 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Theory of Mind Enables the Invention of Writing Systems
Feb 04, 2025Abstract symbolic writing systems are semiotic codes that are ubiquitous in modern society but are otherwise absent in the animal kingdom. Anthropological evidence suggests that the earliest forms of some writing systems originally consisted of iconic pictographs, which signify their referent via visual resemblance. While previous studies have examined the emergence and, separately, the evolution of pictographic writing systems through a computational lens, most employ non-naturalistic methodologies that make it difficult to draw clear analogies to human and animal cognition. We develop a multi-agent reinforcement learning testbed for emergent communication called a Signification Game, and formulate a model of inferential communication that enables agents to leverage visual theory of mind to communicate actions using pictographs. Our model, which is situated within a broader formalism for animal communication, sheds light on the cognitive and cultural processes that led to the development of early writing systems.
Skill Generalization with Verbs
Oct 18, 2024



It is imperative that robots can understand natural language commands issued by humans. Such commands typically contain verbs that signify what action should be performed on a given object and that are applicable to many objects. We propose a method for generalizing manipulation skills to novel objects using verbs. Our method learns a probabilistic classifier that determines whether a given object trajectory can be described by a specific verb. We show that this classifier accurately generalizes to novel object categories with an average accuracy of 76.69% across 13 object categories and 14 verbs. We then perform policy search over the object kinematics to find an object trajectory that maximizes classifier prediction for a given verb. Our method allows a robot to generate a trajectory for a novel object based on a verb, which can then be used as input to a motion planner. We show that our model can generate trajectories that are usable for executing five verb commands applied to novel instances of two different object categories on a real robot.
RLang: A Declarative Language for Expression Prior Knowledge for Reinforcement Learning
Aug 16, 2022

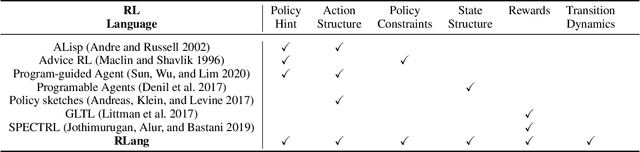
Communicating useful background knowledge to reinforcement learning (RL) agents is an important and effective method for accelerating learning. We introduce RLang, a domain-specific language (DSL) for communicating domain knowledge to an RL agent. Unlike other existing DSLs proposed by the RL community that ground to single elements of a decision-making formalism (e.g., the reward function or policy function), RLang can specify information about every element of a Markov decision process. We define precise syntax and grounding semantics for RLang, and provide a parser implementation that grounds RLang programs to an algorithm-agnostic partial world model and policy that can be exploited by an RL agent. We provide a series of example RLang programs, and demonstrate how different RL methods can exploit the resulting knowledge, including model-free and model-based tabular algorithms, hierarchical approaches, and deep RL algorithms (including both policy gradient and value-based methods).
Guided Policy Search for Parameterized Skills using Adverbs
Oct 23, 2021
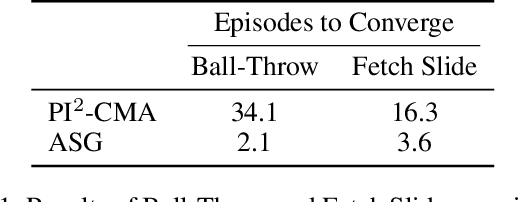
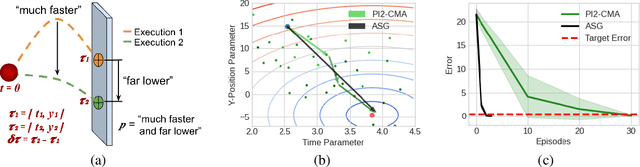
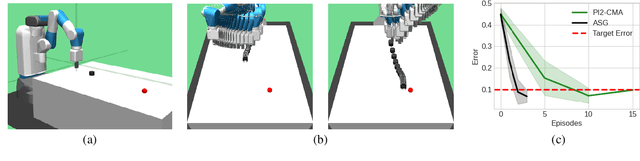
We present a method for using adverb phrases to adjust skill parameters via learned adverb-skill groundings. These groundings allow an agent to use adverb feedback provided by a human to directly update a skill policy, in a manner similar to traditional local policy search methods. We show that our method can be used as a drop-in replacement for these policy search methods when dense reward from the environment is not available but human language feedback is. We demonstrate improved sample efficiency over modern policy search methods in two experiments.
MK-SQuIT: Synthesizing Questions using Iterative Template-filling
Nov 04, 2020
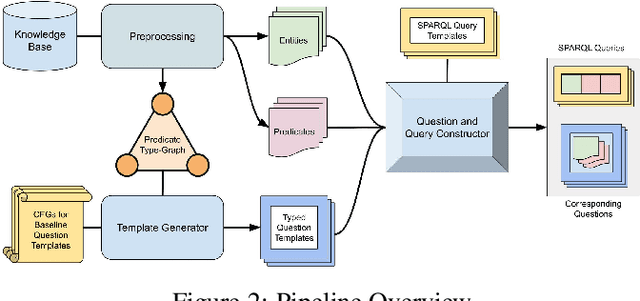


The aim of this work is to create a framework for synthetically generating question/query pairs with as little human input as possible. These datasets can be used to train machine translation systems to convert natural language questions into queries, a useful tool that could allow for more natural access to database information. Existing methods of dataset generation require human input that scales linearly with the size of the dataset, resulting in small datasets. Aside from a short initial configuration task, no human input is required during the query generation process of our system. We leverage WikiData, a knowledge base of RDF triples, as a source for generating the main content of questions and queries. Using multiple layers of question templating we are able to sidestep some of the most challenging parts of query generation that have been handled by humans in previous methods; humans never have to modify, aggregate, inspect, annotate, or generate any questions or queries at any step in the process. Our system is easily configurable to multiple domains and can be modified to generate queries in natural languages other than English. We also present an example dataset of 110,000 question/query pairs across four WikiData domains. We then present a baseline model that we train using the dataset which shows promise in a commercial QA setting.