 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBelief Aided Navigation using Bayesian Reinforcement Learning for Avoiding Humans in Blind Spots
Mar 15, 2024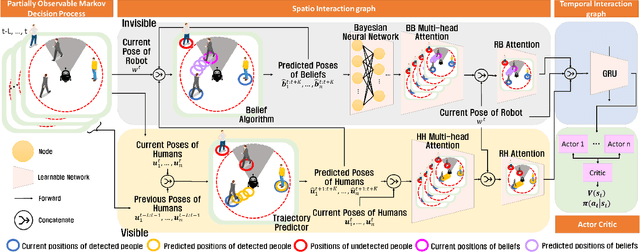
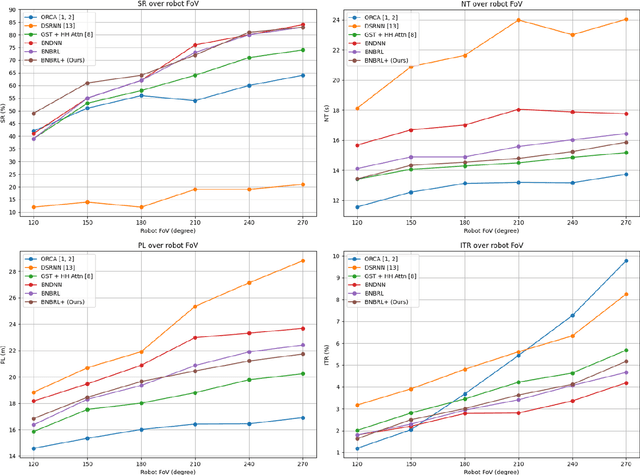
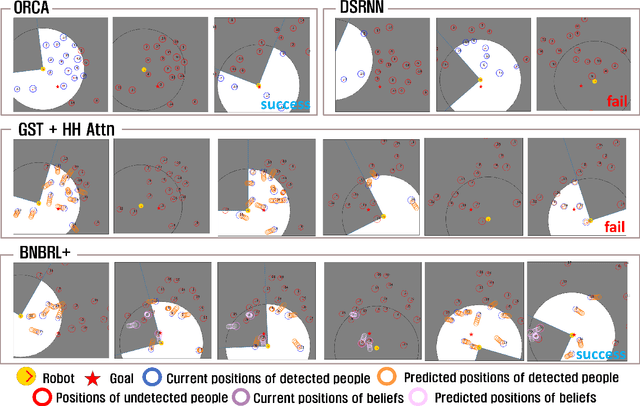
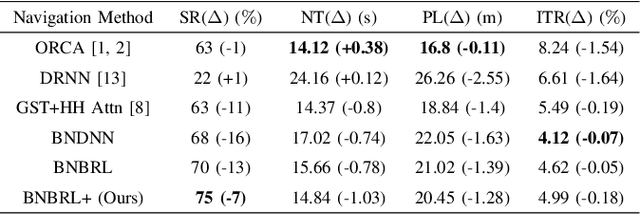
Recent research on mobile robot navigation has focused on socially aware navigation in crowded environments. However, existing methods do not adequately account for human robot interactions and demand accurate location information from omnidirectional sensors, rendering them unsuitable for practical applications. In response to this need, this study introduces a novel algorithm, BNBRL+, predicated on the partially observable Markov decision process framework to assess risks in unobservable areas and formulate movement strategies under uncertainty. BNBRL+ consolidates belief algorithms with Bayesian neural networks to probabilistically infer beliefs based on the positional data of humans. It further integrates the dynamics between the robot, humans, and inferred beliefs to determine the navigation paths and embeds social norms within the reward function, thereby facilitating socially aware navigation. Through experiments in various risk laden scenarios, this study validates the effectiveness of BNBRL+ in navigating crowded environments with blind spots. The model's ability to navigate effectively in spaces with limited visibility and avoid obstacles dynamically can significantly improve the safety and reliability of autonomous vehicles.
