 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAVER: Curious Audiovisual Exploring Robot
Nov 10, 2025Multimodal audiovisual perception can enable new avenues for robotic manipulation, from better material classification to the imitation of demonstrations for which only audio signals are available (e.g., playing a tune by ear). However, to unlock such multimodal potential, robots need to learn the correlations between an object's visual appearance and the sound it generates when they interact with it. Such an active sensorimotor experience requires new interaction capabilities, representations, and exploration methods to guide the robot in efficiently building increasingly rich audiovisual knowledge. In this work, we present CAVER, a novel robot that builds and utilizes rich audiovisual representations of objects. CAVER includes three novel contributions: 1) a novel 3D printed end-effector, attachable to parallel grippers, that excites objects' audio responses, 2) an audiovisual representation that combines local and global appearance information with sound features, and 3) an exploration algorithm that uses and builds the audiovisual representation in a curiosity-driven manner that prioritizes interacting with high uncertainty objects to obtain good coverage of surprising audio with fewer interactions. We demonstrate that CAVER builds rich representations in different scenarios more efficiently than several exploration baselines, and that the learned audiovisual representation leads to significant improvements in material classification and the imitation of audio-only human demonstrations. https://caver-bot.github.io/
Learning to Look: Seeking Information for Decision Making via Policy Factorization
Oct 24, 2024



Many robot manipulation tasks require active or interactive exploration behavior in order to be performed successfully. Such tasks are ubiquitous in embodied domains, where agents must actively search for the information necessary for each stage of a task, e.g., moving the head of the robot to find information relevant to manipulation, or in multi-robot domains, where one scout robot may search for the information that another robot needs to make informed decisions. We identify these tasks with a new type of problem, factorized Contextual Markov Decision Processes, and propose DISaM, a dual-policy solution composed of an information-seeking policy that explores the environment to find the relevant contextual information and an information-receiving policy that exploits the context to achieve the manipulation goal. This factorization allows us to train both policies separately, using the information-receiving one to provide reward to train the information-seeking policy. At test time, the dual agent balances exploration and exploitation based on the uncertainty the manipulation policy has on what the next best action is. We demonstrate the capabilities of our dual policy solution in five manipulation tasks that require information-seeking behaviors, both in simulation and in the real-world, where DISaM significantly outperforms existing methods. More information at https://robin-lab.cs.utexas.edu/learning2look/.
Skill Generalization with Verbs
Oct 18, 2024



It is imperative that robots can understand natural language commands issued by humans. Such commands typically contain verbs that signify what action should be performed on a given object and that are applicable to many objects. We propose a method for generalizing manipulation skills to novel objects using verbs. Our method learns a probabilistic classifier that determines whether a given object trajectory can be described by a specific verb. We show that this classifier accurately generalizes to novel object categories with an average accuracy of 76.69% across 13 object categories and 14 verbs. We then perform policy search over the object kinematics to find an object trajectory that maximizes classifier prediction for a given verb. Our method allows a robot to generate a trajectory for a novel object based on a verb, which can then be used as input to a motion planner. We show that our model can generate trajectories that are usable for executing five verb commands applied to novel instances of two different object categories on a real robot.
