robot designed for dynamic manipulation research. ARMADA combines low-inertia, back-drivable actuators with a lightweight design, using readily available components and 3D-printed links for ease of assembly in research labs. The entire system, including both arms, is built for just $6,100. Each arm achieves speeds up to 6.16m/s, almost twice that of most collaborative robots, with a comparable payload of 2.5kg. We demonstrate ARMADA can perform dynamic manipulation like snatching, hammering, and bimanual throwing in real-world environments. We also showcase its effectiveness in reinforcement learning (RL) by training a non-prehensile manipulation policy in simulation and transferring it zero-shot to the real world, as well as human motion shadowing for dynamic bimanual object throwing. ARMADA is fully open-sourced with detailed assembly instructions, CAD models, URDFs, simulation, and learning codes. We highly recommend viewing the supplementary video at https://sites.google.com/view/im2-humanoid-arm.
PRESTO: Fast motion planning using diffusion models based on key-configuration environment representation
Sep 24, 2024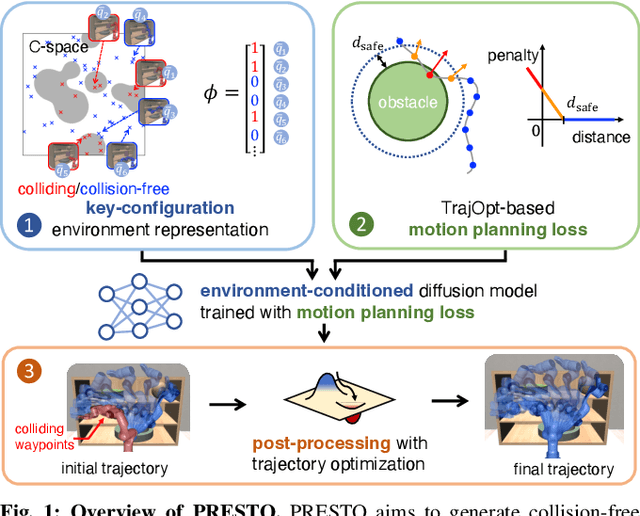
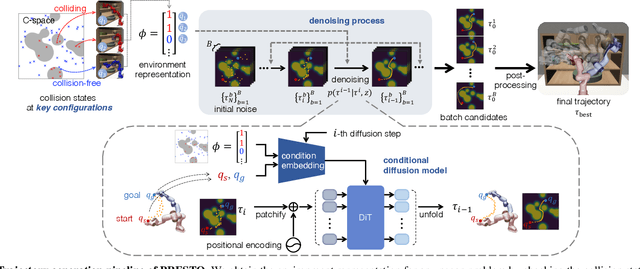
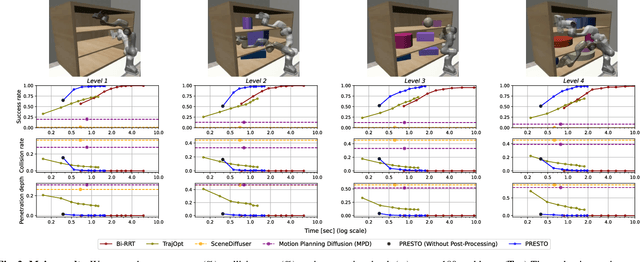
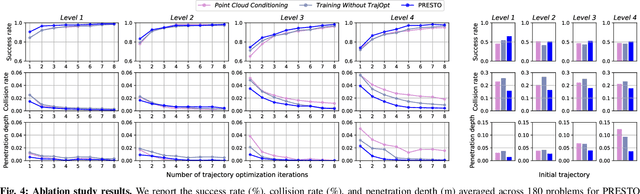
We introduce a learning-guided motion planning framework that provides initial seed trajectories using a diffusion model for trajectory optimization. Given a workspace, our method approximates the configuration space (C-space) obstacles through a key-configuration representation that consists of a sparse set of task-related key configurations, and uses this as an input to the diffusion model. The diffusion model integrates regularization terms that encourage collision avoidance and smooth trajectories during training, and trajectory optimization refines the generated seed trajectories to further correct any colliding segments. Our experimental results demonstrate that using high-quality trajectory priors, learned through our C-space-grounded diffusion model, enables efficient generation of collision-free trajectories in narrow-passage environments, outperforming prior learning- and planning-based baselines. Videos and additional materials can be found on the project page: https://kiwi-sherbet.github.io/PRESTO.
DEF-oriCORN: efficient 3D scene understanding for robust language-directed manipulation without demonstrations
Jul 31, 2024

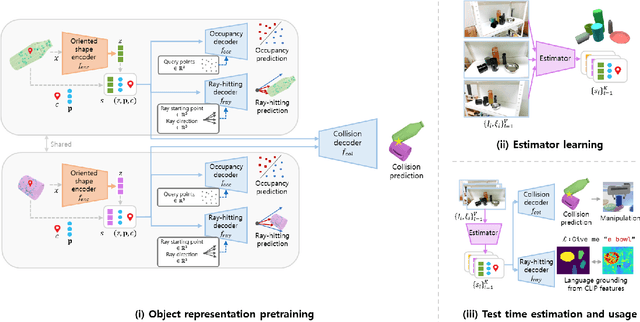

We present DEF-oriCORN, a framework for language-directed manipulation tasks. By leveraging a novel object-based scene representation and diffusion-model-based state estimation algorithm, our framework enables efficient and robust manipulation planning in response to verbal commands, even in tightly packed environments with sparse camera views without any demonstrations. Unlike traditional representations, our representation affords efficient collision checking and language grounding. Compared to state-of-the-art baselines, our framework achieves superior estimation and motion planning performance from sparse RGB images and zero-shot generalizes to real-world scenarios with diverse materials, including transparent and reflective objects, despite being trained exclusively in simulation. Our code for data generation, training, inference, and pre-trained weights are publicly available at: https://sites.google.com/view/def-oricorn/home.
CORN: Contact-based Object Representation for Nonprehensile Manipulation of General Unseen Objects
Mar 16, 2024