Transformable Gaussian Reward Function for Socially-Aware Navigation with Deep Reinforcement Learning
Feb 22, 2024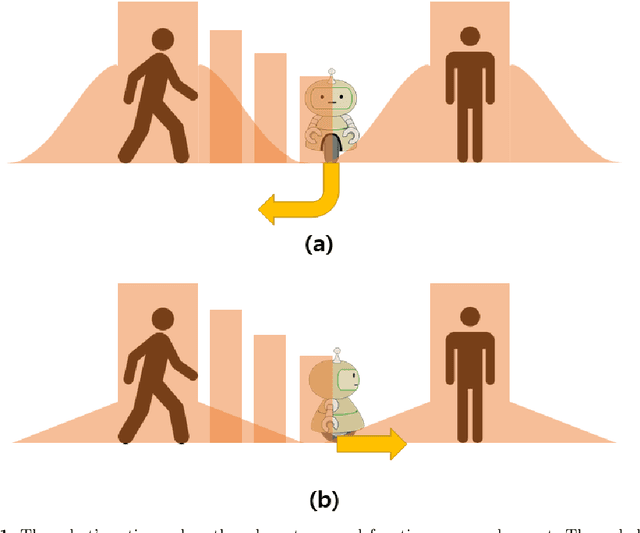
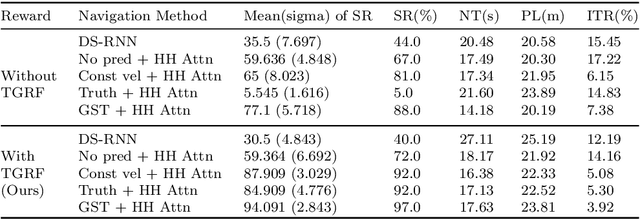
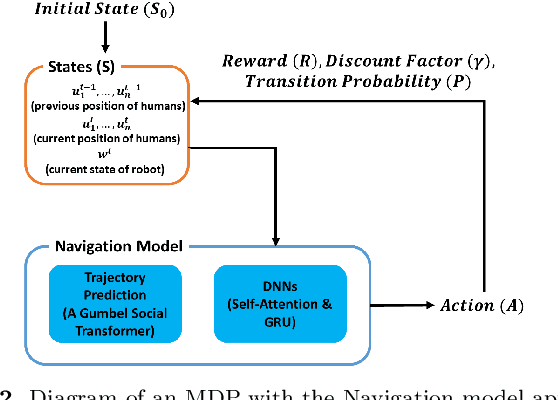
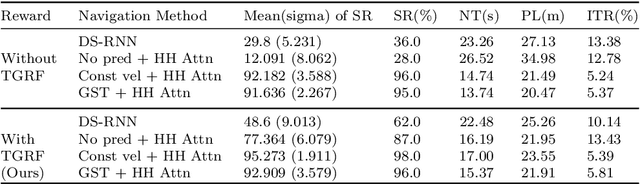
Robot navigation has transitioned from prioritizing obstacle avoidance to adopting socially aware navigation strategies that accommodate human presence. As a result, the recognition of socially aware navigation within dynamic human-centric environments has gained prominence in the field of robotics. Although reinforcement learning technique has fostered the advancement of socially aware navigation, defining appropriate reward functions, especially in congested environments, has posed a significant challenge. These rewards, crucial in guiding robot actions, demand intricate human-crafted design due to their complex nature and inability to be automatically set. The multitude of manually designed rewards poses issues with hyperparameter redundancy, imbalance, and inadequate representation of unique object characteristics. To address these challenges, we introduce a transformable gaussian reward function (TGRF). The TGRF significantly reduces the burden of hyperparameter tuning, displays adaptability across various reward functions, and demonstrates accelerated learning rates, particularly excelling in crowded environments utilizing deep reinforcement learning (DRL). We introduce and validate TGRF through sections highlighting its conceptual background, characteristics, experiments, and real-world application, paving the way for a more effective and adaptable approach in robotics.The complete source code is available on https://github.com/JinnnK/TGRF