 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEF-oriCORN: efficient 3D scene understanding for robust language-directed manipulation without demonstrations
Paper and Code
Jul 31, 2024

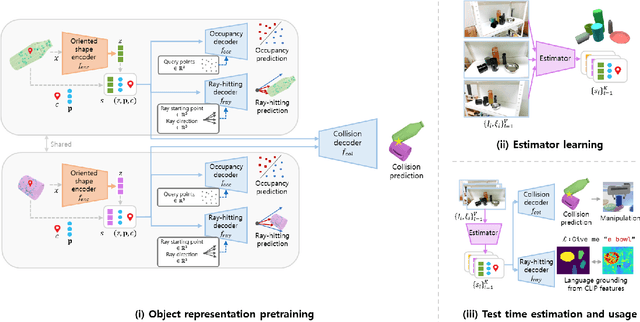

We present DEF-oriCORN, a framework for language-directed manipulation tasks. By leveraging a novel object-based scene representation and diffusion-model-based state estimation algorithm, our framework enables efficient and robust manipulation planning in response to verbal commands, even in tightly packed environments with sparse camera views without any demonstrations. Unlike traditional representations, our representation affords efficient collision checking and language grounding. Compared to state-of-the-art baselines, our framework achieves superior estimation and motion planning performance from sparse RGB images and zero-shot generalizes to real-world scenarios with diverse materials, including transparent and reflective objects, despite being trained exclusively in simulation. Our code for data generation, training, inference, and pre-trained weights are publicly available at: https://sites.google.com/view/def-oricorn/home.