KinScene: Model-Based Mobile Manipulation of Articulated Scenes
Sep 24, 2024
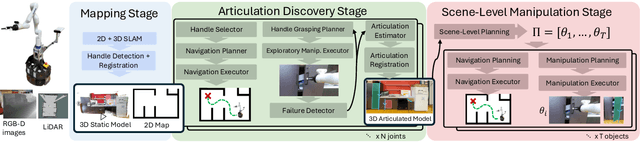
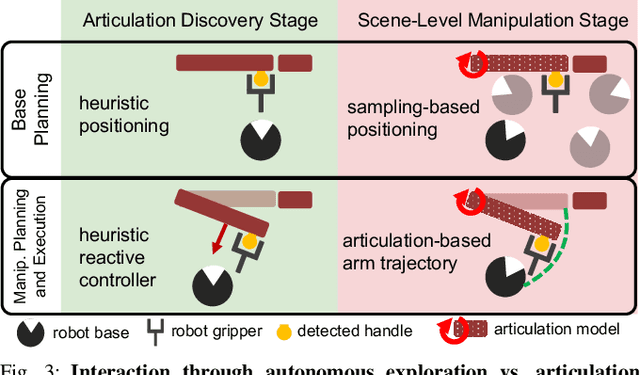

Sequentially interacting with articulated objects is crucial for a mobile manipulator to operate effectively in everyday environments. To enable long-horizon tasks involving articulated objects, this study explores building scene-level articulation models for indoor scenes through autonomous exploration. While previous research has studied mobile manipulation with articulated objects by considering object kinematic constraints, it primarily focuses on individual-object scenarios and lacks extension to a scene-level context for task-level planning. To manipulate multiple object parts sequentially, the robot needs to reason about the resultant motion of each part and anticipate its impact on future actions.We introduce \ourtool{}, a full-stack approach for long-horizon manipulation tasks with articulated objects. The robot maps the scene, detects and physically interacts with articulated objects, collects observations, and infers the articulation properties. For sequential tasks, the robot plans a feasible series of object interactions based on the inferred articulation model. We demonstrate that our approach repeatably constructs accurate scene-level kinematic and geometric models, enabling long-horizon mobile manipulation in a real-world scene. Code and additional results are available at https://chengchunhsu.github.io/KinScene/
Deep Reinforcement Learning for Robotics: A Survey of Real-World Successes
Aug 07, 2024Reinforcement learning (RL), particularly its combination with deep neural networks referred to as deep RL (DRL), has shown tremendous promise across a wide range of applications, suggesting its potential for enabling the development of sophisticated robotic behaviors. Robotics problems, however, pose fundamental difficulties for the application of RL, stemming from the complexity and cost of interacting with the physical world. This article provides a modern survey of DRL for robotics, with a particular focus on evaluating the real-world successes achieved with DRL in realizing several key robotic competencies. Our analysis aims to identify the key factors underlying those exciting successes, reveal underexplored areas, and provide an overall characterization of the status of DRL in robotics. We highlight several important avenues for future work, emphasizing the need for stable and sample-efficient real-world RL paradigms, holistic approaches for discovering and integrating various competencies to tackle complex long-horizon, open-world tasks, and principled development and evaluation procedures. This survey is designed to offer insights for both RL practitioners and roboticists toward harnessing RL's power to create generally capable real-world robotic systems.
ScrewMimic: Bimanual Imitation from Human Videos with Screw Space Projection
May 06, 2024Bimanual manipulation is a longstanding challenge in robotics due to the large number of degrees of freedom and the strict spatial and temporal synchronization required to generate meaningful behavior. Humans learn bimanual manipulation skills by watching other humans and by refining their abilities through play. In this work, we aim to enable robots to learn bimanual manipulation behaviors from human video demonstrations and fine-tune them through interaction. Inspired by seminal work in psychology and biomechanics, we propose modeling the interaction between two hands as a serial kinematic linkage -- as a screw motion, in particular, that we use to define a new action space for bimanual manipulation: screw actions. We introduce ScrewMimic, a framework that leverages this novel action representation to facilitate learning from human demonstration and self-supervised policy fine-tuning. Our experiments demonstrate that ScrewMimic is able to learn several complex bimanual behaviors from a single human video demonstration, and that it outperforms baselines that interpret demonstrations and fine-tune directly in the original space of motion of both arms. For more information and video results, https://robin-lab.cs.utexas.edu/ScrewMimic/
TeleMoMa: A Modular and Versatile Teleoperation System for Mobile Manipulation
Mar 12, 2024



A critical bottleneck limiting imitation learning in robotics is the lack of data. This problem is more severe in mobile manipulation, where collecting demonstrations is harder than in stationary manipulation due to the lack of available and easy-to-use teleoperation interfaces. In this work, we demonstrate TeleMoMa, a general and modular interface for whole-body teleoperation of mobile manipulators. TeleMoMa unifies multiple human interfaces including RGB and depth cameras, virtual reality controllers, keyboard, joysticks, etc., and any combination thereof. In its more accessible version, TeleMoMa works using simply vision (e.g., an RGB-D camera), lowering the entry bar for humans to provide mobile manipulation demonstrations. We demonstrate the versatility of TeleMoMa by teleoperating several existing mobile manipulators - PAL Tiago++, Toyota HSR, and Fetch - in simulation and the real world. We demonstrate the quality of the demonstrations collected with TeleMoMa by training imitation learning policies for mobile manipulation tasks involving synchronized whole-body motion. Finally, we also show that TeleMoMa's teleoperation channel enables teleoperation on site, looking at the robot, or remote, sending commands and observations through a computer network, and perform user studies to evaluate how easy it is for novice users to learn to collect demonstrations with different combinations of human interfaces enabled by our system. We hope TeleMoMa becomes a helpful tool for the community enabling researchers to collect whole-body mobile manipulation demonstrations. For more information and video results, https://robin-lab.cs.utexas.edu/telemoma-web.
