 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom planning to policy: distilling $\texttt{Skill-RRT}$ for long-horizon prehensile and non-prehensile manipulation
Feb 26, 2025
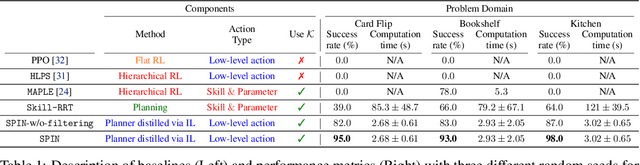
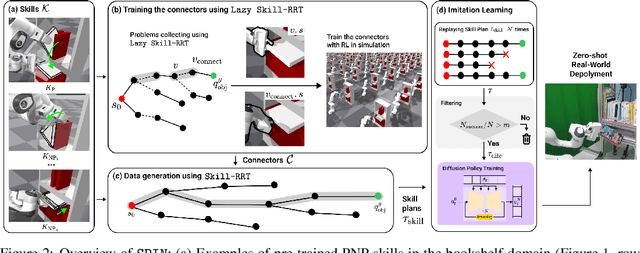
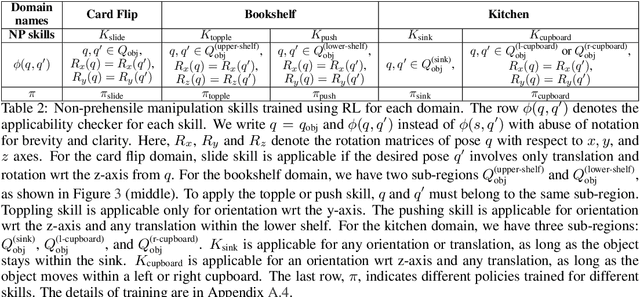
Current robots face challenges in manipulation tasks that require a long sequence of prehensile and non-prehensile skills. This involves handling contact-rich interactions and chaining multiple skills while considering their long-term consequences. This paper presents a framework that leverages imitation learning to distill a planning algorithm, capable of solving long-horizon problems but requiring extensive computation time, into a policy for efficient action inference. We introduce $\texttt{Skill-RRT}$, an extension of the rapidly-exploring random tree (RRT) that incorporates skill applicability checks and intermediate object pose sampling for efficient long-horizon planning. To enable skill chaining, we propose $\textit{connectors}$, goal-conditioned policies that transition between skills while minimizing object disturbance. Using lazy planning, connectors are selectively trained on relevant transitions, reducing the cost of training. High-quality demonstrations are generated with $\texttt{Skill-RRT}$ and refined by a noise-based replay mechanism to ensure robust policy performance. The distilled policy, trained entirely in simulation, zero-shot transfer to the real world, and achieves over 80% success rates across three challenging manipulation tasks. In simulation, our approach outperforms the state-of-the-art skill-based reinforcement learning method, $\texttt{MAPLE}$, and $\texttt{Skill-RRT}$.