Nonprehensile manipulation is essential for manipulating objects that are too thin, large, or otherwise ungraspable in the wild. To sidestep the difficulty of contact modeling in conventional modeling-based approaches, reinforcement learning (RL) has recently emerged as a promising alternative. However, previous RL approaches either lack the ability to generalize over diverse object shapes, or use simple action primitives that limit the diversity of robot motions. Furthermore, using RL over diverse object geometry is challenging due to the high cost of training a policy that takes in high-dimensional sensory inputs. We propose a novel contact-based object representation and pretraining pipeline to tackle this. To enable massively parallel training, we leverage a lightweight patch-based transformer architecture for our encoder that processes point clouds, thus scaling our training across thousands of environments. Compared to learning from scratch, or other shape representation baselines, our representation facilitates both time- and data-efficient learning. We validate the efficacy of our overall system by zero-shot transferring the trained policy to novel real-world objects. Code and videos are available at https://sites.google.com/view/contact-non-prehensile.
Transformable Gaussian Reward Function for Socially-Aware Navigation with Deep Reinforcement Learning
Feb 22, 2024
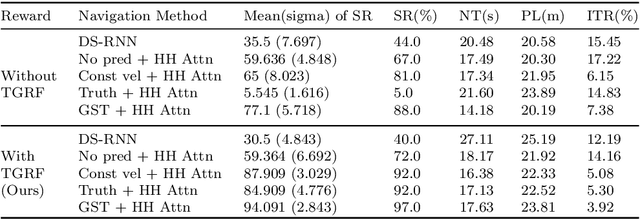
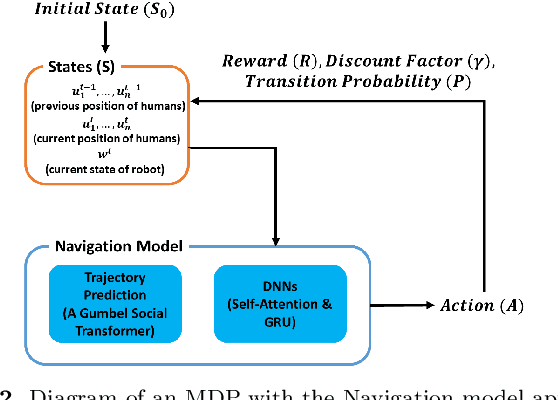
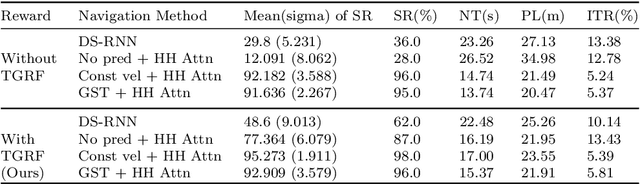
Robot navigation has transitioned from prioritizing obstacle avoidance to adopting socially aware navigation strategies that accommodate human presence. As a result, the recognition of socially aware navigation within dynamic human-centric environments has gained prominence in the field of robotics. Although reinforcement learning technique has fostered the advancement of socially aware navigation, defining appropriate reward functions, especially in congested environments, has posed a significant challenge. These rewards, crucial in guiding robot actions, demand intricate human-crafted design due to their complex nature and inability to be automatically set. The multitude of manually designed rewards poses issues with hyperparameter redundancy, imbalance, and inadequate representation of unique object characteristics. To address these challenges, we introduce a transformable gaussian reward function (TGRF). The TGRF significantly reduces the burden of hyperparameter tuning, displays adaptability across various reward functions, and demonstrates accelerated learning rates, particularly excelling in crowded environments utilizing deep reinforcement learning (DRL). We introduce and validate TGRF through sections highlighting its conceptual background, characteristics, experiments, and real-world application, paving the way for a more effective and adaptable approach in robotics.The complete source code is available on https://github.com/JinnnK/TGRF
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Learning Whole-body Manipulation for Quadrupedal Robot
Sep 06, 2023



We propose a learning-based system for enabling quadrupedal robots to manipulate large, heavy objects using their whole body. Our system is based on a hierarchical control strategy that uses the deep latent variable embedding which captures manipulation-relevant information from interactions, proprioception, and action history, allowing the robot to implicitly understand object properties. We evaluate our framework in both simulation and real-world scenarios. In the simulation, it achieves a success rate of 93.6 % in accurately re-positioning and re-orienting various objects within a tolerance of 0.03 m and 5 {\deg}. Real-world experiments demonstrate the successful manipulation of objects such as a 19.2 kg water-filled drum and a 15.3 kg plastic box filled with heavy objects while the robot weighs 27 kg. Unlike previous works that focus on manipulating small and light objects using prehensile manipulation, our framework illustrates the possibility of using quadrupeds for manipulating large and heavy objects that are ungraspable with the robot's entire body. Our method does not require explicit object modeling and offers significant computational efficiency compared to optimization-based methods. The video can be found at https://youtu.be/fO_PVr27QxU.