Learning to Infer Kinematic Hierarchies for Novel Object Instances
Oct 15, 2021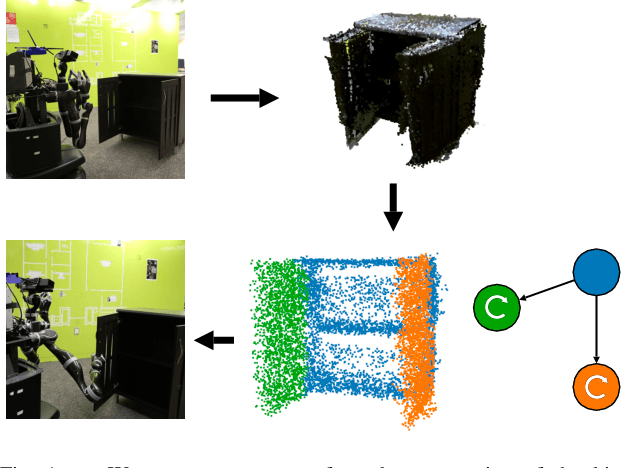
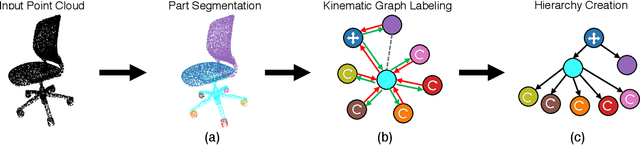
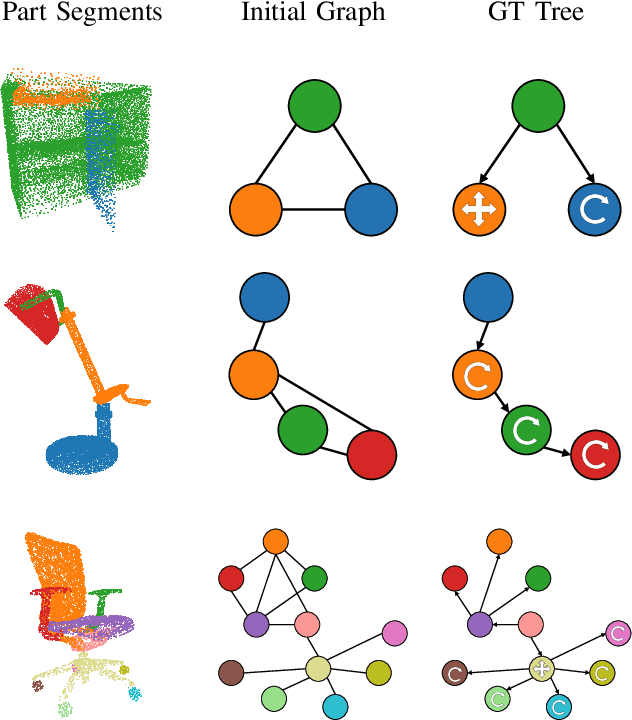
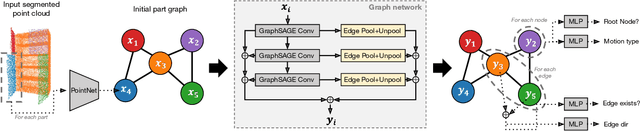
Manipulating an articulated object requires perceiving itskinematic hierarchy: its parts, how each can move, and howthose motions are coupled. Previous work has explored per-ception for kinematics, but none infers a complete kinematichierarchy on never-before-seen object instances, without relyingon a schema or template. We present a novel perception systemthat achieves this goal. Our system infers the moving parts ofan object and the kinematic couplings that relate them. Toinfer parts, it uses a point cloud instance segmentation neuralnetwork and to infer kinematic hierarchies, it uses a graphneural network to predict the existence, direction, and typeof edges (i.e. joints) that relate the inferred parts. We trainthese networks using simulated scans of synthetic 3D models.We evaluate our system on simulated scans of 3D objects, andwe demonstrate a proof-of-concept use of our system to drivereal-world robotic manipulation.
RMPs for Safe Impedance Control in Contact-Rich Manipulation
Sep 24, 2021
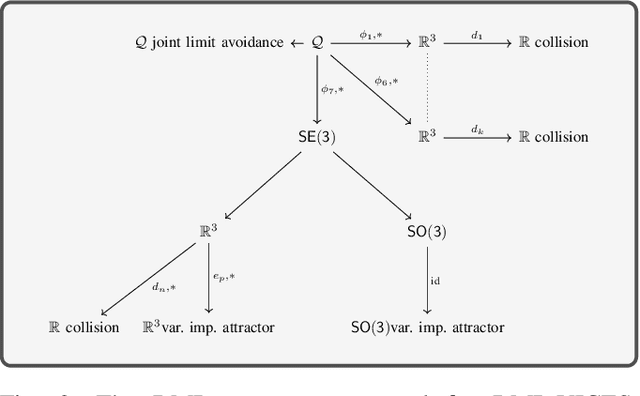

Variable impedance control in operation-space is a promising approach to learning contact-rich manipulation behaviors. One of the main challenges with this approach is producing a manipulation behavior that ensures the safety of the arm and the environment. Such behavior is typically implemented via a reward function that penalizes unsafe actions (e.g. obstacle collision, joint limit extension), but that approach is not always effective and does not result in behaviors that can be reused in slightly different environments. We show how to combine Riemannian Motion Policies, a class of policies that dynamically generate motion in the presence of safety and collision constraints, with variable impedance operation-space control to learn safer contact-rich manipulation behaviors.
Bootstrapping Motor Skill Learning with Motion Planning
Jan 12, 2021


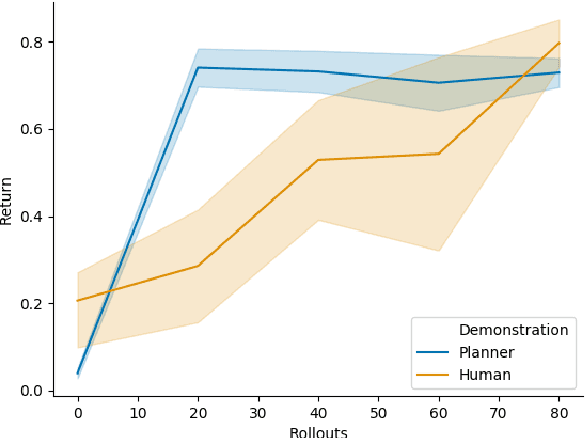
Learning a robot motor skill from scratch is impractically slow; so much so that in practice, learning must be bootstrapped using a good skill policy obtained from human demonstration. However, relying on human demonstration necessarily degrades the autonomy of robots that must learn a wide variety of skills over their operational lifetimes. We propose using kinematic motion planning as a completely autonomous, sample efficient way to bootstrap motor skill learning for object manipulation. We demonstrate the use of motion planners to bootstrap motor skills in two complex object manipulation scenarios with different policy representations: opening a drawer with a dynamic movement primitive representation, and closing a microwave door with a deep neural network policy. We also show how our method can bootstrap a motor skill for the challenging dynamic task of learning to hit a ball off a tee, where a kinematic plan based on treating the scene as static is insufficient to solve the task, but sufficient to bootstrap a more dynamic policy. In all three cases, our method is competitive with human-demonstrated initialization, and significantly outperforms starting with a random policy. This approach enables robots to to efficiently and autonomously learn motor policies for dynamic tasks without human demonstration.